A frequent topic of conversation on Twitter, particularly if you follow a number of Microsoft employees, is why isn’t .NET used more or talked about more. The latest round of this I saw was in connection with microserviecs – “where’s all the chat about .NET Core microservices”. There’s often a degree of surprise, frustration and curiosity expressed that people outside of the existing .NET audience aren’t looking at .NET Core – or at least seemingly not in large numbers (I’m sure someone can pull out a statistic suggseting otherwise, and someone else pull out a statistic suggesting it is the case).
One indicator of usage is the TIOBE index which is focused on langauge. VB and C# currently rank 5 and 6 in terms of popularity with their history shown below:
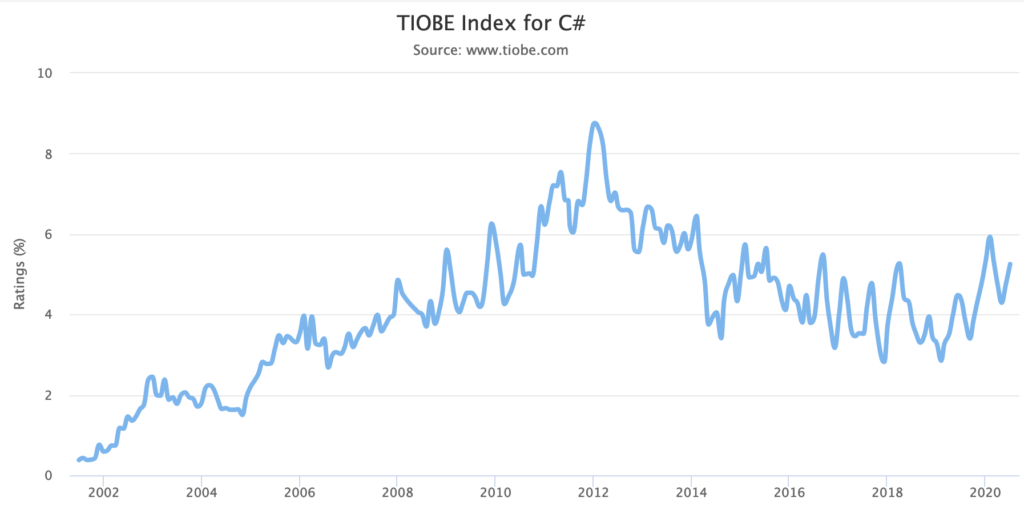
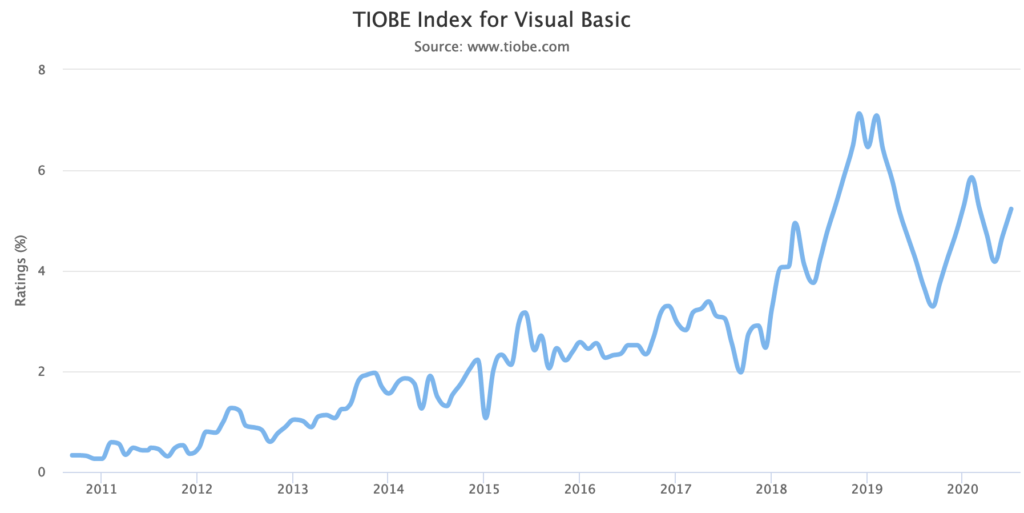
Based on this .NET is certainly a successful runtime and you could argue that the release of .NET Core in 2016 (announced in 2014 with a lengthy preview period) halted what looked to be a significant declince in C# usage – I would assume due to the lack of cross-platform and growing popularity of the cloud.
But since then C# has pretty much flatlined – maybe trending up slightly (the peaks and troughs seem to be going up over the last year). VB… I know far less about the VB world an what could have caused that spike. I’m assuming it has little to do with .NET Core given the limitations of running on the platform.
I find myself in an interesting position with regard to topics like this – I’ve been using .NET for a long time (since the very first beta), its the ecosystem I’m most familiar with, and in general I’m fairly happy with it. On the other hand I now work as a CTO managing teams with a variety of tech stacks (.NET, Node / React, and PHP for the most part) and when looking at new build projects wrangle with what to build it in.
And you know what? There is very little about .NET (Core or otherwise) that stands out.
That it is now cross-platform is great and opens it up to use cases and developers for which it would otherwise be a no-go (myself included these days) but that’s a catch-up play by Microsoft not a unique feature. And the majority of developers who are not on Windows have already spent significant time getting productive in other runtimes and ecosystems – to trade that away and incur a productivity debt there has to be something to offset that debt.
Now being able to write end to end browser through to backend C# (and I’ll swing back to C# later) with Blazor looks compelling but you can do this with just about any language and runtime now through the wizardry of transpilers. Sure Blazor targets WASM and that has some advantages – but also has a boat load of disadvantages: it can be a big download and is an isolated ecosystem. And it can suffer from some of the same quirks transpilers do – in my, brief, time with it I ran into over eager IL stripping issues that were obtuse to say the least. The advantage of the approaches taken by things like Fable (F#), Reason (OCaml), and even Bridge (C#) is that it lets you continue to use the ecosystem you know. For example I was easily able to move to using F# on the front end with Fable and take my React knowledge with me. I can’t do that with Blazor. Why not use Bridge? Well then you’re back to the kind of issue sometimes levelled at Fable – reliance on a small band of OSS contributors on a fringe project. To be fair to Blazor – it seems fairly clearly targeted at the .NET hardcore and those who have not yet (and there can be many good reasons not to) stepped out of the pure Microsoft world.
Microsoft’s great tooling for .NET is often mentioned and I agree – its excellent. If you’re on Windows. JetBrains do have Rider as an excellent cross platform option but there are third party solutions for many languages and runtime. So again, from a Microsoft point of view, we’re back to the existing .NET audience.
.NET Core is fast right? So does that make it compelling? Its certainly a bonus and could be a swing factor if you’re pushing large volumes of transactions or crunching lots of data but for many applications and systems performance blocks are IO and architecture related. There’s a lot of room in that space before hitting runtime issues. But yes – I think .NET Core does offer some advantage in this space though its not the fastest thing out there if you care about benchmarks. Its worth noting it also doesn’t play well in serverless environments – its a poor performer on both AWS and Azure when it comes to coldstarts.
C# is a language I’ve used a lot over the last (nearly) 20 years and I’ve enjoyed my time with it. Its evolved over that period which has been mostly great but its starting to feel like a complicated and strange beast. Many of the changes have been fantastic: generics, expressions and lambdas to name but a few but it increasingly feels like its trying to be all things to all people as it shoehorns in further functional programming features and resulting in something with no (to me at least) obvious path of least resistance. It also tends to come with a significant amount of typing and ceremony – this doesn’t have to be the case and there have been some attempts to demonstrate this but again the path of least resistance is fairly confused.
Finally how about the “Microsoft problem”? What do I mean by this – a generation or two of developers, particularly outside of the enterprise space, have been (to put it politely) reluctant to use Microsoft technologies due to Microsofts behaviour in the 90s and early 2000s – the abuse of their Windows monopoly, attitude to the web, embrace extend extinguish, and hostility to open source all contributed to this. However there is plenty of evidence to suggest this is at least diminishing as a factor – look at the popularity of Visual Studio Code and TypeScript. Both widely adopted and in the kind of scenarios where Microsoft would have been anathema just a few years ago. The difference, to me, is that they don’t require you to throw anything away and offer signficant clear advantages: you can add TypeScript to an existing JS solution and quite quickly begin to leverage better tooling, fewer required unit tests, more readable code and you don’t need a team of developers to upend their world. Good luck doing the same with Blazor!
The choice of a language, runtime and architecture is rarely simple and if you’ve previous experience or existing teams is going to be as much about the past as it is the future – what do people know, what do they like, what are they familiar with. Change has to have a demonstratable benefit and .NETs problem is its just not bringing anything compelling to the table for those not already in its sphere and its not providing an easy route in.
My expectation is it continues to bubble along with its current share and its current audience. I think .NET Core was important to arrest a fall – the lack of cross-platform was seriously hurting it .NET – but its not going to drive any significant growth or change. My advice to any folk working on .NET at Microsoft: if you’re serious about pushing out of the bubble then look at your successes elsewhere (TypeScript and Code) and give people a way to bridge worlds. You’ll get nowhere with all or nothing and reinventing everything yourselves. Oh – and sort out the branding. 4.x, Core, now 5 – its confusing as all heck even for those of us who follow it and when the rebuttal of this is links to articles trying to explain it thats a sign you’ve got a problem not a solution. If I was looking at it from the outside I’d probably bounce off all this in confusion.
When I look ahead to where I think I’ll be heading personally: ever more down the functional programming route. It offers significant advantages (that I’ve spoken about before) and, at least with F#, a clear path of least resistance. As for runtimes I’ll probably stick in this hybrid world of React and .NET Core for some time – I can’t see any compelling reason to drop either of those at the moment.
As for my day job… the jury is out. Its going to come down to people, productivity and project more than anything else. I see no inherent advantage in .NET Core as a piece of technology.




Recent Comments