When designing cloud based systems we often think about the benefits of loosely coupling systems, for example through queues and pub/sub mechanisms, but fall back on more traditional onion or layered patterns for the application architecture when alternative approaches might provide additional benefits.
My aim over a series of posts is to show how combining the Command pattern with the Mediator pattern can yield a number of benefits including:
- A better separation of concerns with a clear demarkation of domains
- An internally decomposed application that is simple to work with early in it’s lifecycle yet can easily evolve into a microservice approach
- Is able to reliably support none-transactional or distributed data storage operations
- Less repetitive infrastructure boilerplate to write such as logging and telemetry
To illustrate this we’re going to refactor an example application, over a number of stages, from a layered onion ring style to a decoupled in-process application and finally on through to a distributed application. An up front warning, to get the most out of these posts a fair amount of code reading is encouraged. It doesn’t make sense for me to walk through each change and doing so would make the posts ridiculously long but hopefully the sample code provided is clear and concise. It really is designed to go along with the posts.
The application is a RESTful HTTP API supporting some basic, simplified, functionality for an online store. The core API operations are:
- Shopping cart management: get the cart, add products to the cart, clear the cart
- Checkout: convert a cart into an order, mark the order as paid
- Product: get a product
To support the above there is also a sense of store product catalog, it’s not exposed through the API, but it is used internally.
I’m going to be making use of my own command mediation framework AzureFromTheTrenches.Commanding as it has some features that will be helpful to us as we progress towards a distributed application but alternatives are available such as the popular Mediatr and if this approach appeals to you I’d encourage you to look at those too.
Our Starting Point
The code for the onion ring application, our starting point, can be found on GitHub:
https://github.com/JamesRandall/CommandMessagePatternTutorial/tree/master/Part1a
Firstly lets define what I mean by onion ring or layered architecture. In the context of our example application it’s a series of layers built one on top of the other with calls up and down the chain never skipping a layer: the Web API talks to the application services, the application services to the data access layer, and the data access layer to the storage. Each layer drives the one below. To support this each layer is broken out into it’s own assembly and a mixture of encapsulation (at the assembly and class level) and careful reference management ensures this remains the case.
In the case of our application this looks like this:
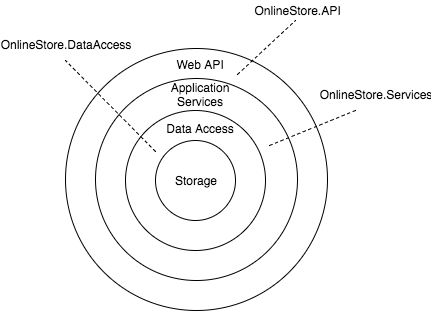
Concrete class coupling is avoided through the use of interfaces and these are constructor injected to promote a testable approach. Normally in such an architecture each layer has its own set of models (data access models, application models etc.) with mapping taking place between them however for the sake of brevity, and as I’m just using mock data stores, I’ve ignored this and used a single set of models that can be found in the OnlineStore.Model assembly.
As this is such a common pattern, it’s certainly the pattern I’ve come across most often over the last few years (where application architecture has been considered at all – sadly the spaghetti / make it up as you go along approach is still prevalent), it’s worth looking at what’s good about it:
- Perhaps most importantly – it’s simple. You can draw out the architecture on a whiteboard with a set of circles or boxes in 30 seconds and it’s quite easy to explain what is going on and why
- It’s testable, obviously things get more complicated in the real world but above the data access layer testing is really easy: everything is mockable and the major concrete external dependencies have been isolated in our data access layer.
- A good example of the pattern is open for extension but closed for modification: because their are clear contractual interfaces decorators can be added to, for example, add telemetry without modifying business logic.
- It’s very well supported in tooling – if you’re using Visual Studio it’s built in refactoring tools or Resharper will have no problem crunching over this solution to support changes and help keep things consistent.
- It can be used in a variety of different operating environments, I’ve used a Web API for this example but you can find onion / layer type architectures in all manner of solutions.
- It’s what’s typically been done before – most engineers are familiar with the pattern and its become almost a default choice.
I’ve built many successful systems myself using this pattern and, to a point, its served me well. However I started looking for better approaches as I experienced some of the weaknesses:
- It’s not as loosely coupled and malleable as it seems. This might seem an odd statement to make given our example makes strong use of interfaces and composition via dependency injection, an approach often seen to promote loose coupling and flexibility. And it does to a point. However we still tend to think of operations in such an architecture in quite a tightly coupled way: this controller calls this method on this interface which is implemented by this service class and on down through the layers. It’s a very explicit invocation process.
- Interfaces and classes in the service layer often become “fat” – they tend to end up coupled around a specific part of the application domain (in our case, for example, the shopping basket) and used to group together functionality.
- As an onion ring application gets larger it’s quite common for the Application Layer to begin to resemble spaghetti – repositories are made reference to from across the code base, services refer to services, and helpers to other helpers. You can mitigate this by decomposing the application layer into further assemblies, and making use of various design patterns, but it only takes you so far. These are all sticking plaster over a fundamental problem with the onion ring approach: it’s designed to segregate at the layer level not at the domain or bounding context level (we’ll talk about DDD later). It’s also common to see concerns start to bleed across the layer with what once were discrete boundaries.
- In the event of fundamental change the architecture can be quite fragile and resistant to easy change. Let’s consider a situation where our online store has become wildly successful and to keep it serving the growing userbase we need to break it apart to handle the growing scale. This will probably involve breaking our API into multiple components and using patterns such as queues to asynchronously run and throttle some actions. With the onion ring architecture we’re going to have to analyse what is probably a large codebase looking for how we can safely break it apart. Almost inevitably this will be more difficult than it first seems and it will probably seem quite difficult to begin with (I may have been here myself!) and we’ll uncover all manner of implicit tight coupling points.
There are of course solutions to many of these problems, particularly the code organisation issues, but at some point it’s worth considering if the architecture is still helping you or beginning to hinder you and if perhaps there are alternative approaches.
With that in mind, and as I said earlier, I’d like to introduce an alternative. It’s by no means the alternative but its one I’ve found tremendously helpful when building applications for the cloud.
The Command Pattern with a Mediator
The classic command pattern aims to encapsulate all the information needed to perform an action typically within a class that contains properties (the data needed to perform the action) and an execute method (that undertakes the action). For example:
public class GetProductCommand : ICommand<Product>
{
public Guid ProductId { get; set; }
public Task<Product> Execute()
{
/// ... logic
}
}
This can be a useful way of structuring an application but tightly couples state and execution and that can prove limiting if, for example, it would be helpful for the command to participate in a pub/sub approach, take part in a command chain (step 1 – store state in undo, step 2 – execute command, step 3 – log command was executed), or operate across a process boundary.
A powerful improvement can be made to the approach by decoupling the execution from the command state via the mediator pattern. In this pattern all commands, each of which consist of simple serializable state, are dispatched to the mediator and the mediator determines which handlers will execute the command:
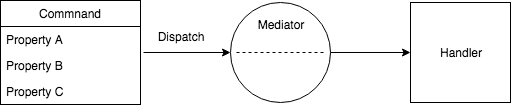
Because the command is decoupled from execution it is possible to associate multiple handlers with a command and moving a handler to a different process space (for example splitting a Web API into multiple Web APIs) is simply a matter of changing the configuration of the mediator. And because the command is simple state we can easily serialize it into, for example, an event store (the example below illustrates a mediator that is able to serialize commands to stores directly, but this can also be accomplished through additional handlers:
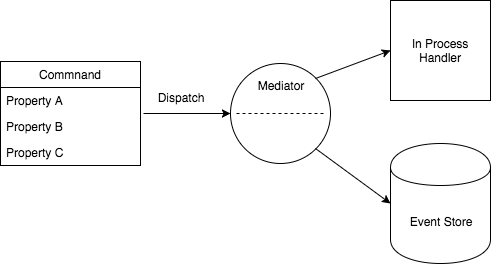
It’s perhaps worth also briefly touching on the CQRS pattern – while the Command Message pattern may facilitate a CQRS approach it neither requires it or has any particular opinion on it.
With that out the way lets take a look at how this pattern impacts our applications architecture. Firstly the code for our refactored solution can be found here:
https://github.com/JamesRandall/CommandMessagePatternTutorial/tree/master/Part1b
And from our layered approach we now end up with something that looks like this:
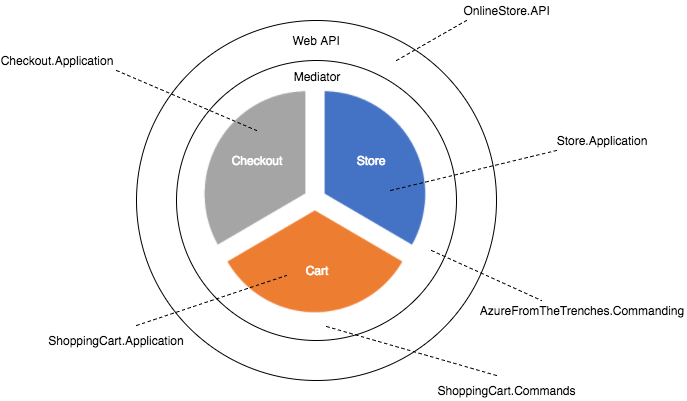
It’s important to realise when looking at this code that we’re going to do more work to take advantage of the capabilities being introduced here. This is really just a “least work” refactor to demonstrate some high level differences – hopefully over the next few posts you’ll see how we can really use these capabilities to simplify our solution. However even at this early stage there are some clear points to note about how this effects the solution structure and code:
- Rather than structure our application architecture around technology we’ve restructured it around domains. Where previously we had a data access layer, an application layer and an API layer we now have a shopping cart application, a checkout application, a product application and a Web API application. Rather than the focus being about technology boundaries its more about business domain boundaries.
- Across boundaries (previously layers, now applications) we’ve shifted our invocation semantics from interfaces, methods and parameters to simple state that is serializable and persistable and communicated through a “black box” mediator or dispatcher. The instigator of an operation no longer has any knowledge about what will handle the operation and as we’ll see later that can even include the handler executing in a different process space such as another web application.
- I’ve deliberately used the term application for these business domain implementations as even though they are all operating in the same process space it really is best to think of them as self contained units. Other than a simple wiring class to allow them to be configured in the host application (via a dependency injector) they interoperate with their host (the Web API) and between themselves entirely through the dispatch of commands.
- The intent is that each application is fairly small in and of itself and that it can take the best approach required to solve it’s particular problem. In reality it’s quite typical that many of the applications follow the same conventions and patterns, as they do here, and when this is the case its best to establish some code organisation concentions. In fact it’s not uncommon to see a lightweight onion ring architecture used inside each of these applications (so for lovers of the onion ring – you don’t need to abandon it completely!).
Let’s start by comparing the controllers. In our traditional layered architecture our product controller looked like this:
[Route("api/[controller]")]
public class ProductController : Controller
{
private readonly IProductService _productService;
public ProductController(IProductService productService)
{
_productService = productService;
}
[HttpGet("{id}")]
public async Task<StoreProduct> Get(Guid id)
{
return await _productService.GetAsync(id);
}
}
As expected this accepts an instance of a service, in this case of an IProductService, and it’s get method simply passes the ID on down to it. ALthough the controller is abstracted away from the implementation of the IProductService it is clearly and directly linked to one type of service and a method on that service.
Now lets look at its replacement:
[Route("api/[controller]")]
public class ProductController : Controller
{
private readonly ICommandDispatcher _dispatcher;
public ProductController(ICommandDispatcher dispatcher)
{
_dispatcher = dispatcher;
}
[HttpGet("{id}")]
public async Task Get(Guid id)
{
return await _dispatcher.DispatchAsync(new GetStoreProductQuery
{
ProductId = id
});
}
}
In this implementation the controller accepts an instance of ICommandDispatcher and then rather than invoke a method on a service it calls DispatchAsync on that dispatcher supplying it a command model. The controller no longer has any knowledge of what is going to handle this request and all our commands are executed by discrete handlers. In this case the GetStoreProductQuery command is handled the the GetStoreProductQueryHandler in the Store.Application assembly:
internal class GetStoreProductQueryHandler : ICommandHandler<GetStoreProductQuery, StoreProduct>
{
private readonly IStoreProductRepository _repository;
public GetStoreProductQueryHandler(IStoreProductRepository repository)
{
_repository = repository;
}
public Task<StoreProduct> ExecuteAsync(GetStoreProductQuery command, StoreProduct previousResult)
{
return _repository.GetAsync(command.ProductId);
}
}
It really does no more than the implementation of the ProductService in our initial application but importantly derives from the ICommandHandler generic interface supplying as generic types the type of the command it is handling and the result type. Our command mediation framework takes care of routing the command to this handler and will ultimately call ExecuteAsync on it. The framework we are using here allows commands to be chained and so as well as being given the command state it is also given any previous result.
Handlers are registered against actors as follows (this can be seen in the IServiceCollectionExtenions.cs file of Store.Application):
commandRegistry.Register<GetStoreProductQueryHandler>();
The command mediation framework has all it needs from the definition of GetStoreProductQueryHandler to map the handler to the command.
I think it’s fair to say that’s all pretty loosely coupled! In fact its so loose that if we weren’t going to go on to make more of this pattern we might conclude that the loss of immediate traceability is not worth it.
In the next part we’re going to visit some of our more complicated controllers and commands, such as the Put verb on the ShoppingCartController, to look at how we can massively simplify the code below:
[HttpPut("{productId}/{quantity}")]
public async Task<IActionResult> Put(Guid productId, int quantity)
{
CommandResponse response = await _dispatcher.DispatchAsync(new AddToCartCommand
{
UserId = this.GetUserId(),
ProductId = productId,
Quantity = quantity
});
if (response.IsSuccess)
{
return Ok();
}
return BadRequest(response.ErrorMessage);
}
By way of a teaser the aim is to end up with really thin controller action that, across the piece, look like this:
[HttpPut("{productId}/{quantity}")]
public async Task<IActionResult> Put([FromRoute] AddToCartCommand command) => await ExecuteCommand(command);
We’ll then roll that approach out over the rest of the API. Then get into some really cool stuff!

Recent Comments