Since I published this piece Microsoft have made significant improvements to HTTP scaling on Azure Functions and the below is out of date. Please see this post for a revised comparison.
If you’ve been following my blog recently you’ll know I’ve been spending a lot of time with the Azure Functions – Microsoft’s implementation of a serverless platform. The idea behind serverless appeals to me massively and seems like the natural next evolution of compute on the cloud with scaling and pricing being, so the premise goes, fully dynamic and consumption based.
The use of App Service Plans (more later) as a host mechanism for Azure Functions gave me some concern about how “serverless” Azure Functions might actually be and so to verify suitability for my use cases I’ve been running a range of different tests around response time and latency that culminated in the “real” application I described in my last blog post and some of the performance tests I ran along the way. I quickly learned that the hosting implementation is not particularly dynamic and so wanted to run comparable tests on AWS Lambda.
To do this I’ve ported the serverless blog over to AWS Lambda, S3 and DynamoDB (the, rather scruffy, code is in a branch on GitHub – I will tidy this up but the aim was to get the tests running) and then I’ve run a number of user volume scenarios against a single test case: loading the homepage. The operations involved in this are:
- A GET request to a serverless HTTP endpoint that:
- Loads 3 resources from storage (Blob Storage on Azure, S3 on AWS) in an asynchronous batch.
- Combines them together using a Handlebars template
- Returns the response as a string of type text/html.
On Azure I’m using .NET 4.6 on the v1 runtime while on AWS I’m using the same code running under .NET Core 1.0. It’s worth noting that latency on blob access remained minimal throughout all these tests (6ms on average across all loads) and when removing blob access from the tests it made little difference to the patterns.
Although the .NET 4.6 and Core runtimes are different (and accepted may exhibit different behaviours) these are the current general availability options for implementing serverless on the two platforms using .NET and both vendors claim full support for them. In Microsoft’s case some of the languages supported on the v1 Azure Functions runtime, the one tested here (v2 is in preview and has serious performance issues with .NET Core), are experimental and documented as having scale problems but C# (which runs under full framework .NET) is not one of them. Both vendors have .NET Core 2.0 support on the way and in preview but given the issues I’m waiting until they go on general availability until I compare them.
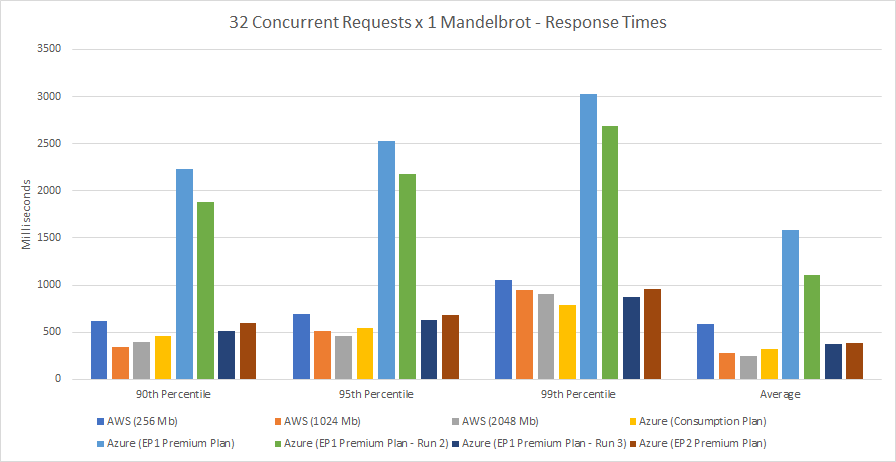
The results are, frankly, pretty damning when it comes to Azure Functions ability to scale dynamically and so let’s get into the data and then look at why.
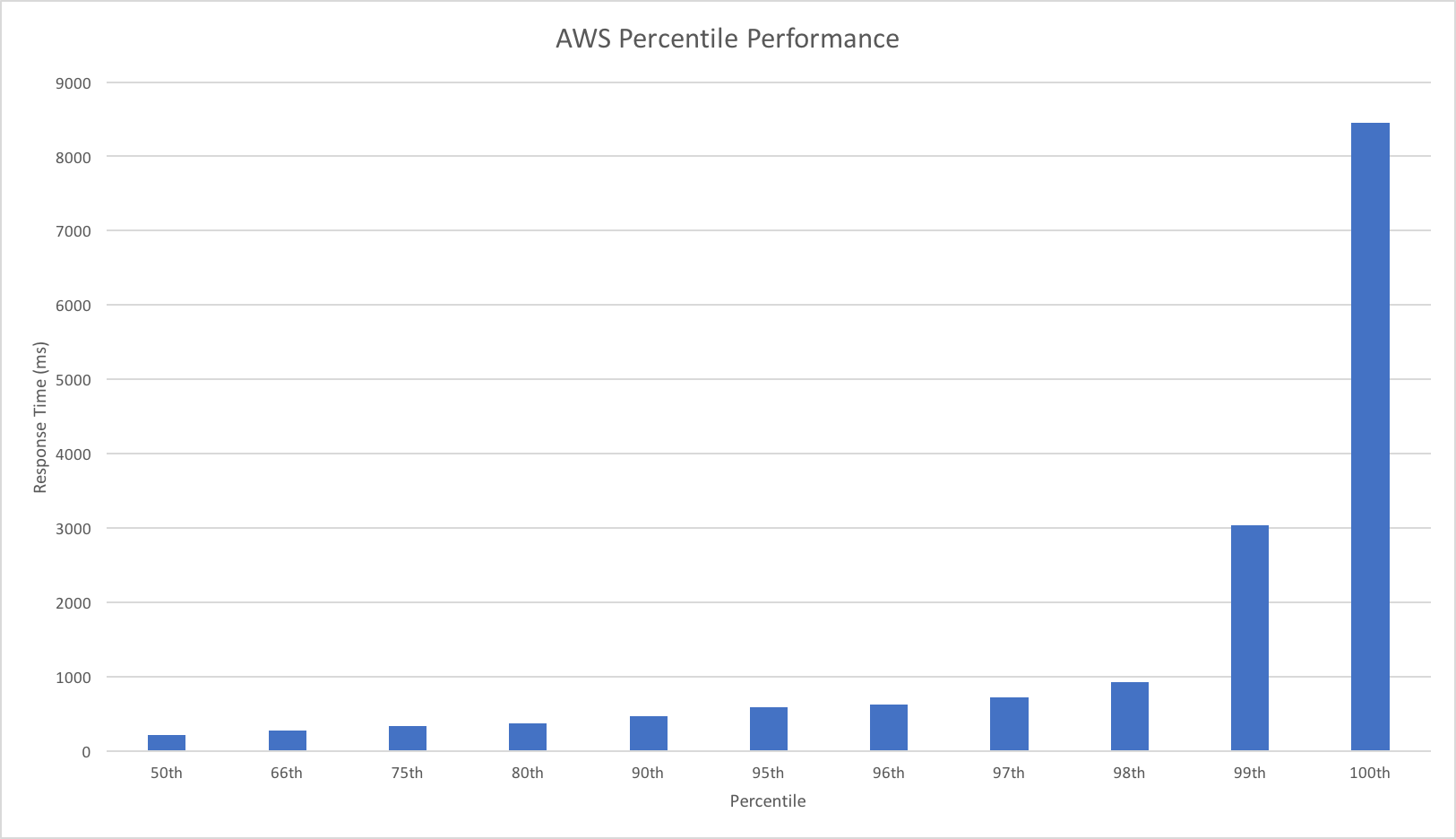
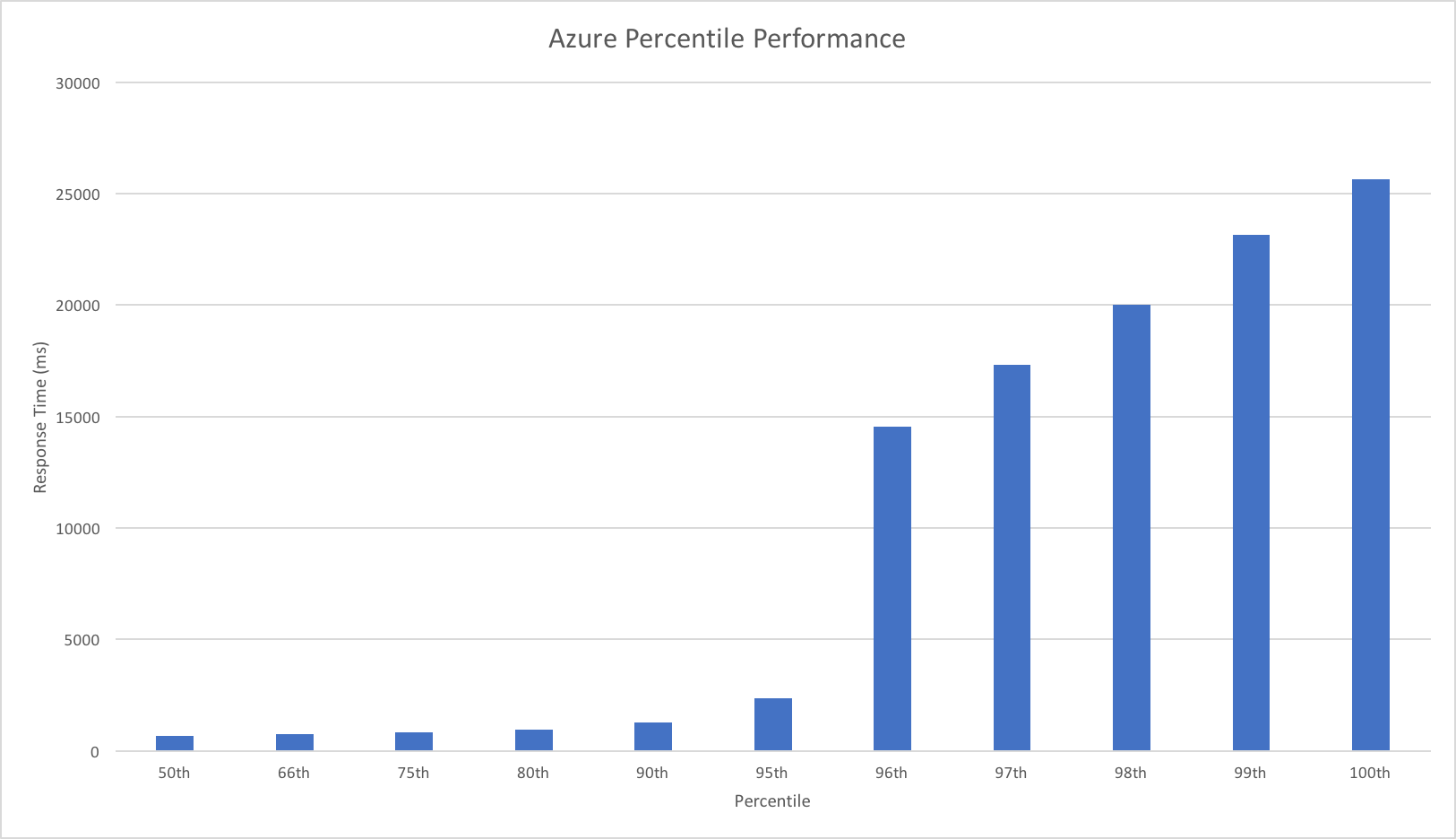
A quick note on the graphs: I’ve pulled these from VSTS, it’s quite hard (or at least I don’t know how to!) equalise the scales and so please do look at the numbers carefully – the difference is quite startling.
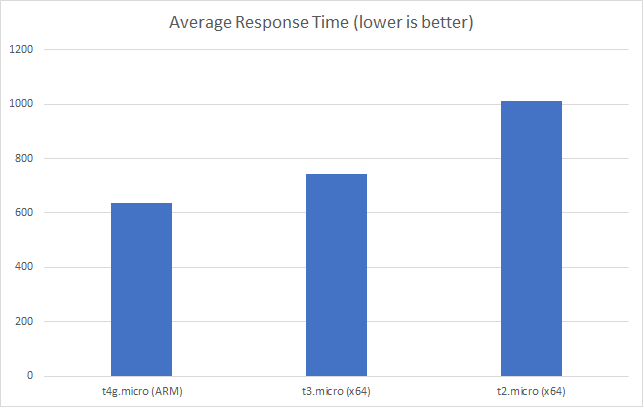
Add 2 Users per Second
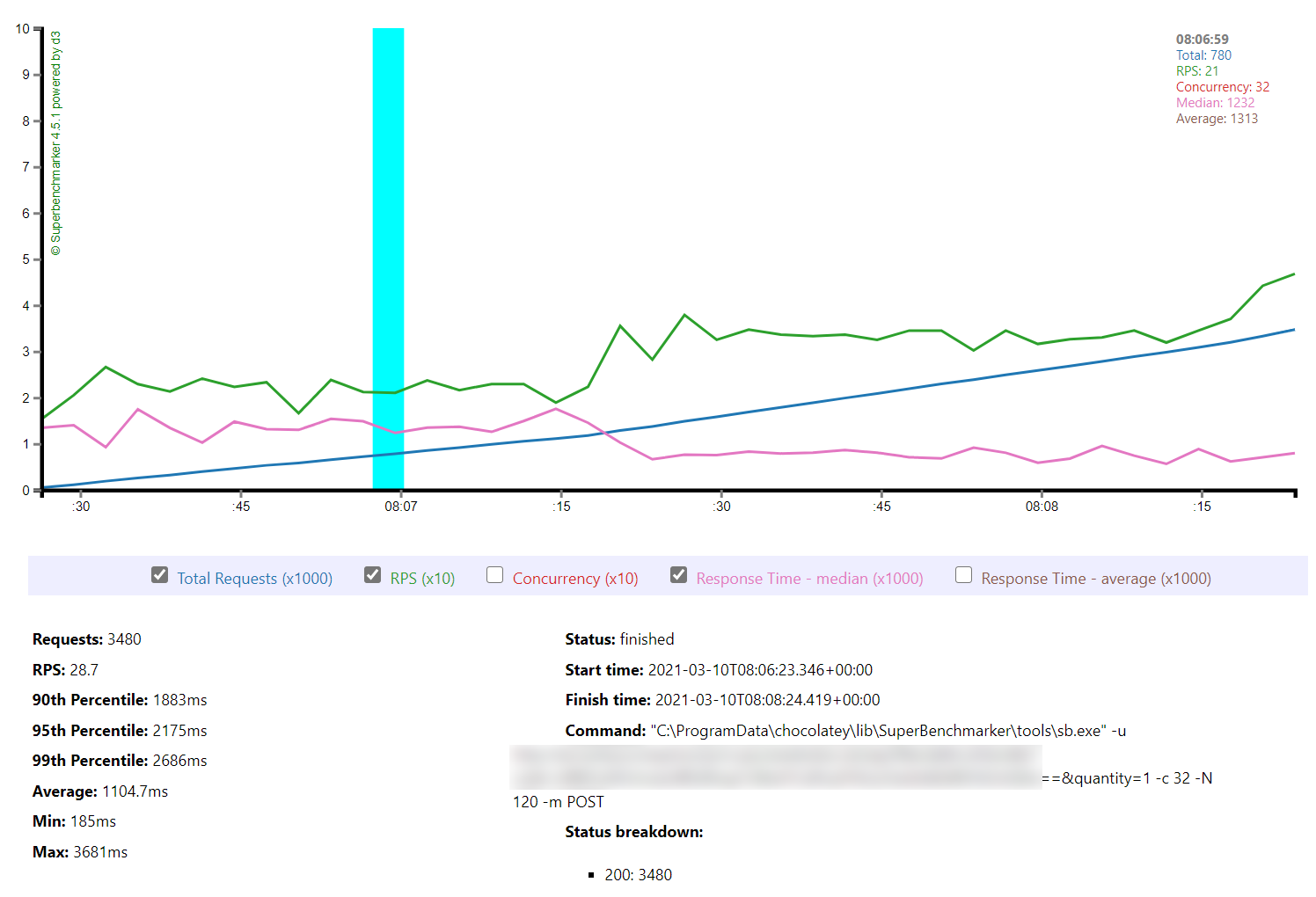
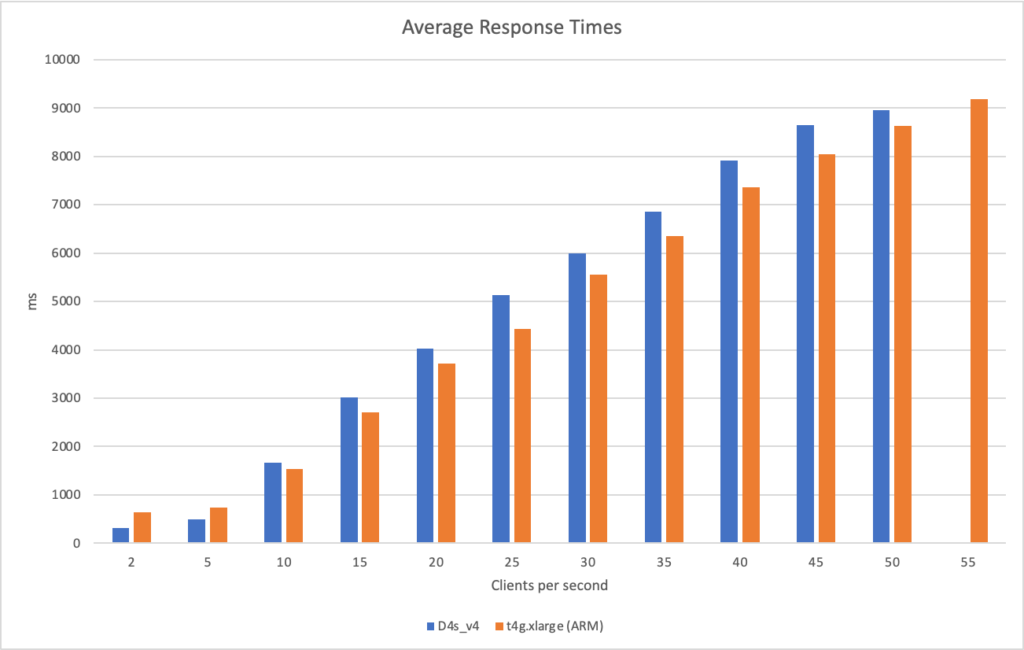
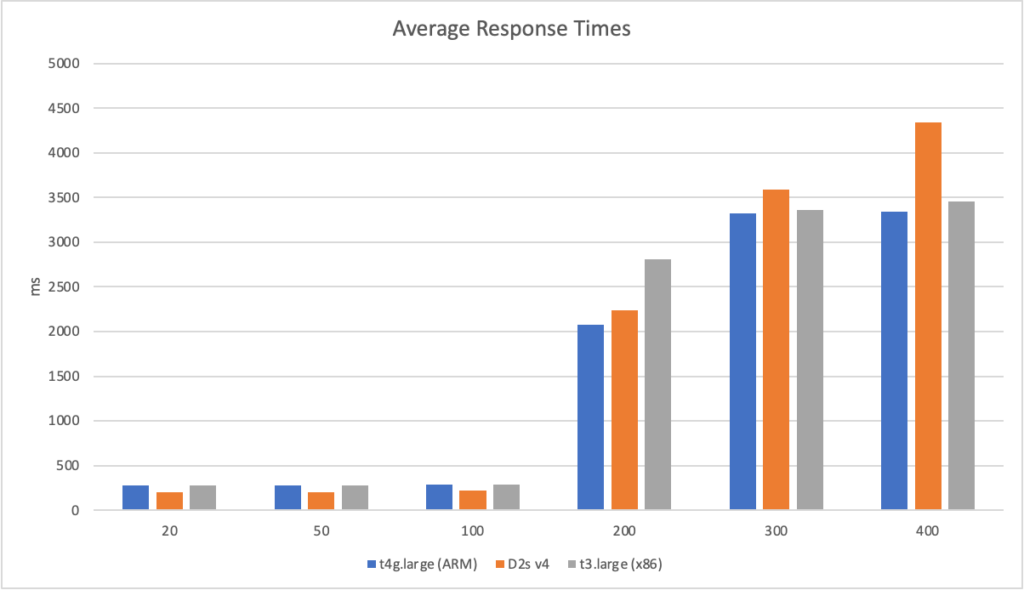
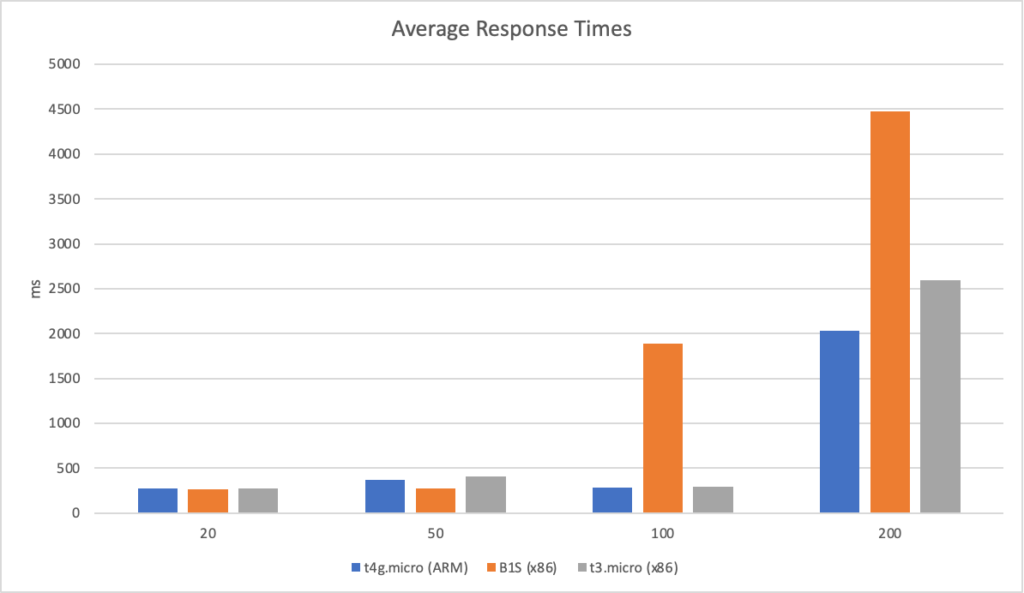
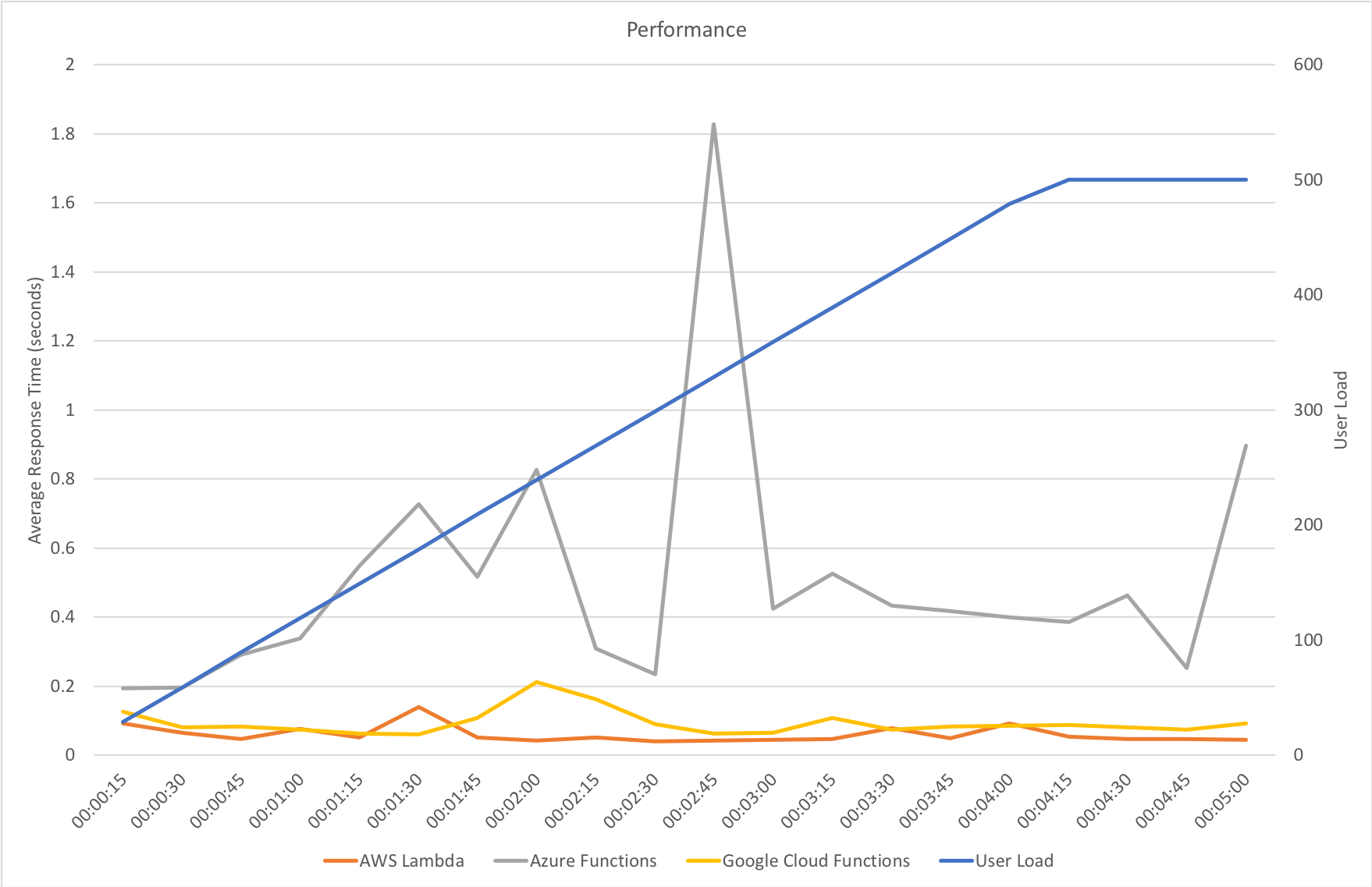
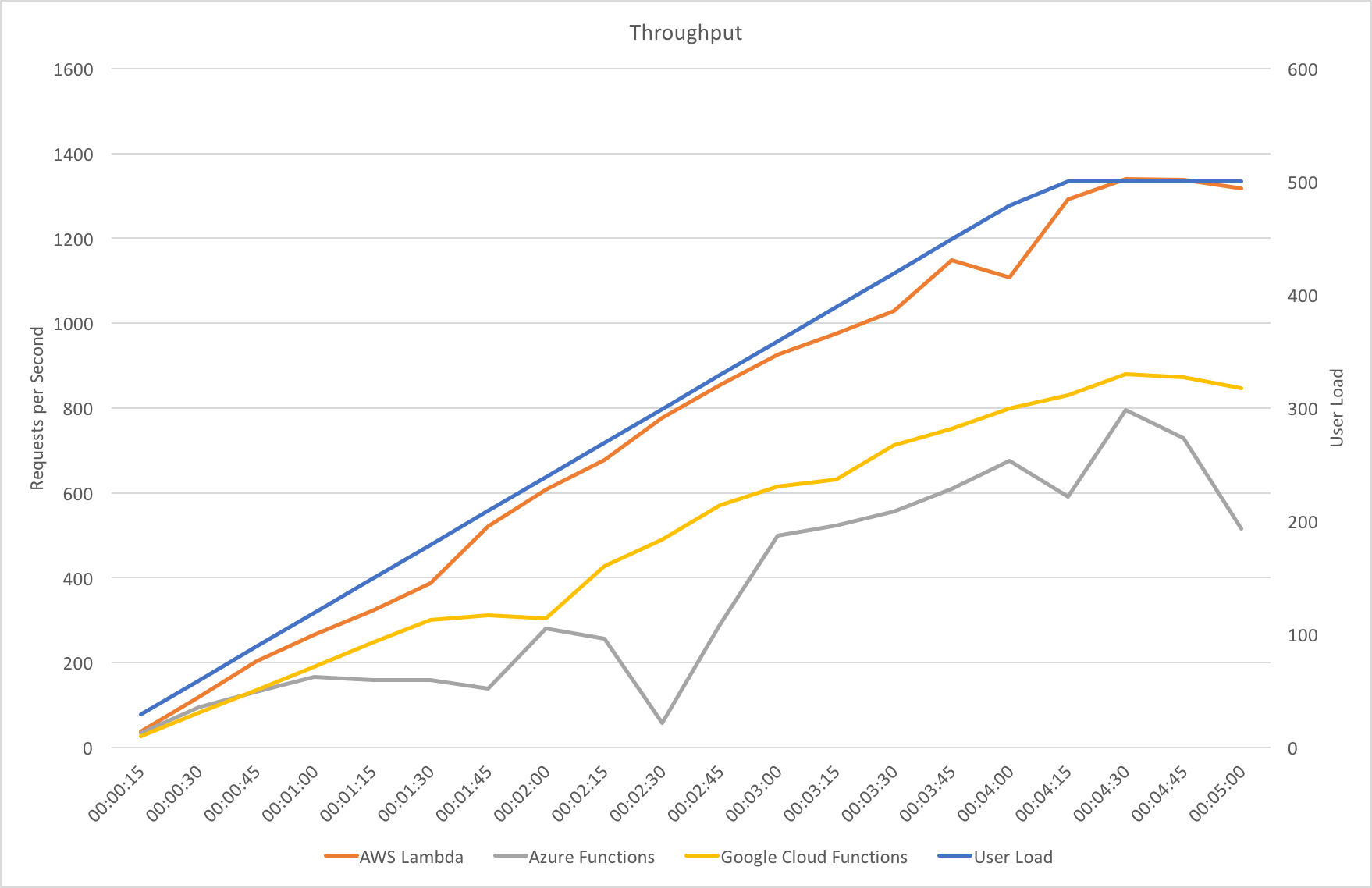
In this test scenario I’ve started with a single user and then added 2 users per second over a 5 minutes run time up to a maximum of 500 users:
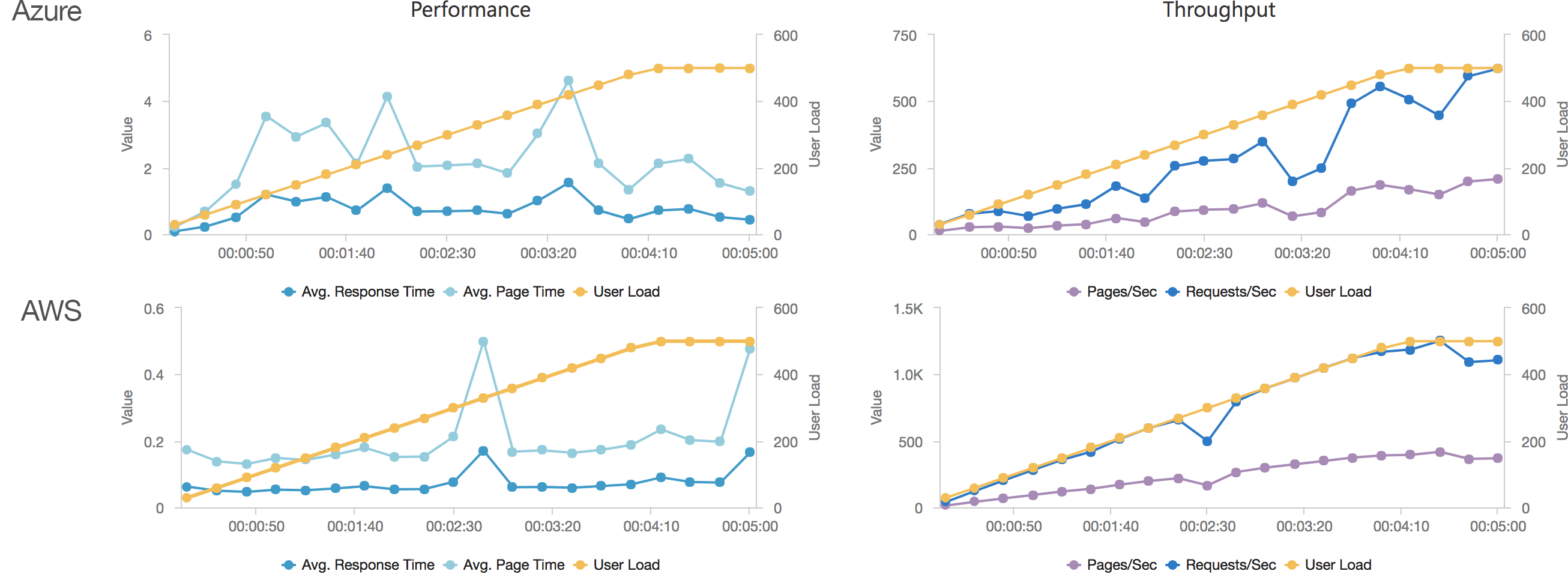
We can see from this test that AWS matches the growth in user load almost exactly, it has no issue dealing with the growing demand and page requests time hover around the 100ms mark. Contrast this with Azure which always lags a little behind the demand, is spikier, and has a much higher response time hovering around the 700ms mark.
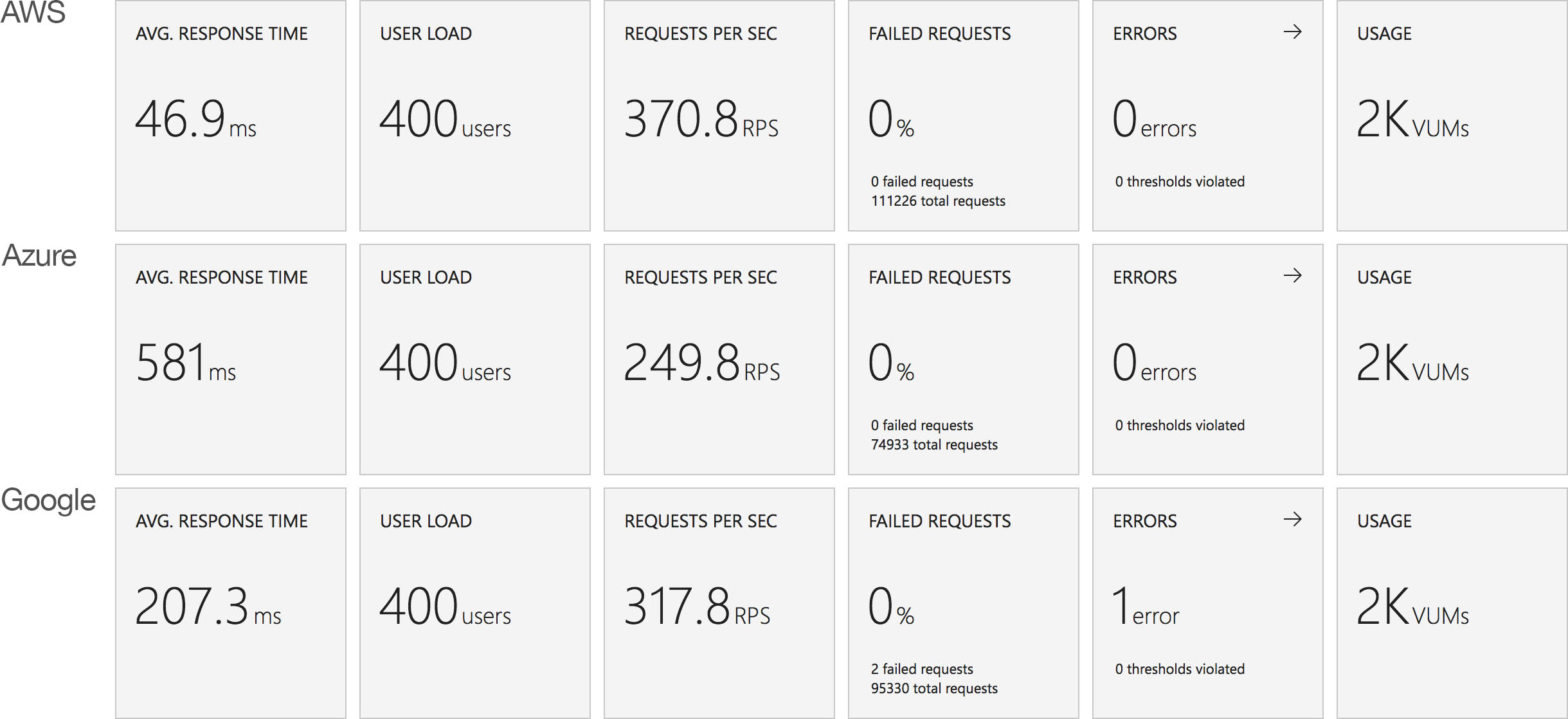
This is backed up by the average stats from the run:
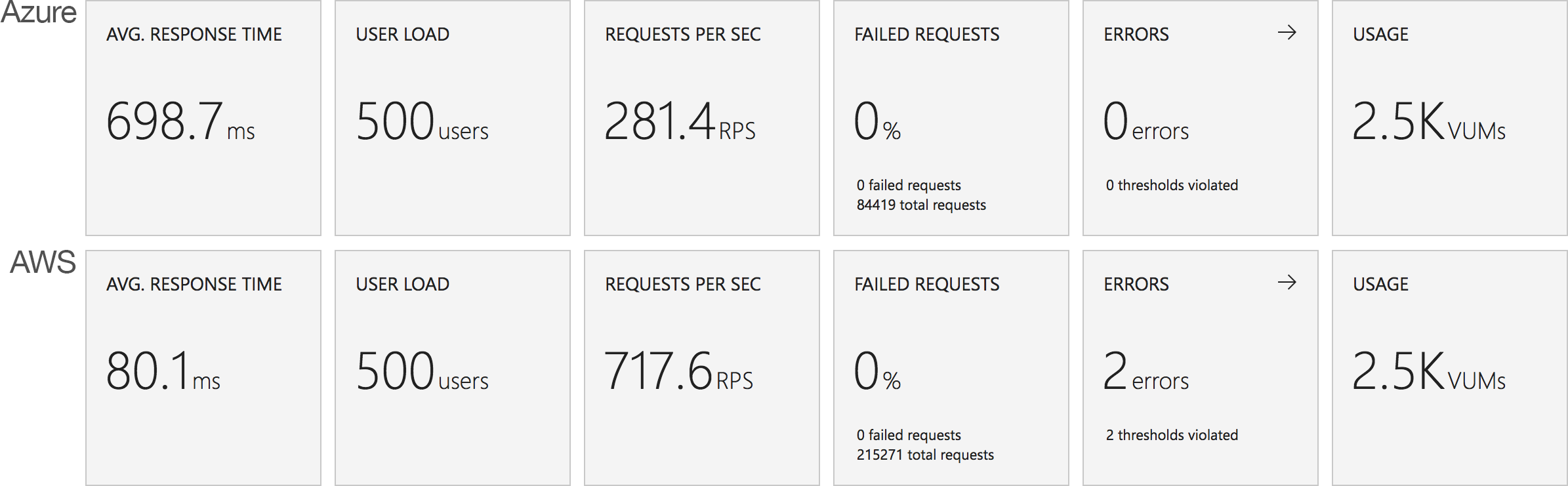
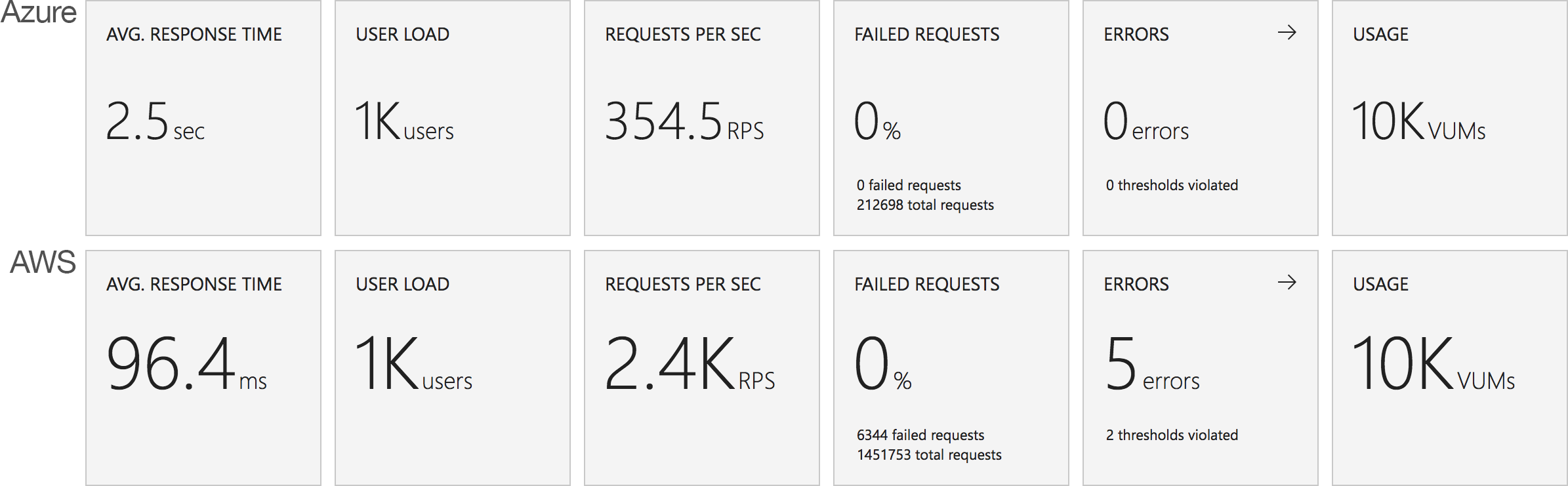
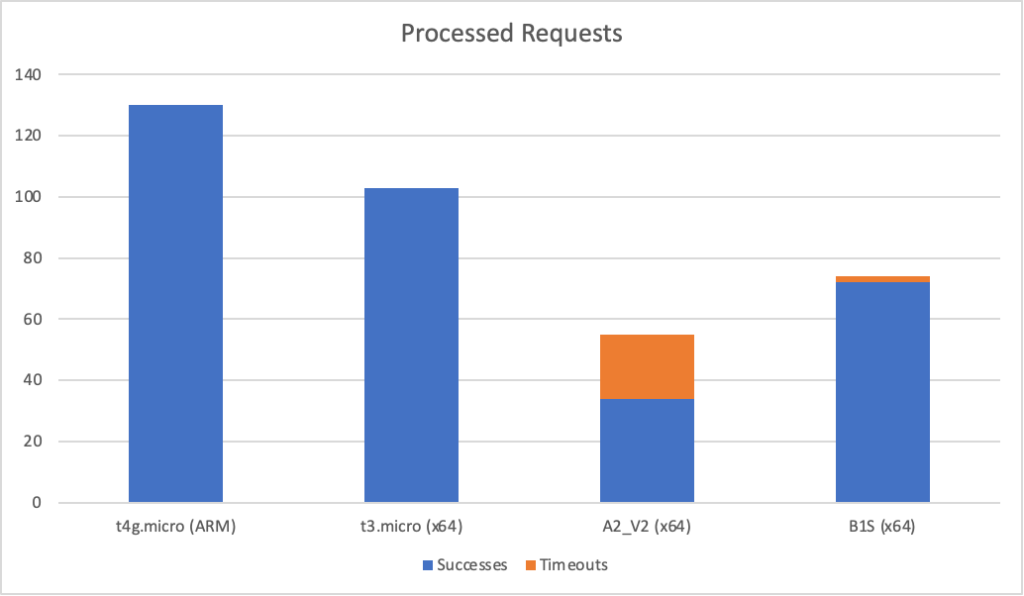
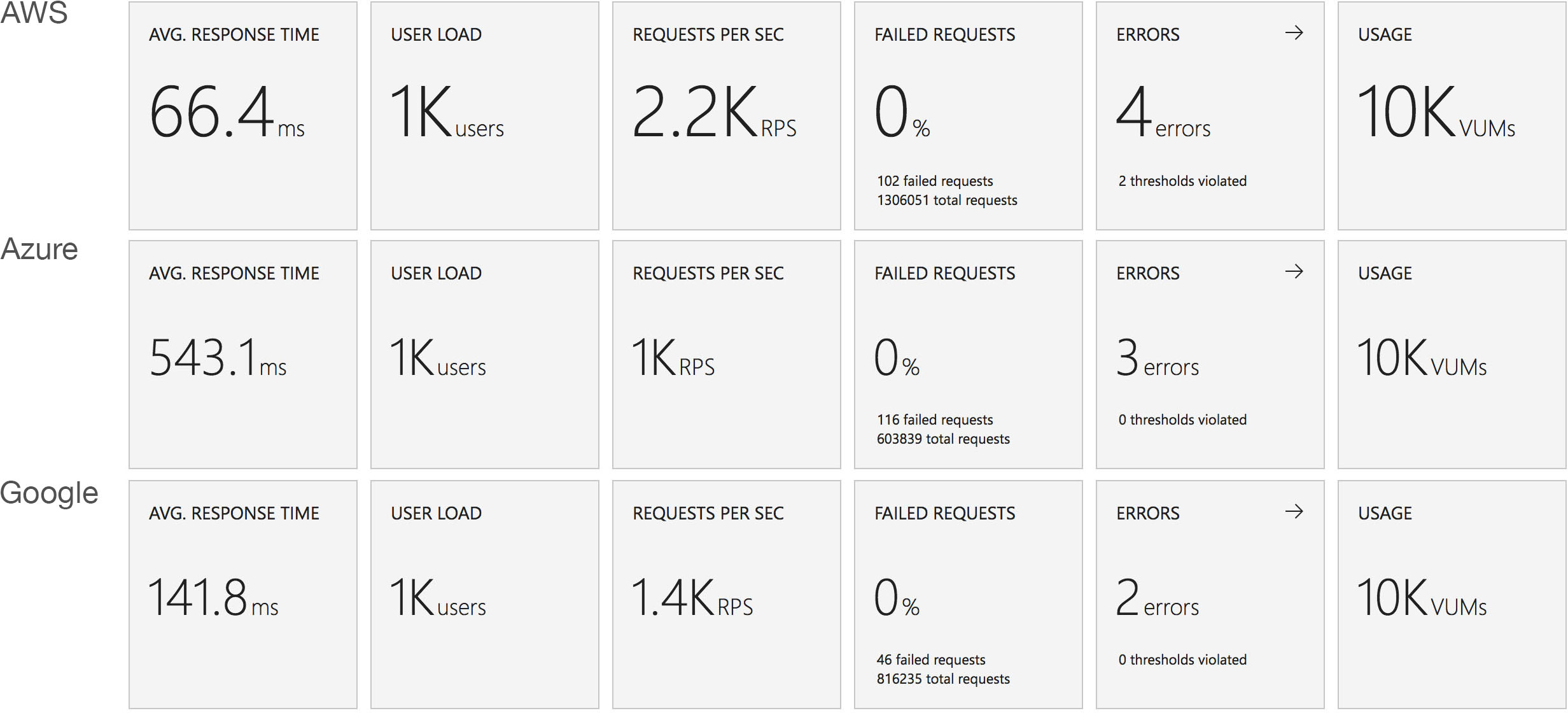
It’s interesting to note just how many more requests AWS dealt with as a result of it’s better performance: 215271 as opposed to Azure’s 84419. Well over twice as many.
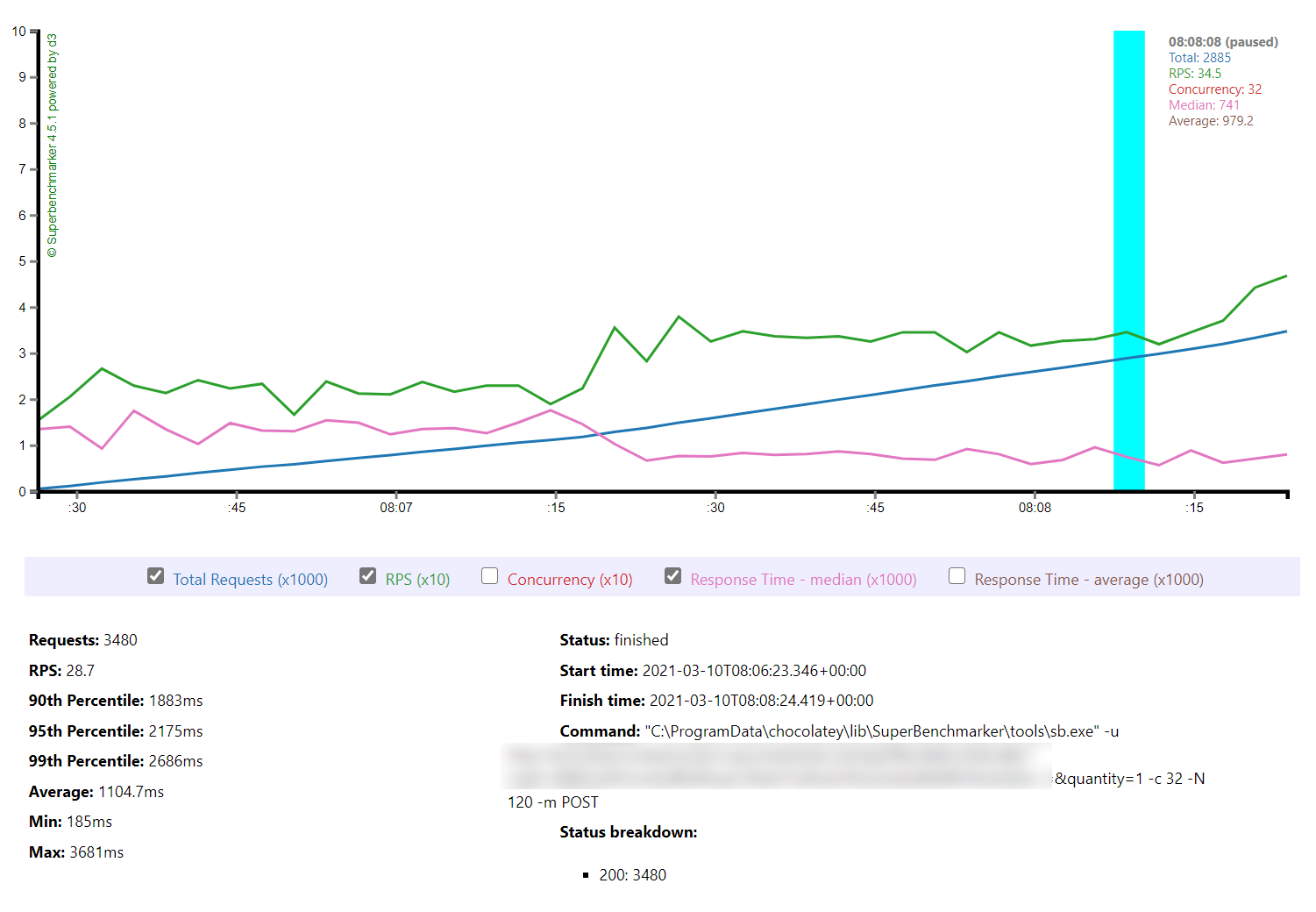
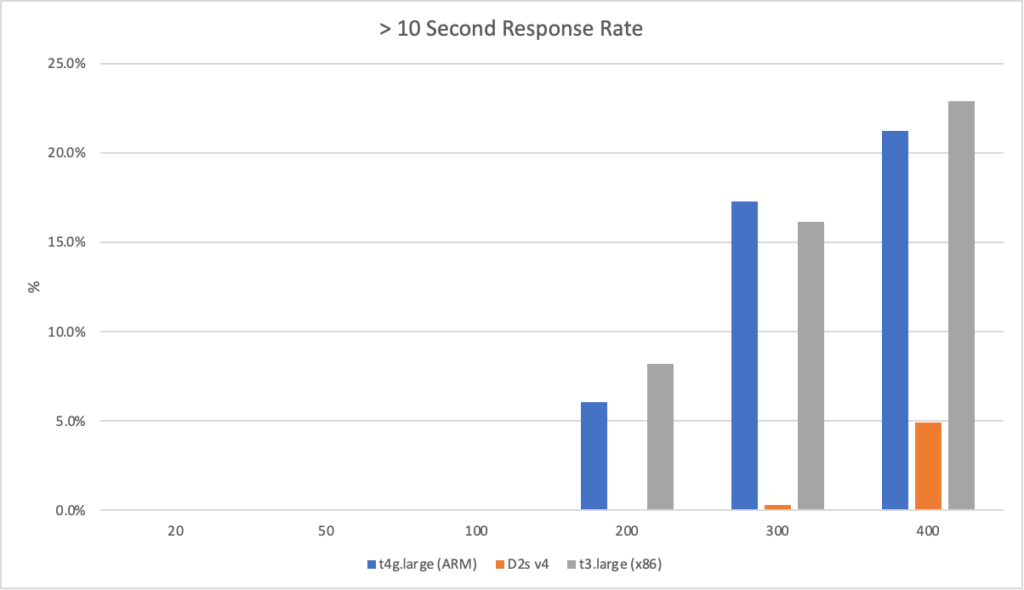
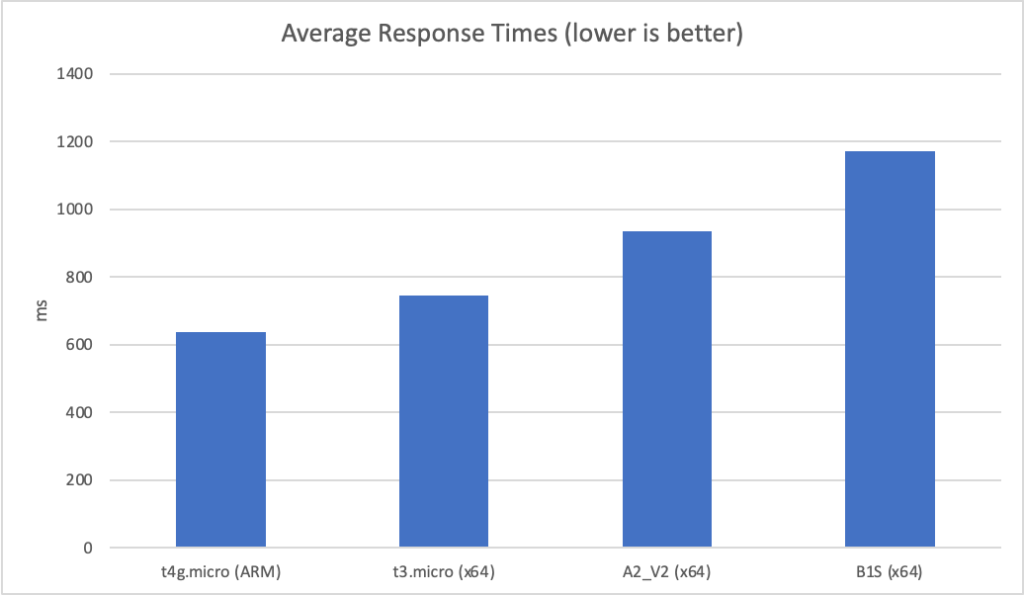
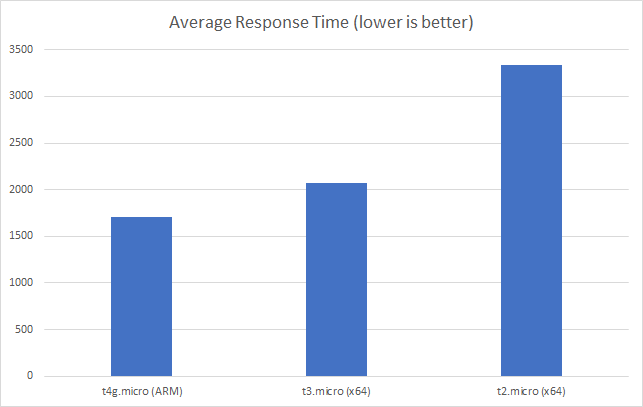
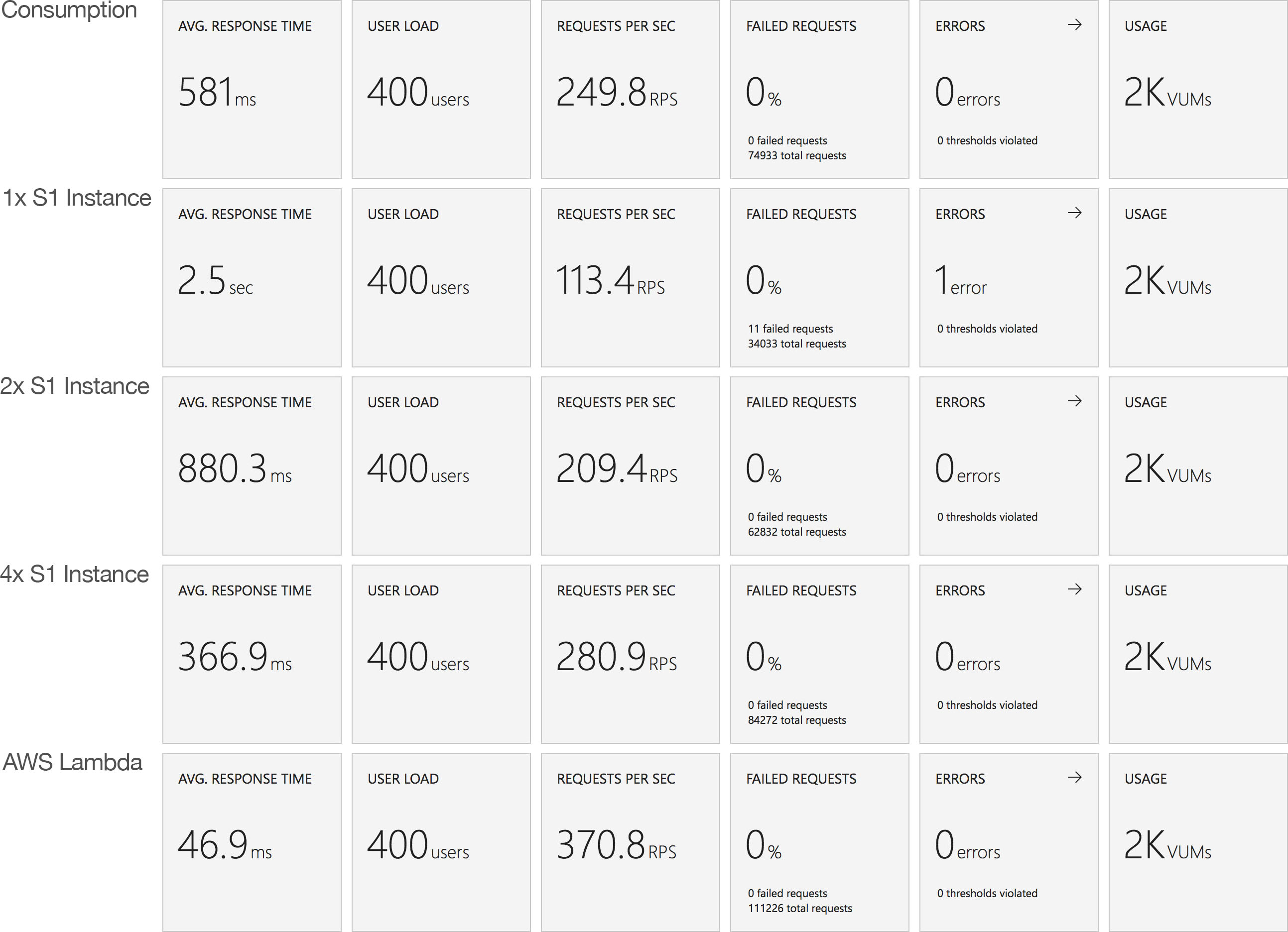
Constant Load of 400 Concurrent Users
This test hits the application with 400 concurrent users from a standing start and runs over a 10 minute period simulating a sudden spike or influx of traffic and looking at how quickly each serverless environment is able to deal with the load. Neither environment was completely cold as I’d been refreshing the view in the browser but neither had had any significant traffic for some time. The contrast is significant to say the least:
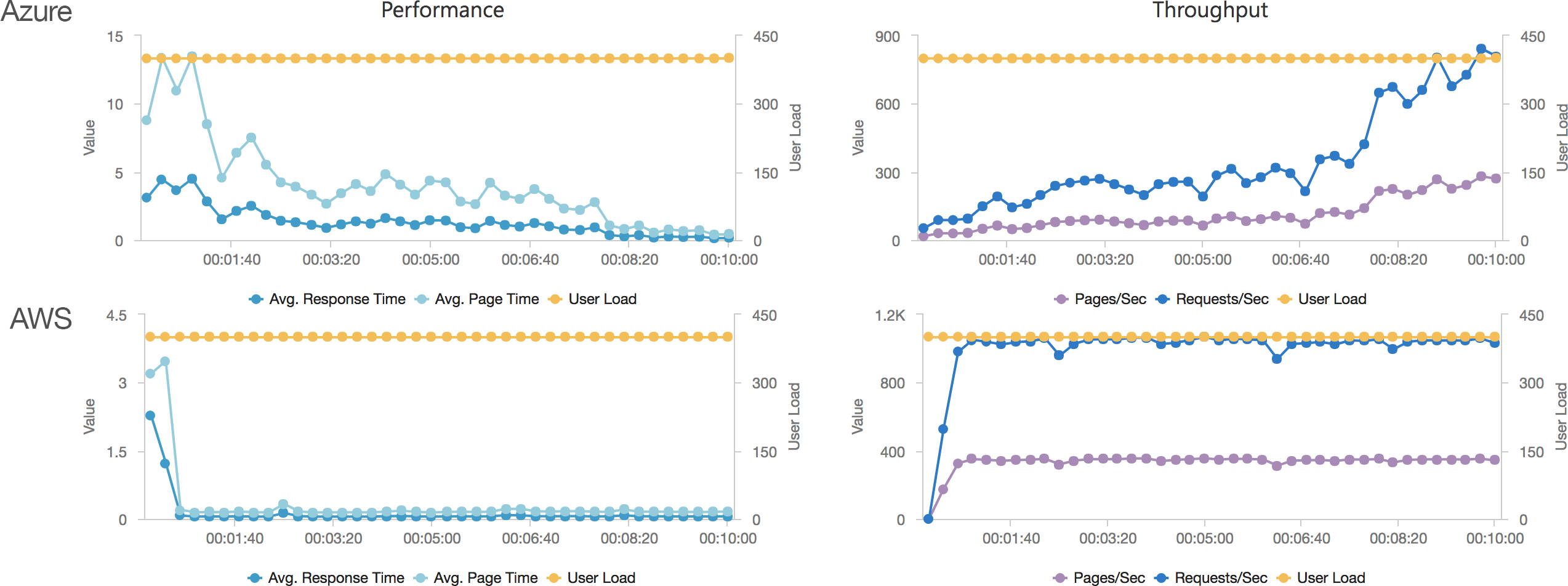
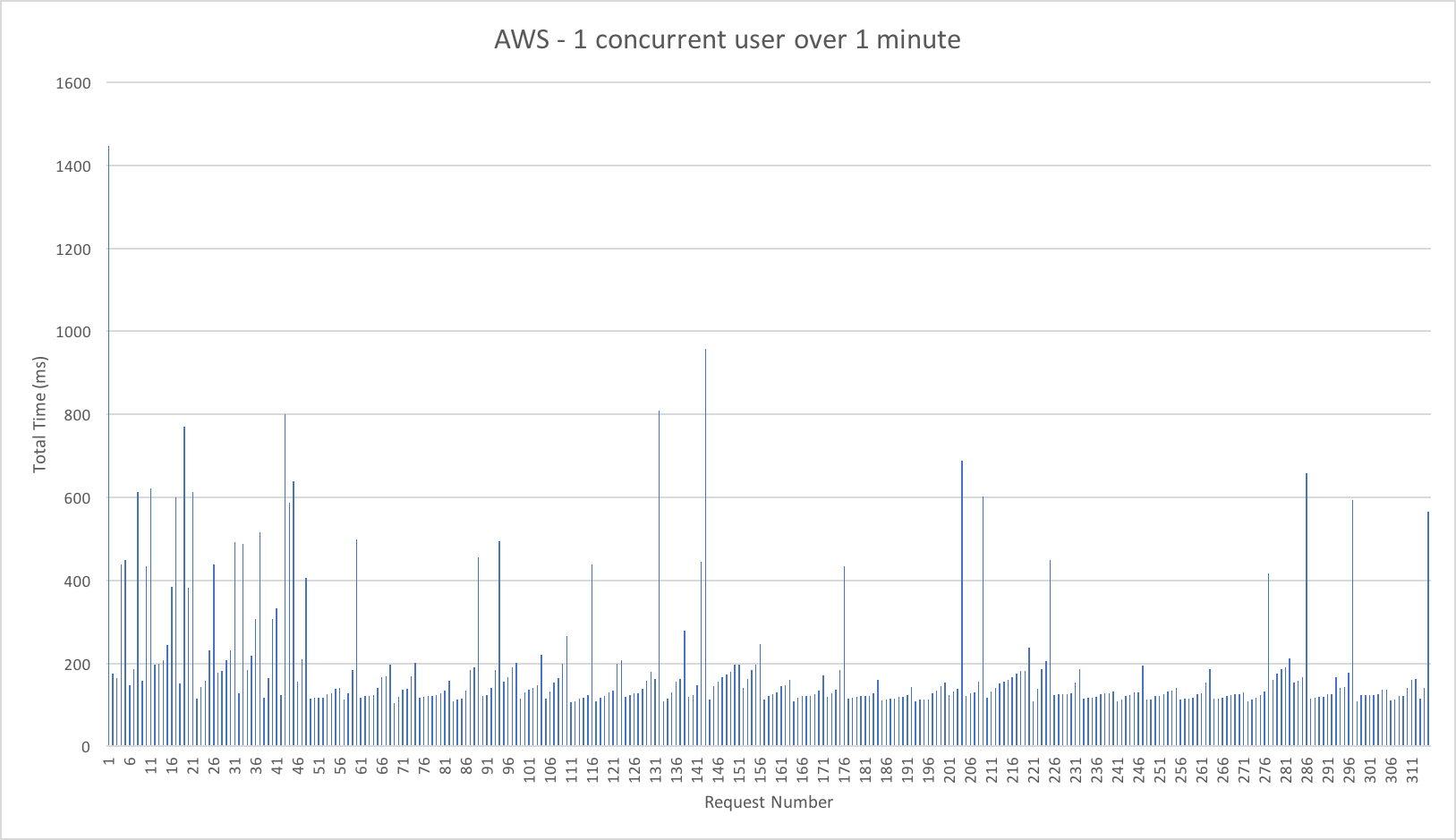
Let’s cover AWS first as it’s so simple: it quickly absorbs the load and hits a steady response time of around 80ms again in under a minute.
Azure, on the other hand, is more complex. Average response time doesn’t fall under a second until the test has been running for 7 minutes and it’s only around then that the system is able to get near the throughput AWS put out in a minute. Pretty disappointing and backed up by the overall stats for the run:
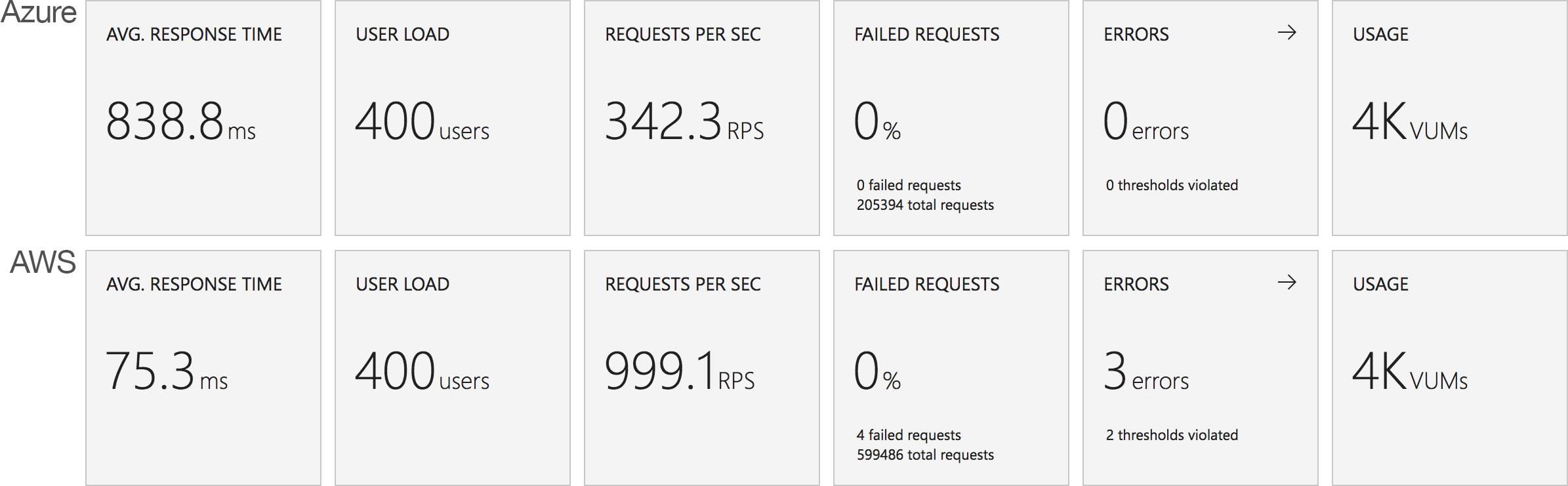
Again it’s striking just how improved the AWS stats over the Azure figures.
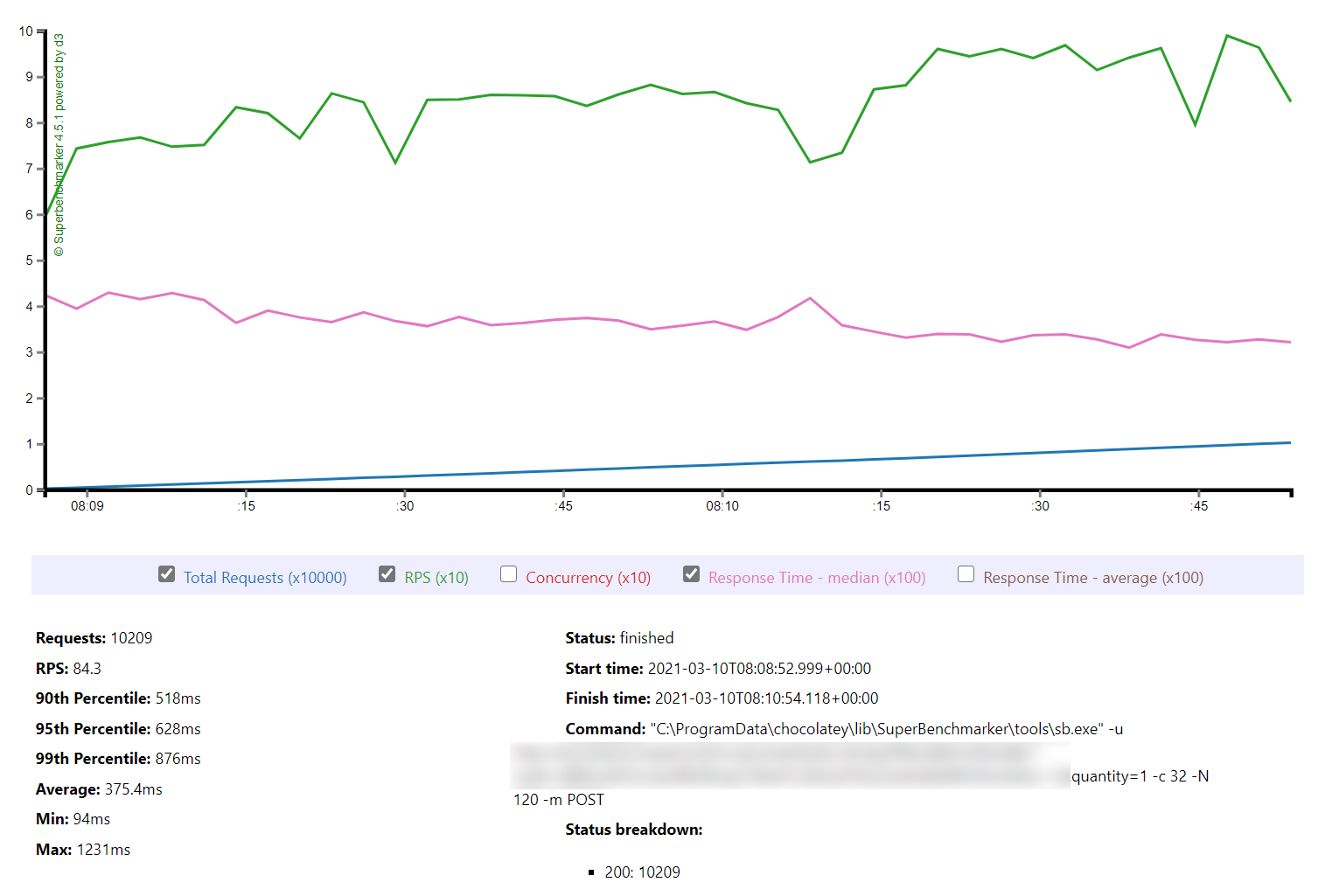
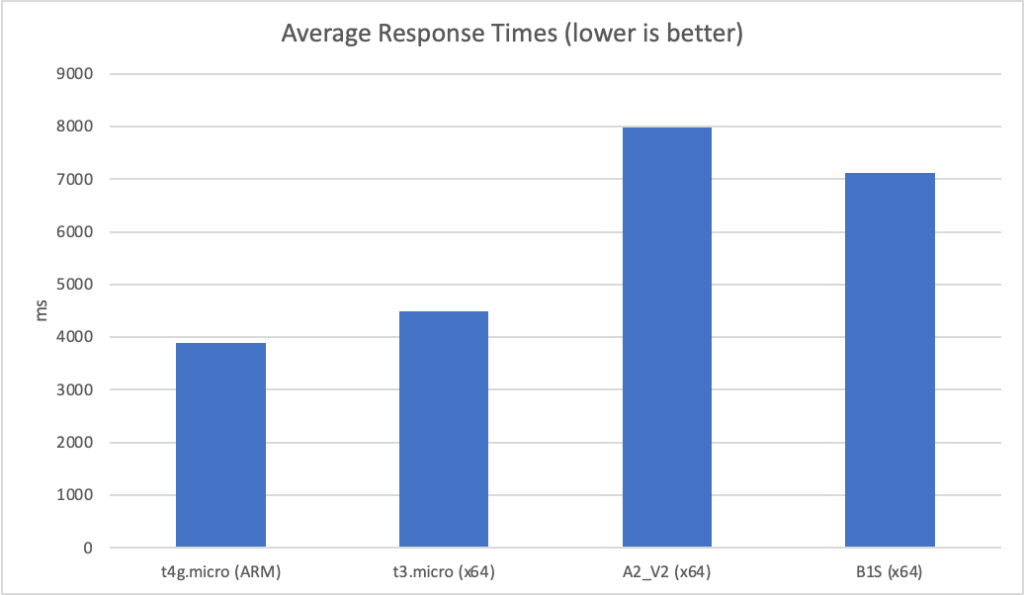
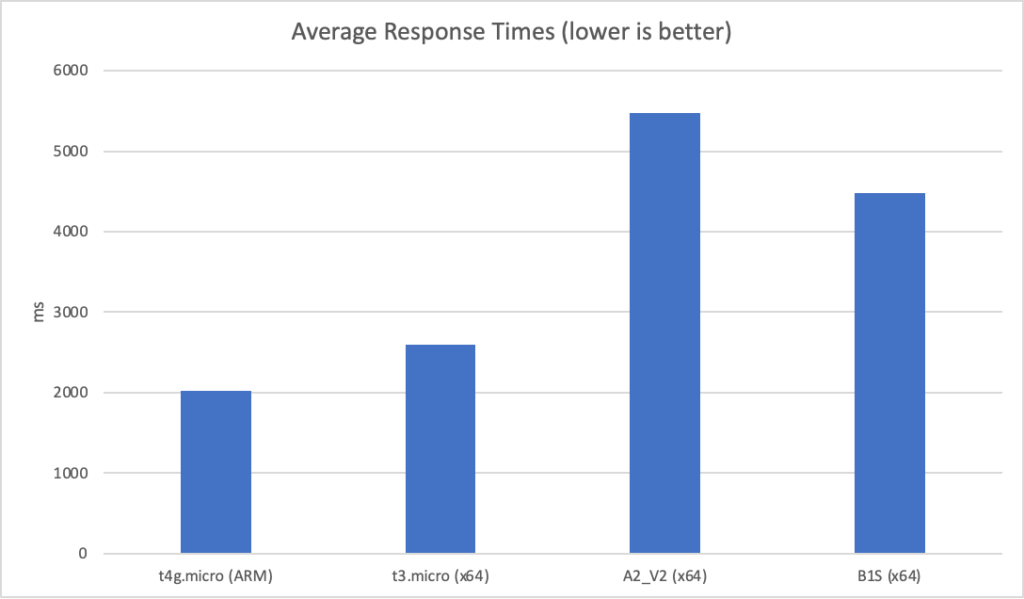
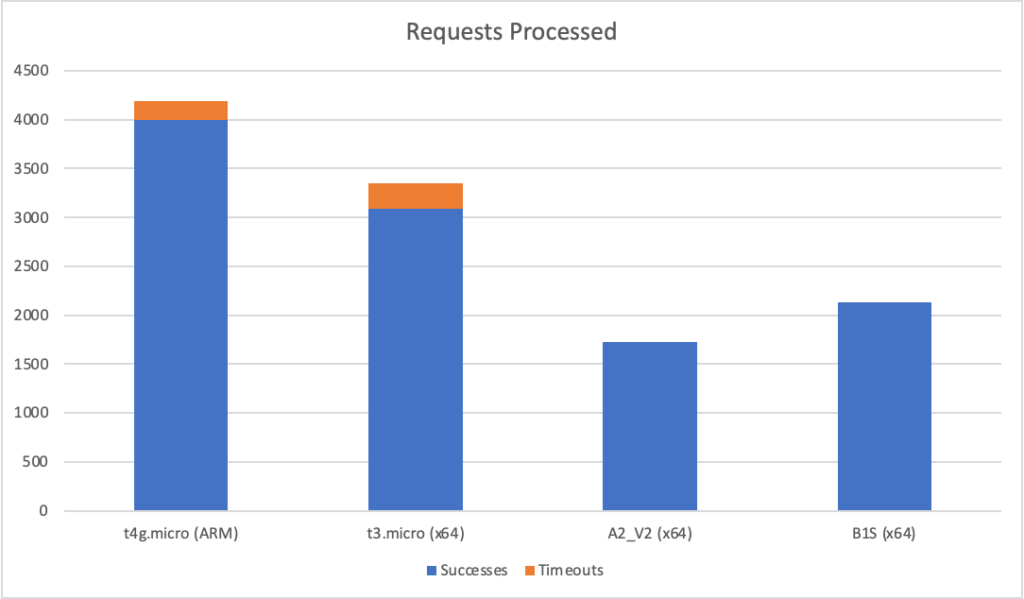
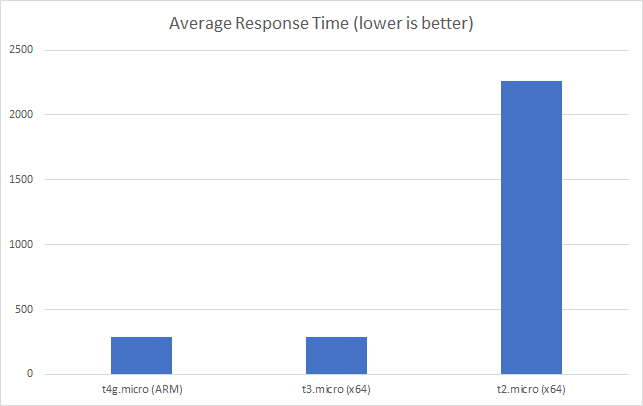
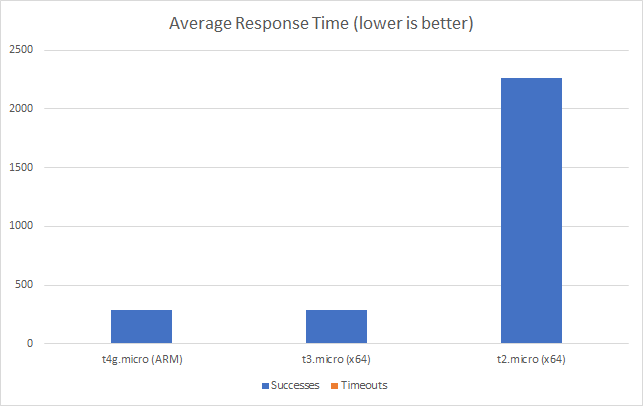
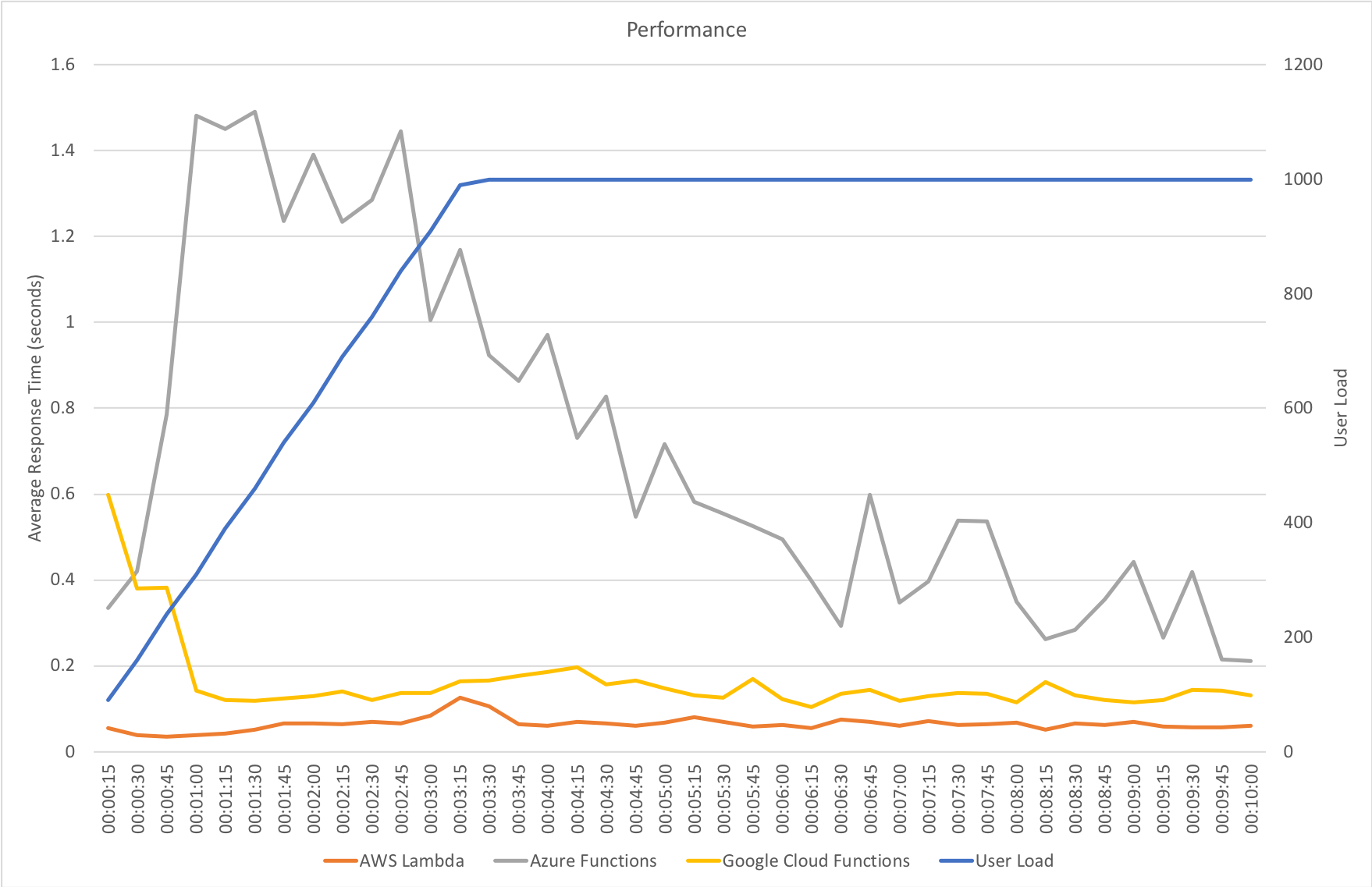
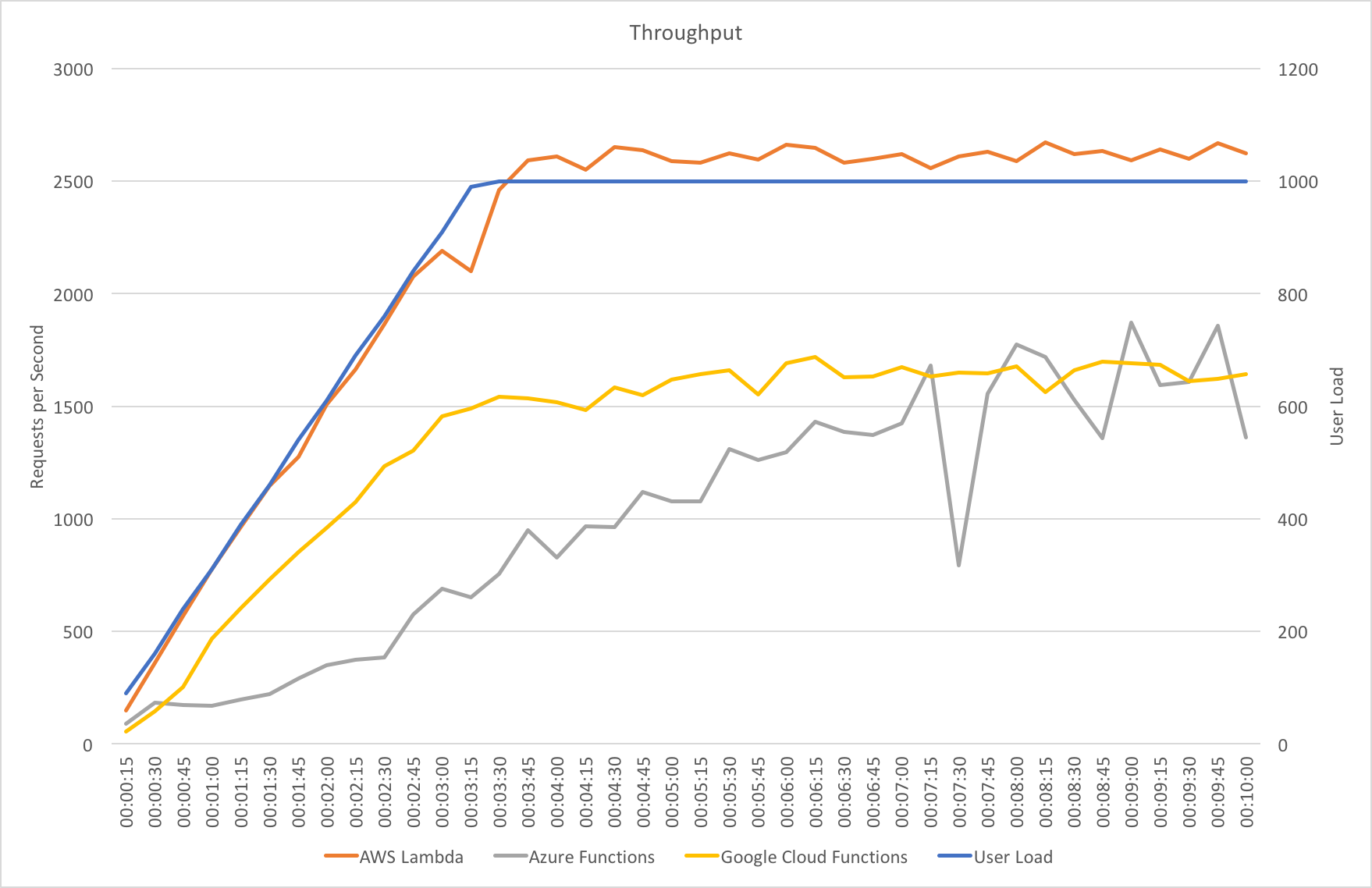
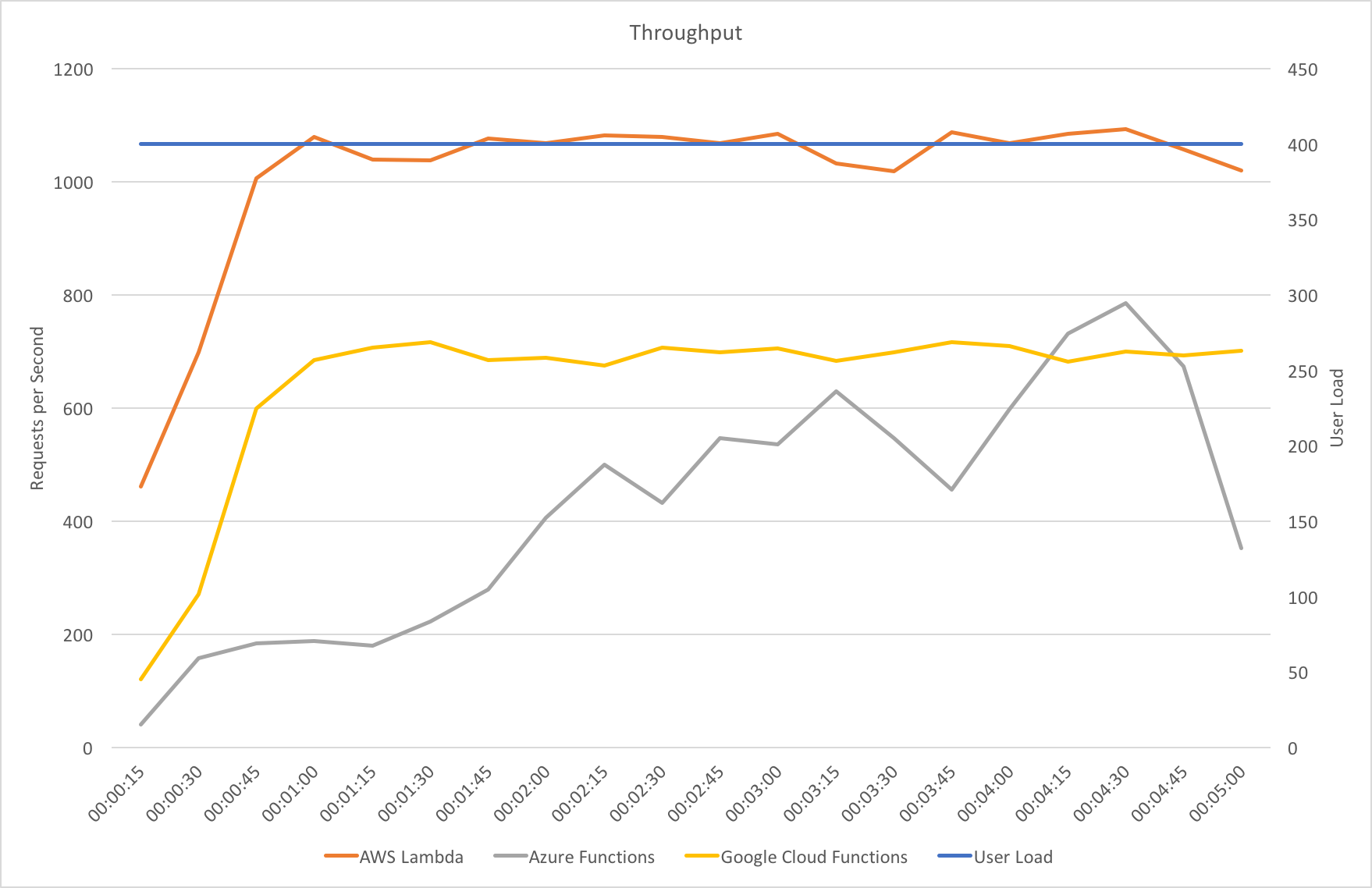
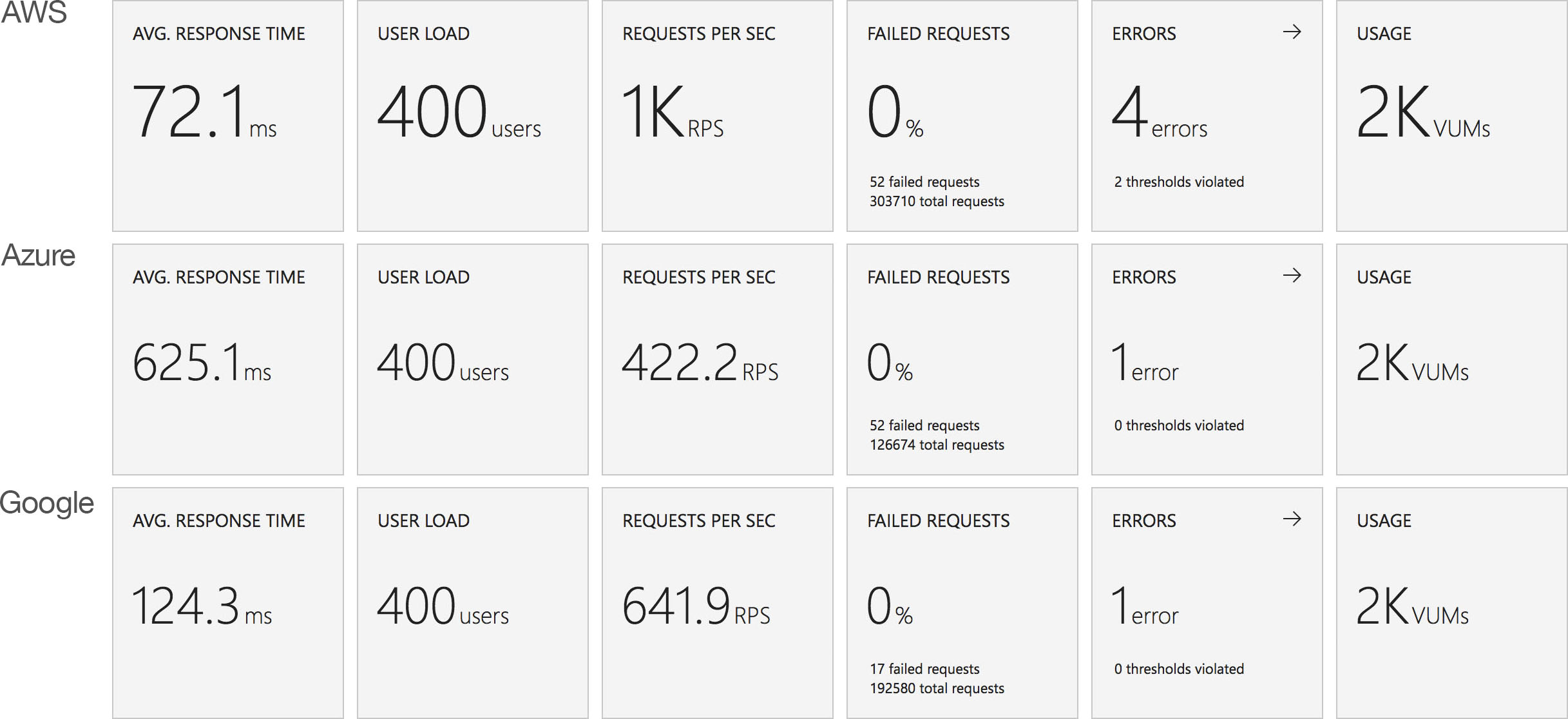
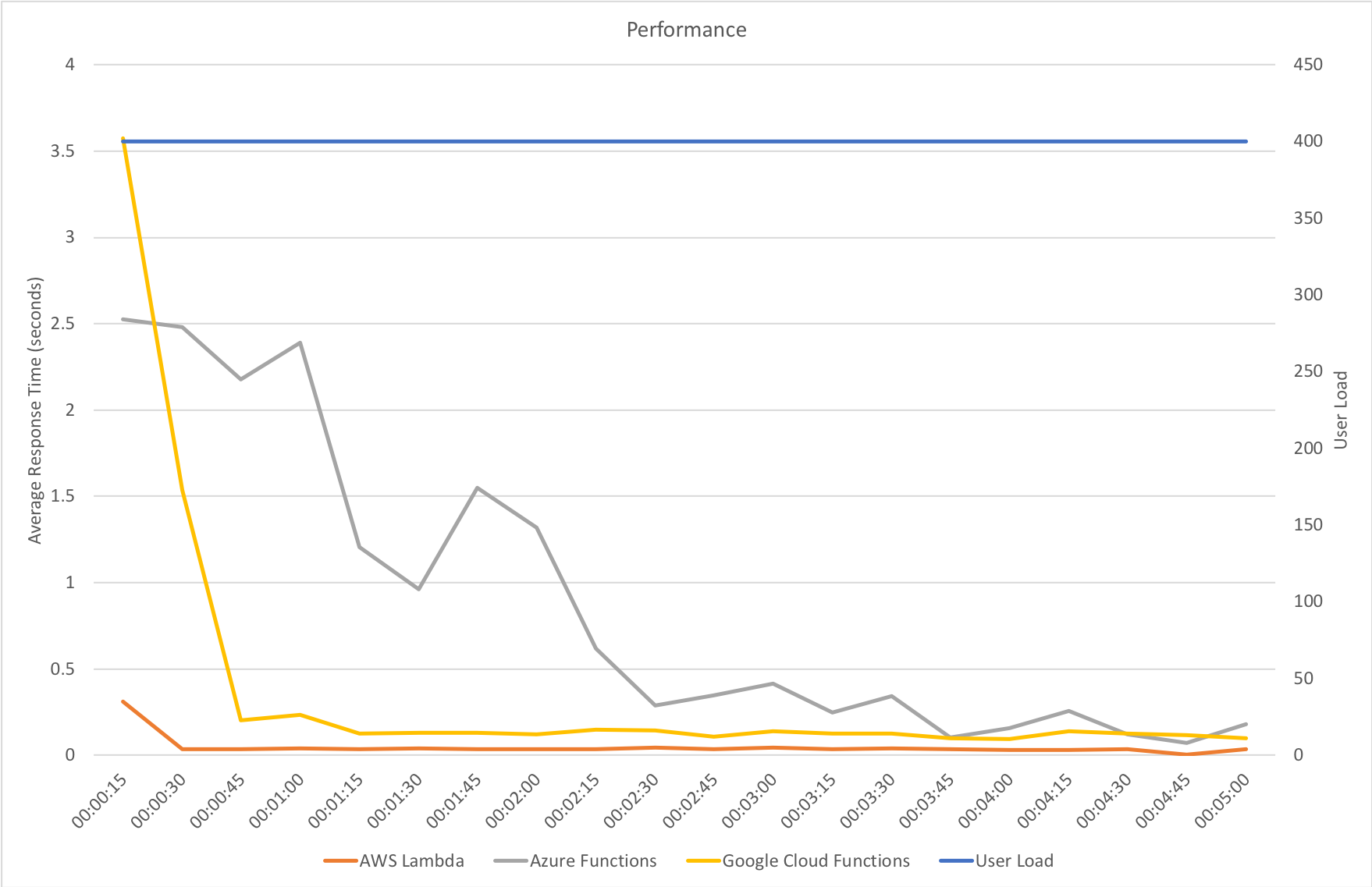
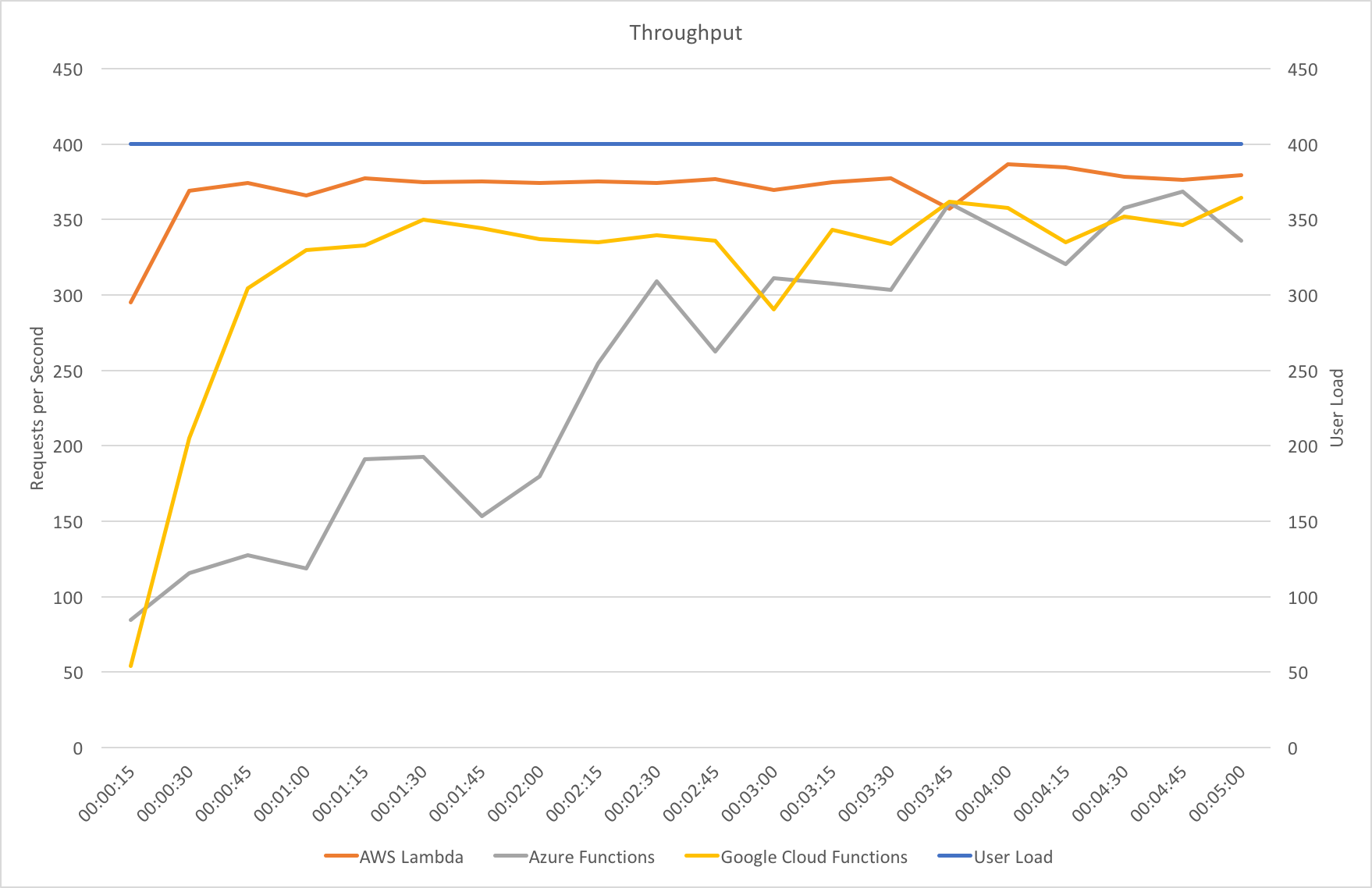
Constant Load of 1000 Concurrent Users
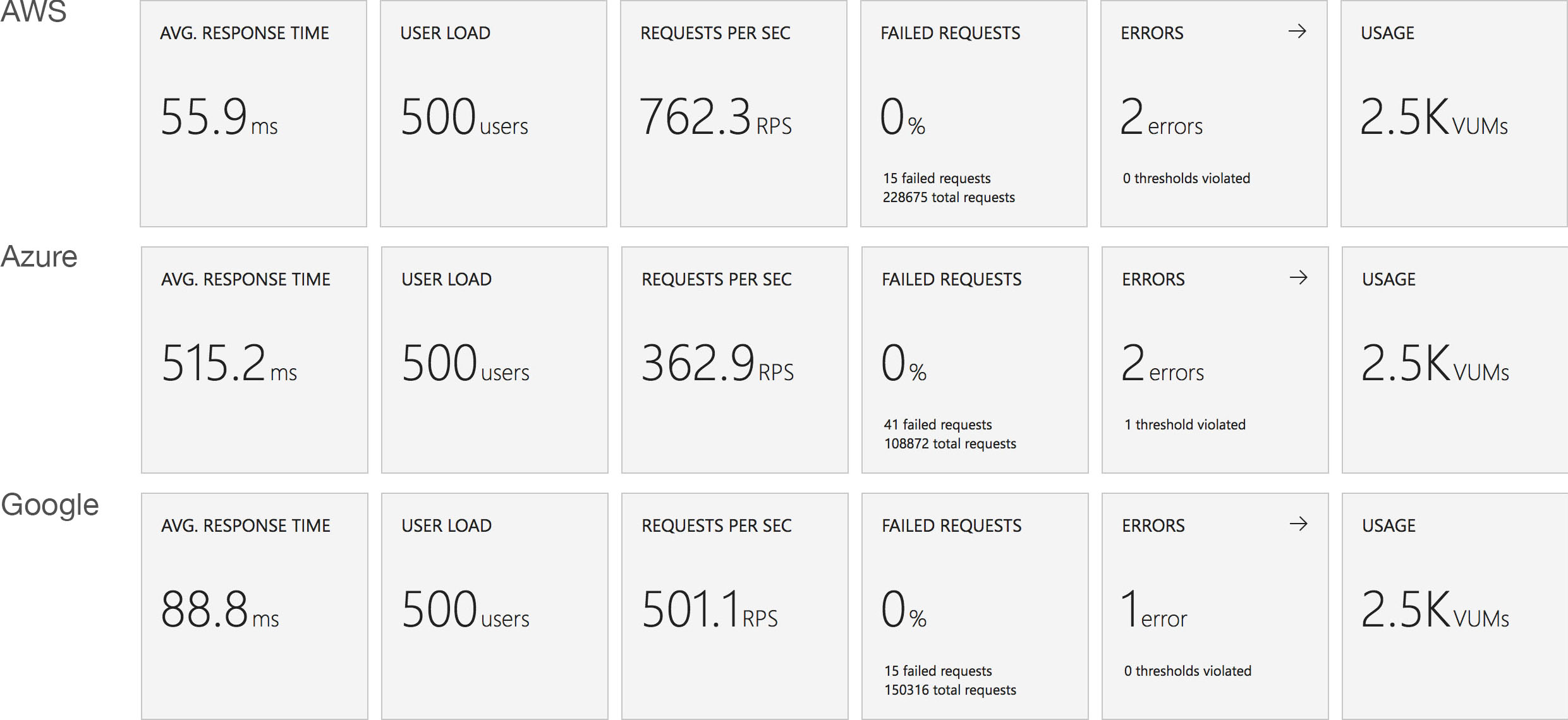
Same scenario as the last test but this time 1000 users. Lets get into the data:
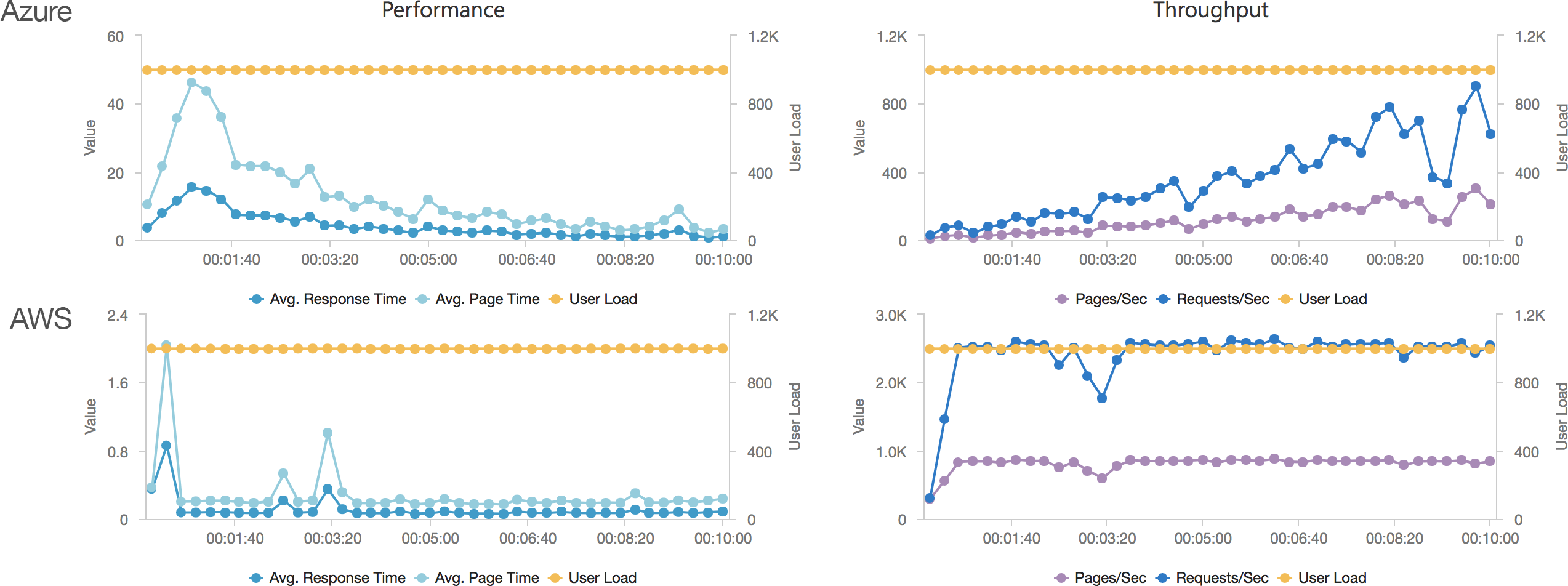
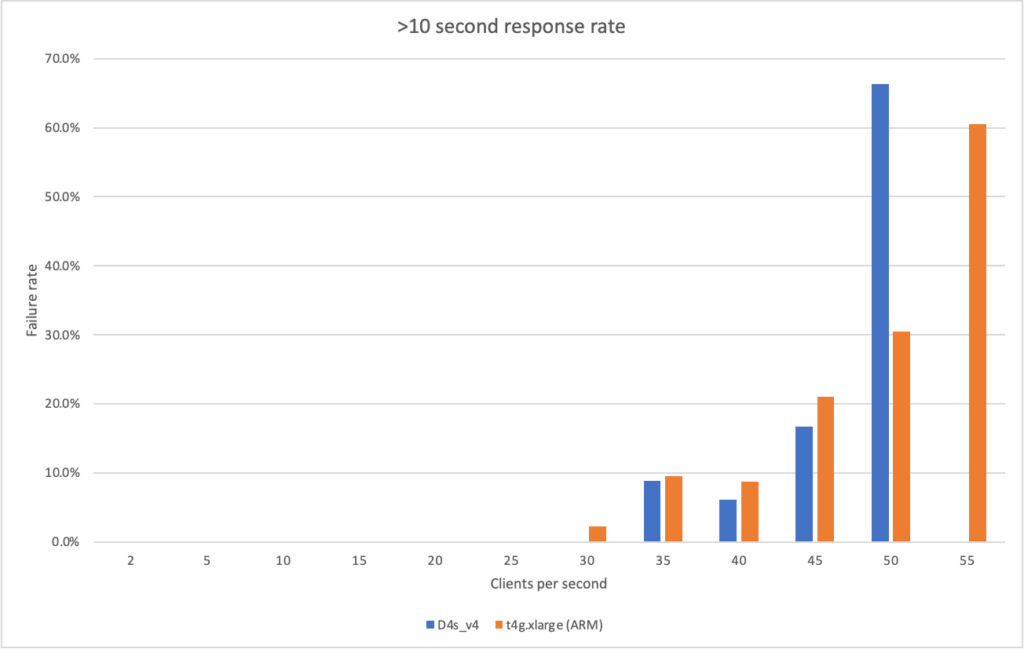
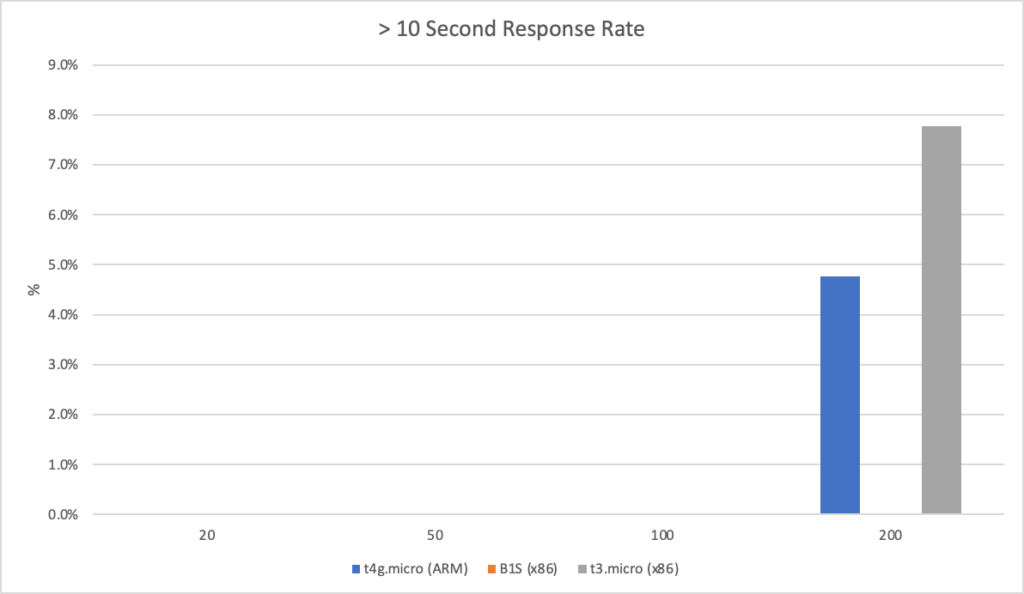
Again we can see a similar pattern with Azure slow to scale up to meet the demand while with AWS it is business as usual in under a minute. Interestingly at this level of concurrency AWS also error’d heavily during the early scaling:
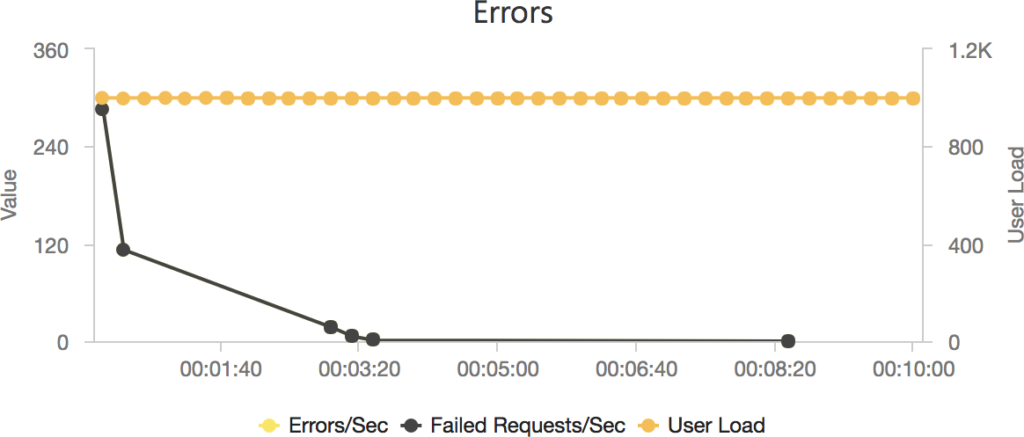
It should be noted that AWS specifically instructs you to implement retry and backoff handlers on the client which in the load test I am not doing, additionally at this point I am seeing throttle events in the logging for the AWS function – this is something I will look to come back to in the future. However its interesting to note the contrasting approaches of the two systems: Azure inflates it’s response time while AWS prefers to throw errors.
The average stats for the run:
Azure Functions
I don’t think there’s much point dancing around the issue: the above numbers are disappointing. Azure is slow to scale it’s HTTP triggered functions and once we get beyond the 100 concurrent users point the response times are never great and the experience is generally uneven. For customer facing API / web serving where low latency and response time are critical to a smooth user experience this really rules it out as an option. And it’s not just the .NET 4.6 variant that is poor as can be seen from my previous posts where I stripped test cases down to the most basic scenarios and used a variety of frameworks. The best case for Azure scaling I’ve found is using a CSX approach to return a string but even that lags behind AWS doing real work as the test cases in this post do:
using System.Net;
public static async Task<HttpResponseMessage> Run(HttpRequestMessage req, TraceWriter log)
{
log.Info("C# HTTP trigger function processed a request.");
var response = req.CreateResponse();
response.StatusCode = HttpStatusCode.OK;
response.Content = new StringContent("<html><head><title>Blog</title></head><body>Hello world</body></html>", System.Text.Encoding.UTF8, "text/html");
return response;
}
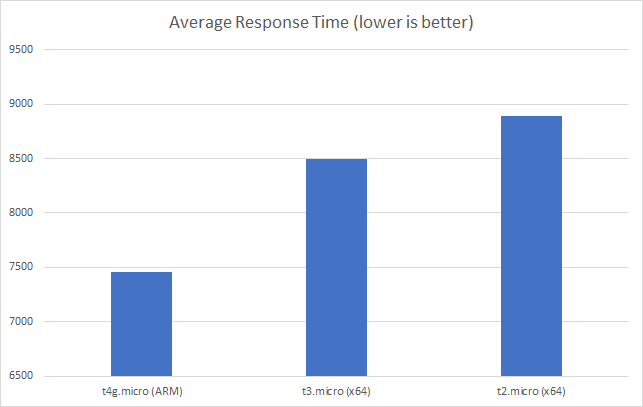
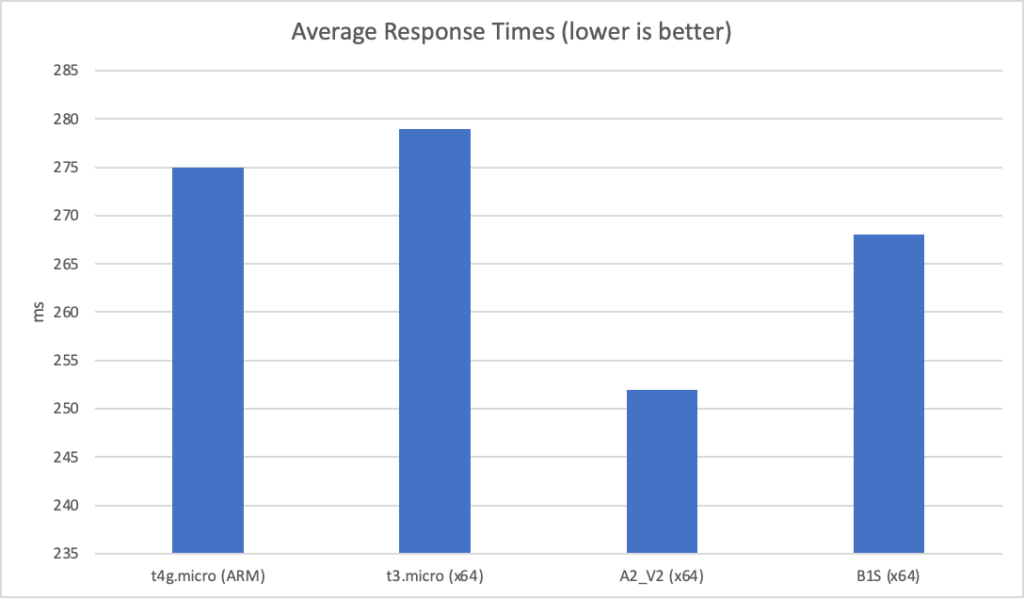
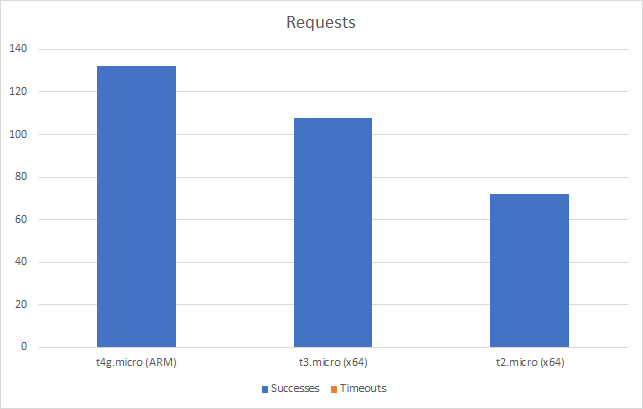
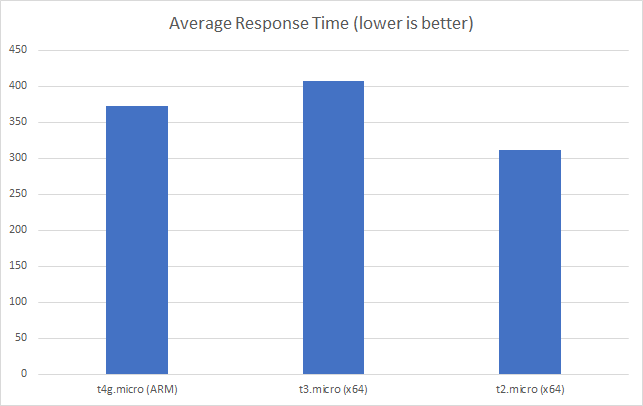
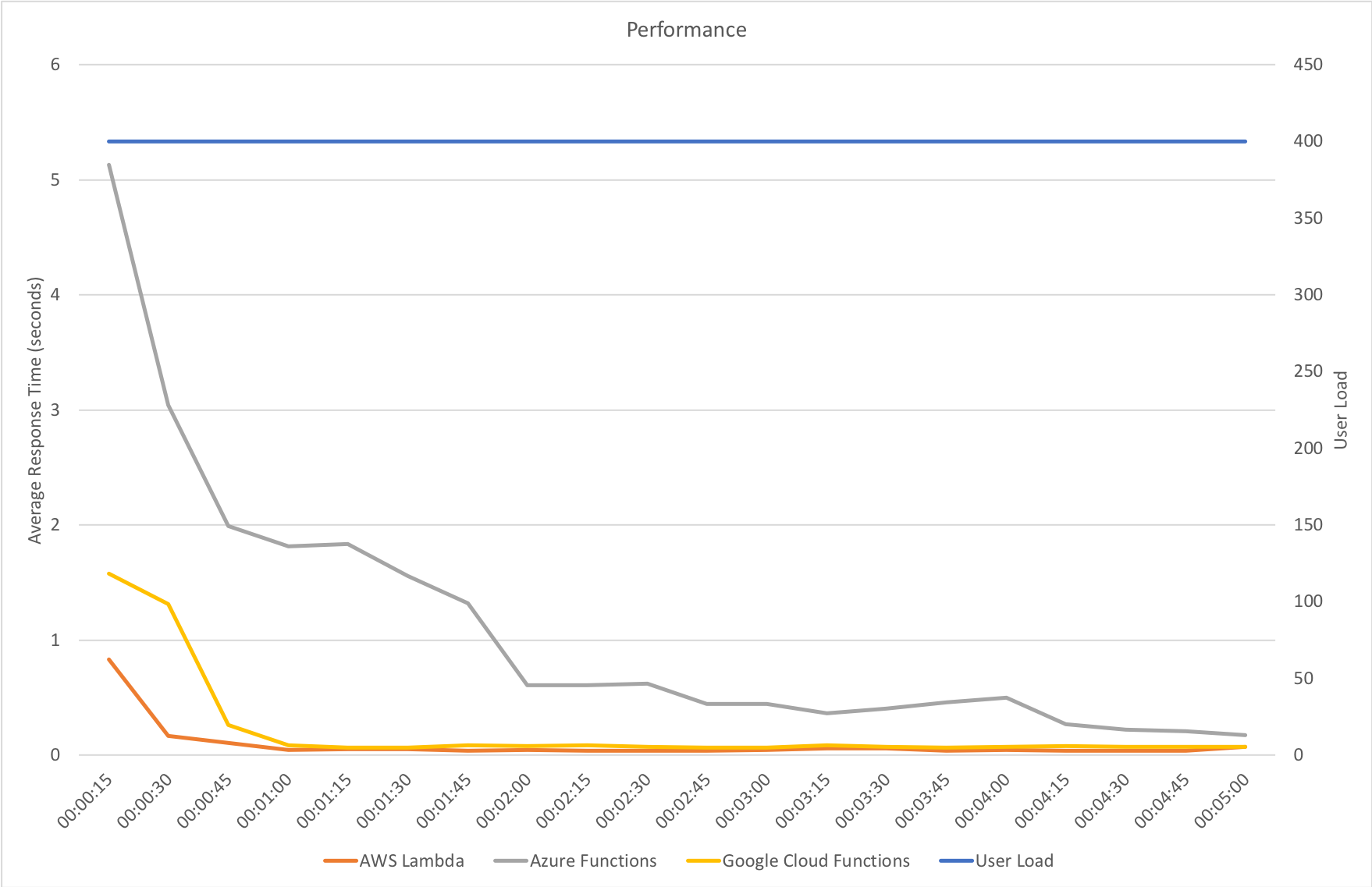
With 1000 concurrent users over 5 minutes:
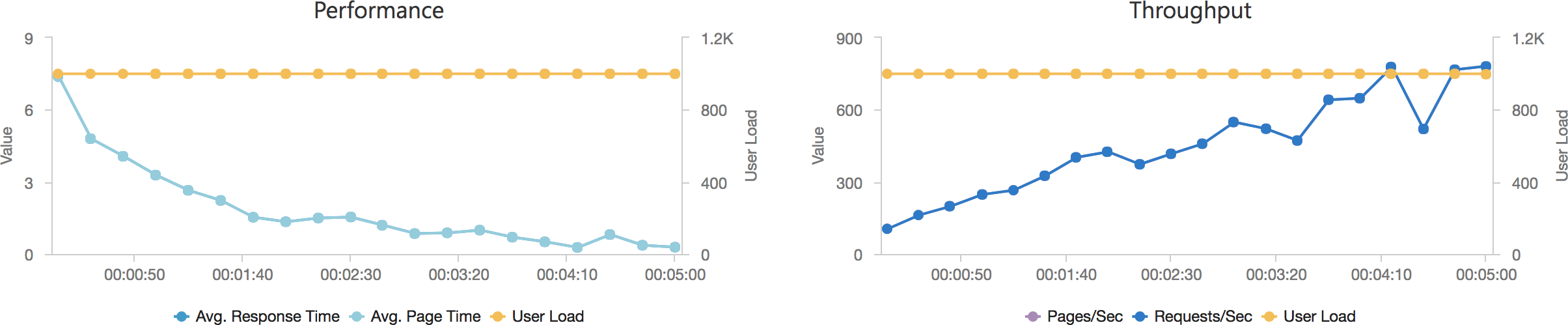

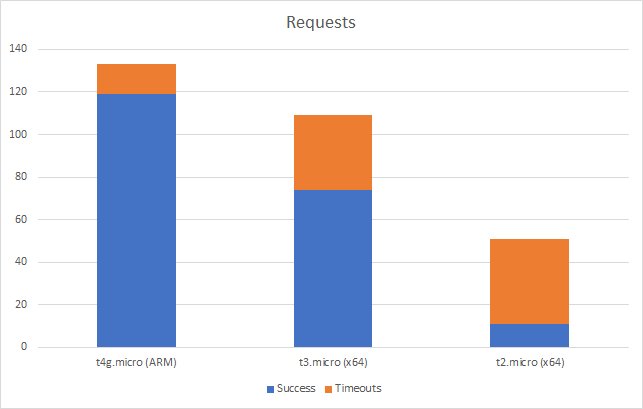
And with the add 2 users per second scenario:
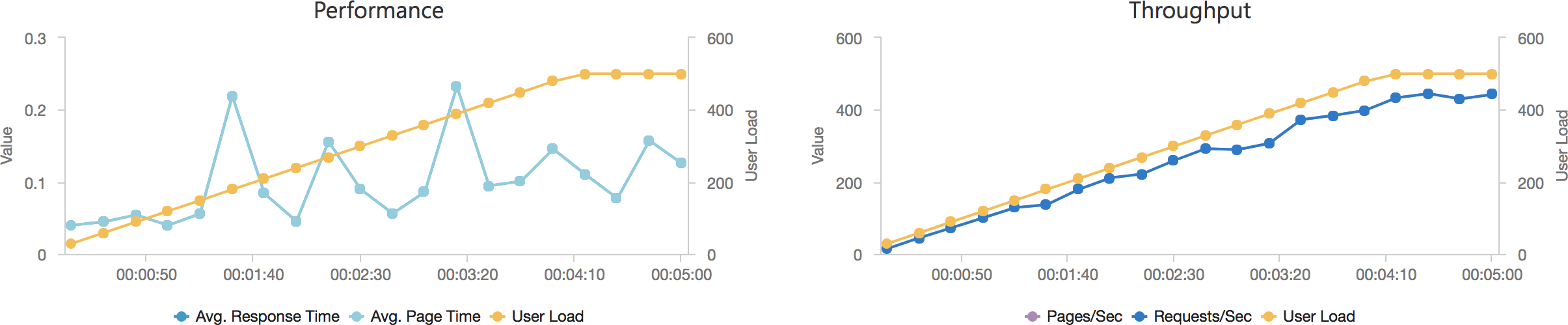

Even in this final case, and remember this Azure Function is only returning a string, we can see the response time creeping up as the user load increases and the total number of requests served is only 77514 to AWS’s 215271 over the same period with a much lower number of requests per second.
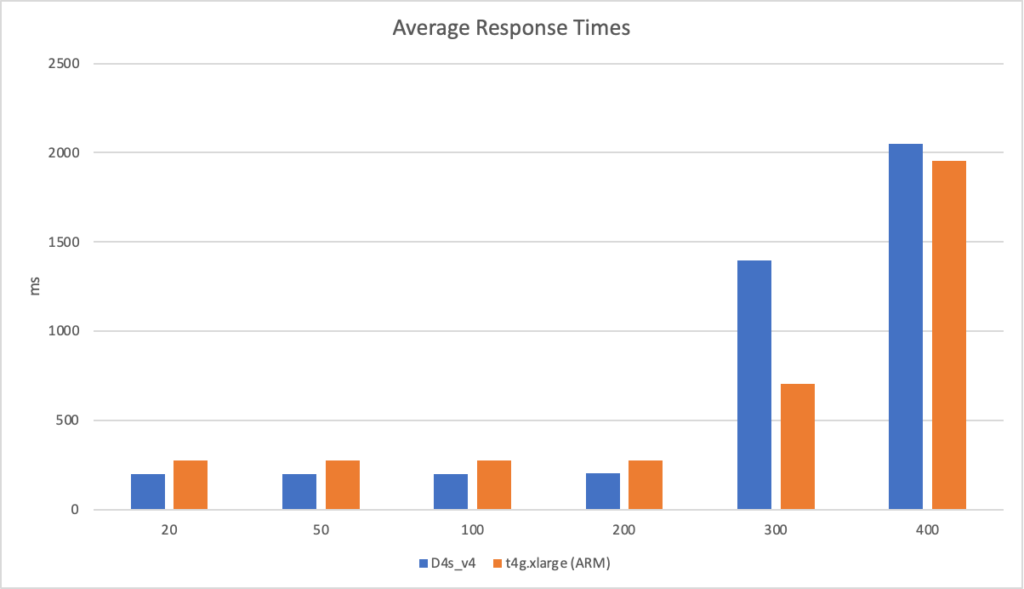
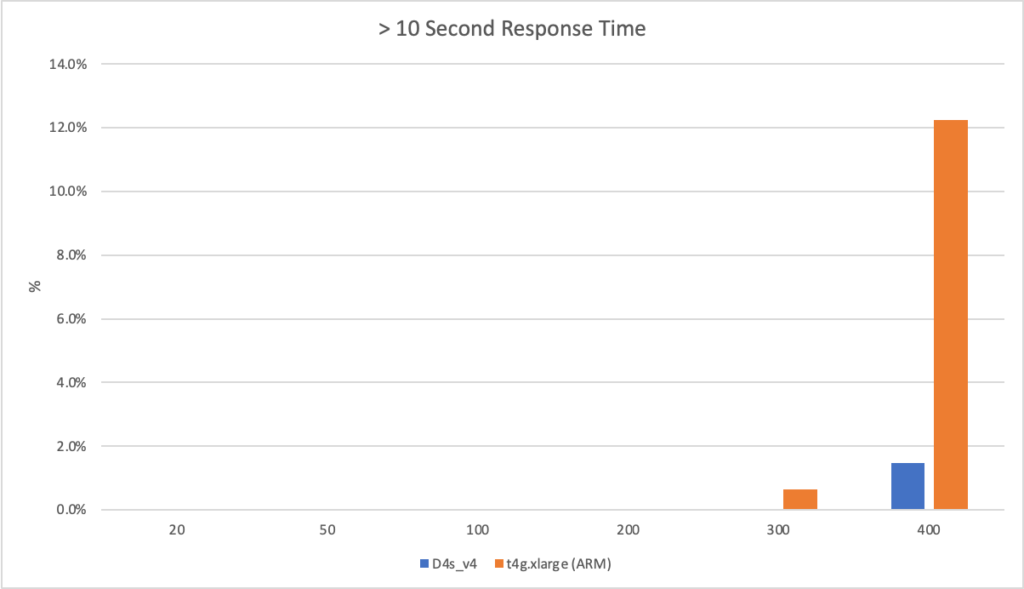
In an additional attempt to validate my conclusion that the Azure Function system is poor at scaling I pointed the AWS Lambda installation at Azure Blob Storage instead of S3. In this test other than the function entry point semantics the code running on AWS is now taking exactly the same branches as the Azure tests and using the same underlying storage mechanism, albeit with a hop across the Internet to access the storage. I ran this scenario using the 400 concurrent user scenario:
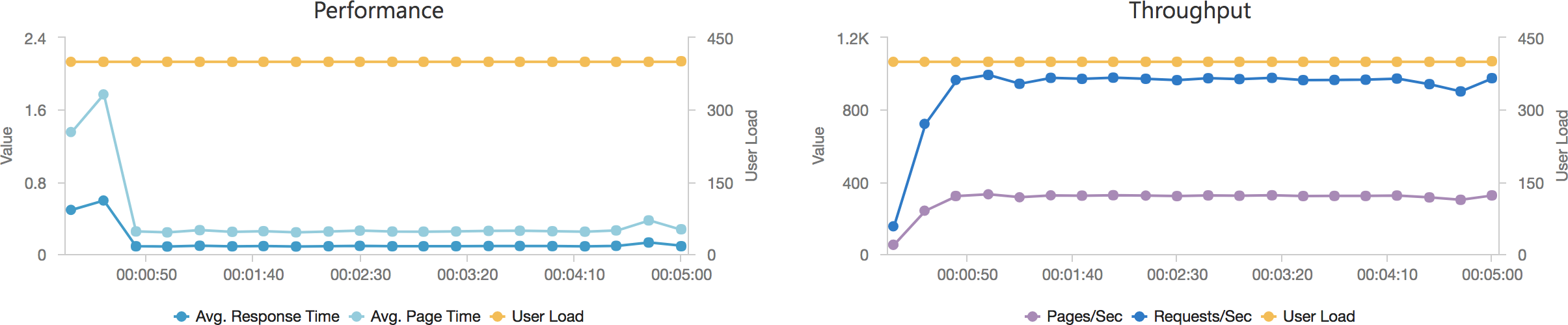

We can see from this that other than a slightly increased response time due to the storage being hosted in another data centre AWS continues to perform well and scales up almost immediately and response time remains steady and low. We can also see their is no issue with Azure Blob Storage – if there was an issue there we’d expect to see it impact these results.
With these additional validation tests (an empty workload and AWS running against Blob Storage) that pretty much isolates the issue to the Azure Function runtime.
And it’s a shame as the developer experience is great, there is solid documentation, and plenty of samples, and the development team on Twitter are ludicrously responsive – to the point that I feel bad saying what I need to say here. I will reach out to them for feedback.
Why is this the case? Well I’d suggest the root of the issue is how the system has been built on top of App Service Plans. It’s not all that, well, serverless and you still find yourself worrying about, well, servers.
On Azure an App Service Plan is essentially a collection of rented servers / reserved compute power of a given spec (CPU, memory) and capabilities. Microsoft have layered what they call a Consumption Plan over this for Azure Functions which provides for automatic scaling and consumption based pricing. Unfortunately if you track what is going on your Functions are running on a limited number of these servers which you can evidence by tracking the instance ID and by sharing state between your functions (to be clear: this is not good!).
Essentially the level of granularity for scaling your functions remains, as in a traditional hosting model, at the server level and as your system scales up instances are slowly being added – but this is throttled tightly presumably to prevent Microsoft’s costs from spiralling out of control.
Now because they run on Application Service Plans you can switch hosting away from the Consumption plan onto a standard plan (which allows additional Azure features to be used) but this, to me, completely defeats the point of serverless. I’m paying for reserved compute again and managing server instance counts. I may as well not have bothered in the first place!
It’s hard to escape the feeling that Microsoft had to play catch up with AWS Lambda (it launched as a preview in late 2014 and went into general release in April 2015 whereas Azure Functions launched as a preview in March 2016 ) and built something they could market as serverless computing as quickly as they could by reusing existing compute and scaling systems on Azure.
Would I still use Azure Functions? Yes sure – in back end scenarios where latency isn’t all that important they’re a great fit. Anything that impacts user experience? No. Definitely not at this point.
It will be interesting to see if Microsoft revise the hosting model, I suspect if they do it’s some time off as currently they seem focused on the v2 runtime which isn’t a hosting change (as far as I can see) but rather giving Functions the ability to support more languages and .NET Core.
AWS Lambda
I’ll preface this by saying I am absolutely not an AWS expert so it’s harder for me to speculate about the underlying architecture of Lambda however… the numbers don’t lie: AWS manages to respond to changes in demand very quickly and, until I started to hit throttle limits (which I would need to speak to AWS Support to have lifted), is very consistent in response times.
I’ve not tried any state sharing but I would expect it to fail: it looks like Amazon have containerised at the Function level, rather than the host server, and this is what allows them to operate as you’d expect a serverless environment to. Both scaling and billing can then be at the function level.
Would I use AWS Lambda? Yes. But as most of my development work is on Azure I’m really hoping Microsoft bridge the capability gap.
Wrap Up and Next Steps
If you’ve followed this far – thanks! I’m a big fan of the serverless model but the Azure implementation of serverless looks like something of a compromised offering at this point and I’d be cautious of recommending it without understanding in detail the usage requirements as you will quickly hit choppy water.
I am planning on repeating similar experiments with the queue processing I began some time ago and if I get any information from Microsoft around this topic will make any corrections as appropriate. This is one of those times I’d love to have got things wrong.


















Recent Comments