I’ve dipped in and out of Azure AD B2C since it first launched. In theory it provides a flexible and fully managed consumer identity provider inside Azure and while I’ve had a couple of successes after recent experiences I’ve come to the conclusion that its simply not ready for anything other than narrow requirements and am pulling my current projects away from it and onto Auth0 (this isn’t a random choice – I’ve used Auth0 before and found it to be excellent). If you’re not on that happy path – it might do what you need but getting there is likely to be a time sink and involve a lot of preview features.
If you’re considering B2C for a project in the near future I’d suggest a couple of things:
- Take a read of the below. It might save you some time.
- Proof of concept all the B2C touch points (policies, customisation etc.) and ensure it will do what you need
Just a quick note on the below – I’ve discussed some of this with MS previously but hopefully they will provide some feedback and I will update if and as appropriate.
Documentation and Ease of Adoption
One of the more serious issues for Azure B2C is the absolutely awful state of the documentation and samples which often feel unfinished and half baked. Identity and the protocols and integration points that go with it are complex, can be intimidating, and important to get right – incorrect integration’s can lead to security vulnerabilities.
As an example of documentation done right I think Auth0 have this nailed – they have lots of detailed documentation, samples, and tutorials on a per framework basis that cover both common frameworks and more obscure ones and a component that will drop into nearly all scenarios.
In contrast Azure AD B2C, at the time of writing, doesn’t really have any of this. If you do find a link to a framework it will generally just drop you to a sample on GitHub and these are often out of date or incomplete. For example the SPA “how tos” don’t really tell you how to – they have you clone a sample of a plain JavaScript project (no framework) and enter the magic numbers.
If you then go and look at the MSAL library that this makes use of then a single scenario is documented (using a popup) and while this is actually a fairly comprehensive framework if you go to it’s API reference you will find no content at all – its just the method and property signatures with no real help on how to wire this together. There’s just enough there for you to figure it out if you know the space but it doesn’t make it easy. If you’re using React I recently published a component to wrap some of this up.
The level of friction is huge and you will have to rely almost entirely on Google and external sources.
In my view the biggest single improvement the Azure AD B2C team could make right now is to take a good look at how the competing vendors have documented their products and take a similar approach for the features they have covering step by step integration with a wide variety of platforms.
Customer Experience
If you read the Azure documentation the favored approach, and what most of the limited documentation covers is to follow the “sign in and sign up” policy route. This presents a user interface to customers that allows them to either sign in or register. Unfortunately the user experience around this is weak and nearly every client I’ve shown this to has, rightly in my view, felt that it would discourage customers from signing up – its all well and good having a strong call to action on your homepage but getting dropped into this kind of decision process is poor. You can see an example of this with local accounts below – note the small “Sign up now” button at the bottom:

Additionally many sites want to take people directly to a registration page – you’d imagine you could modify the authorization request to Azure to take people straight to this section of this policy but unfortunately that’s not possible. And so you need to introduce a sign up policy for this. Additionally carrying information through the sign up process (for example an invite code or a payment plan) can be awkward – and again poorly documented.
If you then want to use a sign in policy as a pair to this the user experience for this is truly abysmal with local accounts – the form is missing labels. This screenshot was taken from a out the box minty fresh B2C installation:

At the time of writing this has been like this for 4 days on multiple subscriptions and others have confirmed the issue for me – I’ve reported it on Twitter and via a support ticket (on Monday – someone literally just got back to me as I wrote that – I will update this with the outcome). It just seems so… shoddy. And that’s not confidence inspiring in an identity provider.
Update: I’ve had a back and forth with Azure Support over this and its not something they are going to fix. The advice is to use a “sign in or sign up” policy instead. Basically the sign up policy as it stands today is pretty much a legacy hangover and work is underway to address the issues. Unfortunately if you do need to split sign up from sign in (and their are many reasons: users can’t self service, account migration etc.) then your only option is to use the “sign in or sign up” policy and customise the CSS to hide the sign in link. Of course a savvy user can use browser tools to edit the CSS and put them right back in – you can’t really prevent sign up with this policy. Needless to say I think this is pretty poor – its a pretty basic feature of an identity solution.
Finally, and rightly, Azure requires people signing up with an email address to verify that email address – however the way they do this is extremely clunky and takes the following form:
- User enters an email address in the sign up page.
- User clicks the Send Verification Code button.
- Microsoft send an email to the user with the code in.
- User checks their email (in the middle of the sign in process).
- The user has to copy and paste the verification code from the email back into B2C the verification code.
- They can then hit “Create” on the registration page.
There are a couple of problems with this but the main issue is: it’s synchronous. If the user doesn’t receive the email or doesn’t have convenient access to it at the point of registration then they can’t proceed and you’ve likely lost that user. There is, as far as I’m aware, no option to send out a more traditional “click the link” to verify an email address and have this done asynchronously by the user – coupled with a claim about the email verification status this would then allow applications to make decisions about a users access based on email verification.
Branding and Customization
Azure AD B2C does support a reasonable degree of flexibility around the branding. Essentially you can replace all the HTML around the core components and use your own CSS to style those. But again this is inconsistent in how it is handled and, again, feels rushed and unfinished.
With the sign up or sign in policy we get a good range of options and you can easily provide a custom page design by uploading a HTML file to blob storage. Great:
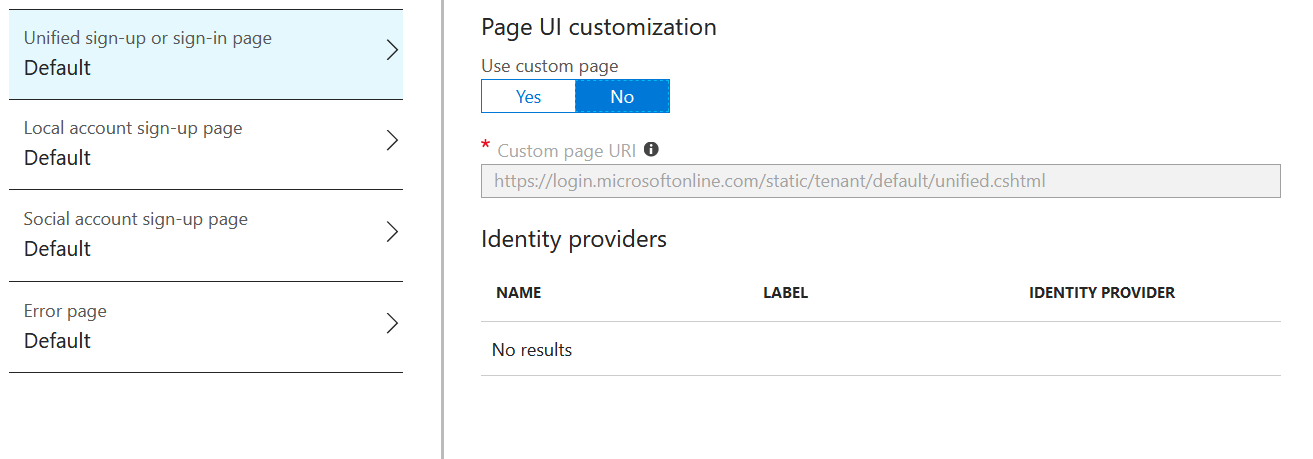
With the sign up policy you get the options for customization shown below, again, makes sense:
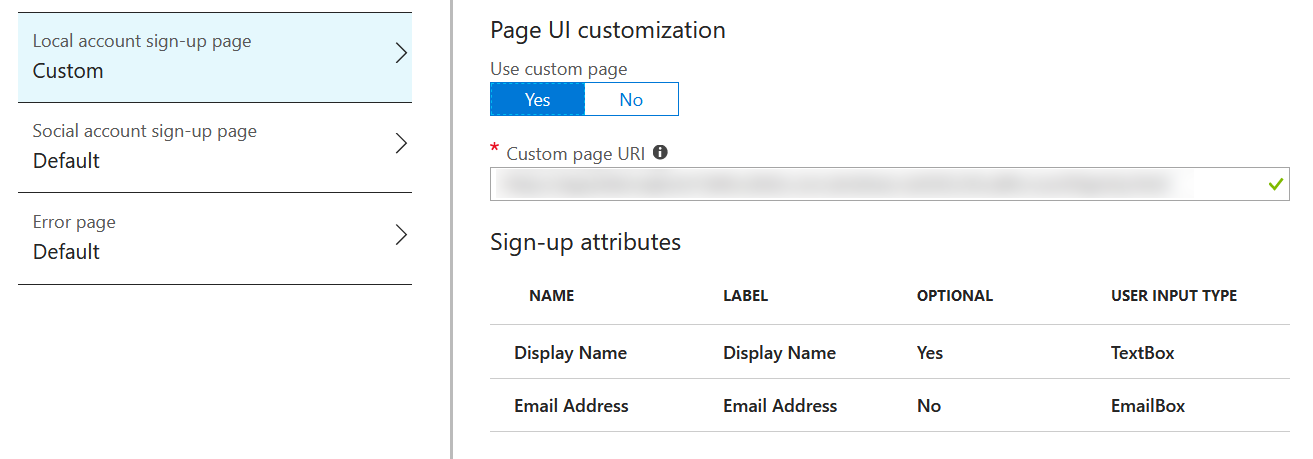
Now we come to the sign in policy:
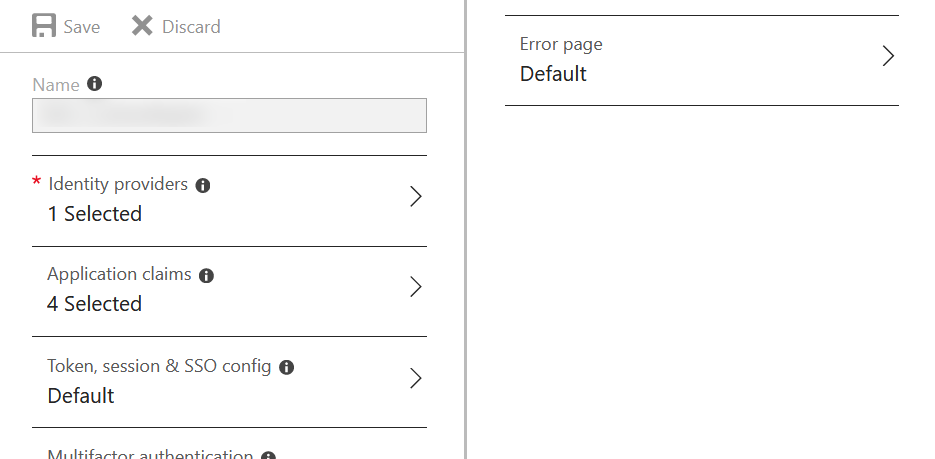
Wait, what? Where are the options? How do we customize this? Well it turns out this is done a different way on the Azure AD that the B2C AD lives within using the “Company Branding” feature that is more limited and only allows for basic customization:
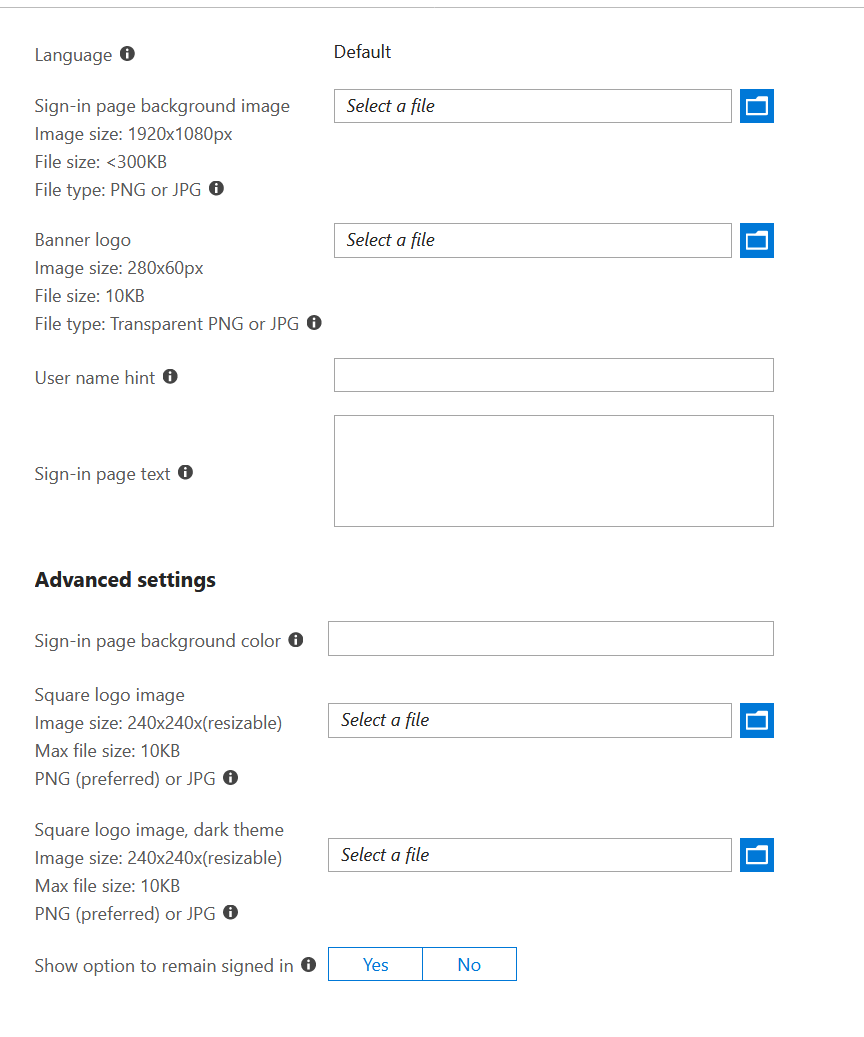
Not only is this just, well, random (from a B2C perspective) but it makes it hard to get a unified branding experience across the piece. You essentially have to design for the lowest common denominator. A retort to this might be “well just use the sign in or sign up policy” but this isn’t always appropriate if sign ups are actually triggered elsewhere and self service isn’t enabled.
Azure Portal Experience
Firstly Azure AD B2C gets created as a resource in its own Azure AD directory which means it doesn’t really sit with the rest of the resources you are using to deliver a system and the Azure Portal is only able to look at one directory at a time. You can link it back to a resource group which provides a shortcut to the B2B resource but ultimately you’ll end up having to manage the directory in another tab in your browser and, if you’re like me and work on multiple systems with multiple clients, its yet another directory in the list.
Not the end of the world – but it can irk.
Beyond that it suffers, like some other services do, by being squeezed into the same one size fits all UI of the portal. Nothing major but its not as slick as vendors like Auth0 or Okta who have dedicated user interfaces.
Finally there is an extremely annoying bug – if you’re testing the sign up and login processes there’s a pretty good chance you’ll be creating and deleting users a lot. However if you try and delete a user after pressing the refresh button (to show the newly created user) on the Users page you get an “can’t find object with ID xxxx” error and have to move out of the users page and back again. Its not the end of the world but it sure is aggravating and has been unfixed for as long as I can remember.
Access to the Underlying Identity Provider Token
Lets say you’re using Facebook to log your users in and want to access the Facebook API on the users behalf – a fairly common requirement. You will generally require the identity and/or access token returned to you from Twitter. Azure AD B2C provides no documented way to do this – so although you can authenticate with social logins you can’t then use the APIs that go along with them.
Apparently this is possible through custom policies – and, after a hint from a MS PM, I believe you can do it from looking at the docs by introducing custom user flow policies but this is a lot of work for a common place requirement that ought to be achievable much more simply.
Again in sharp contrast this is clearly documented by Auth0 and is a fairly simple API call.
Custom Claims
Its not uncommon to want to store attributes against a user for custom claims and Azure AD B2C supports this via the Azure AD Graph API. This is a perfectly fine API and its fairly self explanatory though their is a pretty good chance you will bang your head against the wall for a while with the way that attributes are identified. Essentially they take the form of:
extension_<azureAdApplicationId>_<attributeName>
But as ever Azure AD B2C finds a way to make this un-intuitive and weird and there’s no way to quickly find this in the portal and instead you have to basically call the Graph API to get a list of attributes. When you do you’ll find that the azureAdApplicationId actually comes from the Azure AD that hosts your Azure AD B2C tenant – this is not the same AD your subscription lives in as each Azure AD B2C tenant gets created in its own Azure AD tenant (and yes that makes for real fun with lots of directory switching in the portal) and this AD will have an application in it called b2c-extensions-app:
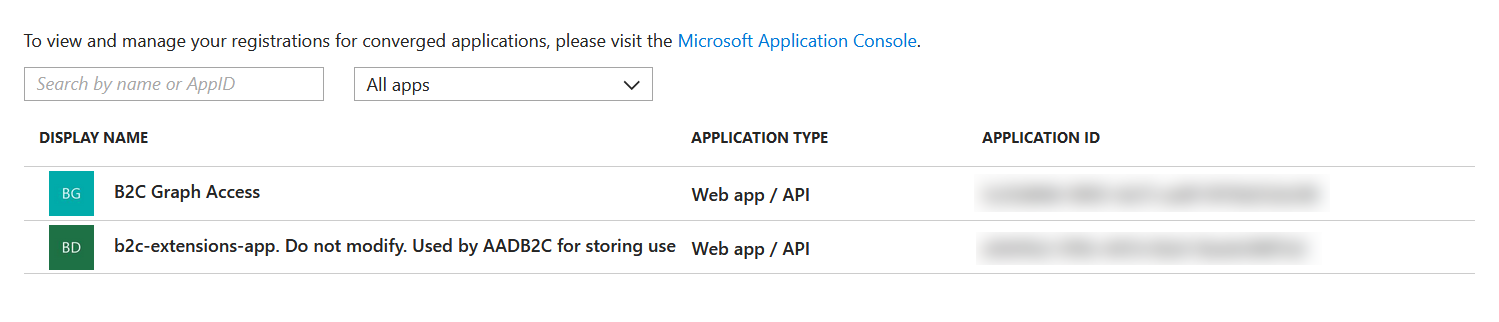
The two blurred out sections are GUIDs – application IDs. And the azureAdApplicationId you actually need as part of the attribute name is the b2c-extensions-app ID with the dashes removed. Sigh.
Getting into the Authentication / Sign Up Flow
You can now do this through custom policies (in preview) but my goodness it’s fiddly and hard to test and involves a fair amount of copy and pasting and calling out to remote REST APIs that you will need to implement. This could eventually provide a lot of flexibility and is a reasonable fit with Azure Functions but given there are so many simple to crack nuts remaining this currently feels like the proverbial sledgehammer.
Again in contrast Auth0 make this a fair bit simpler with their rules and JavaScript approach.
Conclusions
To me, at this point, B2C is massively compromised by the state of the documentation and samples and its compounded that by some poor decisions that directly effect the customers experience in what is, for many systems, a critical part of the user acquisition journey.
It then further suffers on the developer side from inconsistencies and a somewhat byzantine approach to things.
To me it currently feels under-cooked on common requirements while trying to cover the all things to all men requirements with the complex custom policies.
Is it usable? Yes – if your requirements fit down its happy path and you’re prepared to put up with the many rough edges.
However if you want to do anything that veers away from straight “Sign in or sign up” type usage then at this point I’d suggest staying away, I just think there are too many pitfalls and it doesn’t feel either complete or ready, and there are plenty of established vendors in the space with alternative offerings.
First time I’ve really said that about an Azure service.










Recent Comments