As part of migratingPerformance for Cyclists to AWS I’ve been exploring the use of Pulumi to manage the infrastructure running through GitHub Actions when I commit code (targetting dev) or to live (when I create a release). To do this I’m using the Pulumi GitHub Action available in the marketplace.
This has been fairly straightforward if a little verbose compared to Farmer (which I use to do the same with Azure) – with one exception: using a Pulumi Stack Output in a subsequent GitHub Action step. For example passing the URL of a provisioned application load balancer on to an acceptance test suite or the endpoint for a database that I want to run a migration on.
I scratched my head for a while before stumbling on the secret to doing this in a GitHub Issue. It took a little bit of tweaking to get it actually working due to the way the Pulumi Action wraps the output command – it was a bit fiddly getting the escape sequences right. In any case here are the steps.
Firstly after your pulumi up step add a step that looks like this:
Its important your step has an ID so that you can reference it subsequently. Now lets assume one of your output variables is ApiUrl then you would consume it like the below (just showing it in a dotnet run type command):
- name: Test endpoint
run: dotnet run -- ${{ steps.pulumiStackOutput.outputs.ApiUrl }}
This seems a common task in a real world CI / CD pipeline to me so its surprising that its not supported directly in the Action. As best I can tell (and I looked in the source) it doesn’t seem to be though Pull Requests have been created for it back in April. Hopefully they’ll add this capability soon as it feels very sticking plaster and over-complex without. Really I just want to be able to add an option like PULUMI_EXPOSE_OUTPUTS in the example below:
- name: Infrastructure up
uses: docker://pulumi/actions
with:
args: up --yes
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
PULUMI_ACCESS_TOKEN: ${{ secrets.PULUMI_ACCESS_TOKEN }}
PULUMI_CI: up
PULUMI_ROOT: aws
PULUMI_EXPOSE_OUTPUTS: true
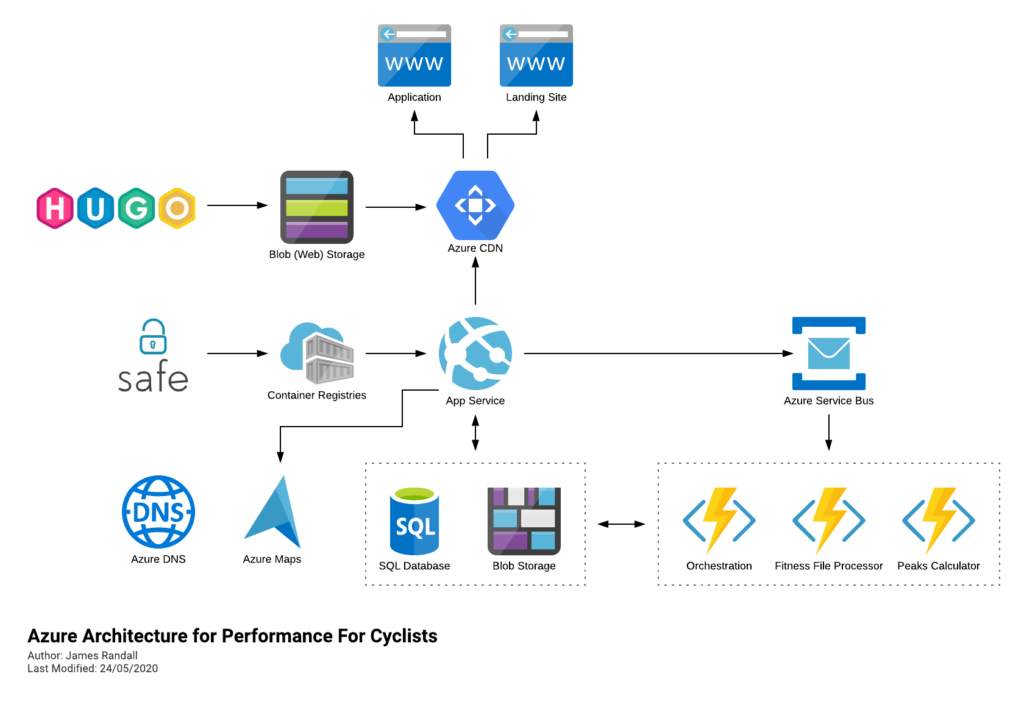
If you follow me on Twitter you might have seen that as a side project I run a cycling performance analytics website called Performance For Cyclists – this is currently running on Azure.
Its built in F# and deploys to Azure largely like this (its moved on a little since I drew this but not massively):
It runs fine but if you’ve been following me recently you’ll know I’ve been looking at AWS and am becoming somewhat concerned that Microsoft are falling behind in a couple of key areas:
Support for .NET – AWS seem to always be a step ahead in terms of .NET running in serverless environments with official support for the latest runtimes rolling out quickly and the ability to deploy custom runtimes if you need. Cold starts are much better and they have the capability to run an ASP.Net Core application serverlessly with much less fuss.
I can also, already, run .NET on ARM on AWS which leads me to my second point (its almost as if I planned this)…
Lower compute costs – my recent tests demonstrated that I could achieve a 20% to 40% saving depending on the workload by making use of ARM on AWS. It seems clear that AWS are going to broaden out ARM yet further and I can imagine them using that to put some distance between Azure and AWS pricing.
I’ve poked around this as best I can with the channels available to me but can’t get any engagement so my current assumption is Microsoft aren’t listening (to me or more broadly), know but have no response, or know but aren’t yet ready to reveal a response.
(just want to be clear about something – I don’t have an intrinsic interest in ARM, its the outcomes and any coupled economic opportunities that I am interested in)
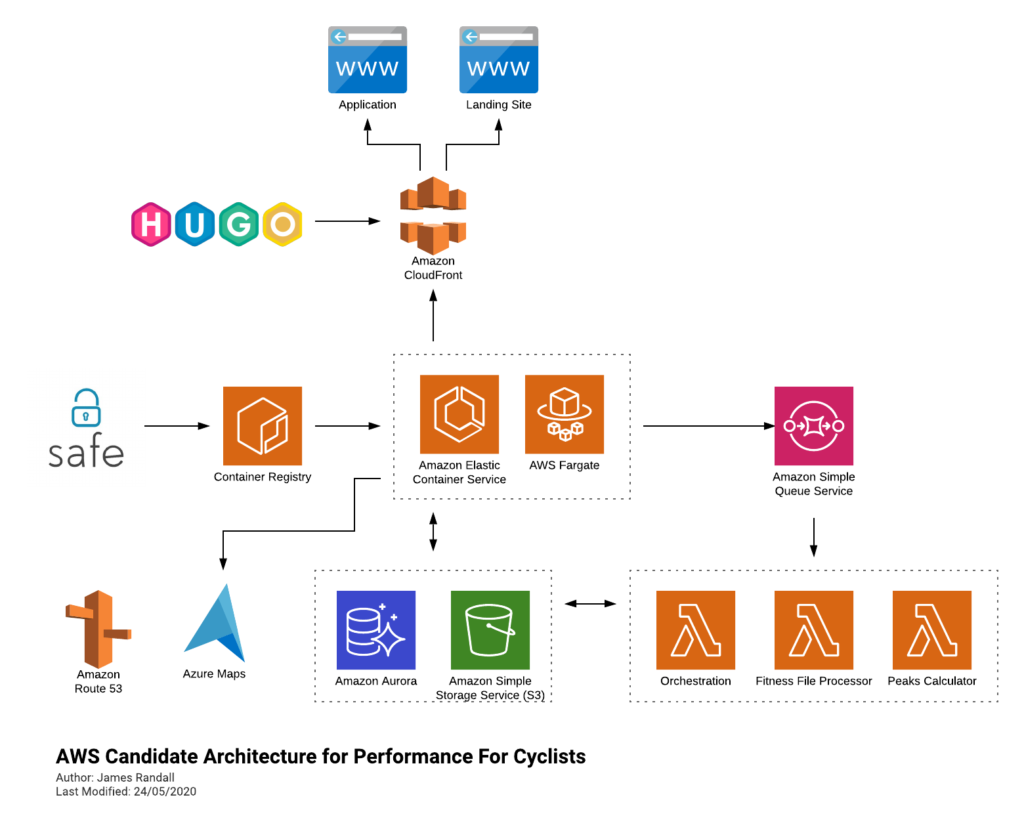
I’m also just plain and simpe curious. I’ve dabbled with AWS, mostly when clients were using it when I freelanced, but never really gone at it with anything of significant size.
I’m going to have to figure my way through things a bit, and doubtless iterate, but at the moment I’m figuring its going to end up looking something like this:
Leaving Azure Maps their isn’t a mistake – I’m not sure what service on AWS offers the functionality I need, happy to here suggestions on Twitter!
I may go through this process and decide I’m going to stick with Azure but worst case is that I learn something! Either way I’ll blog about what I learn. I’ve already got the API up and running in ECS backed by Fargate and being built and deployed through GitHub Actions and so I’ll write about that in my next post.
As I normally post from a developer perspective I thought it might be worth starting off with some additional context for this post. If you follow me on Twitter you might know that about 14 months ago I moved into a CTO role at a rapidly growing business – we’re making ever increasing use of the cloud both by migrating workloads and the introduction of new workloads. Operational cost is a significant factor in my budget. To me the cloud can be summarised as “cloud = economics + capabilities” and so if I have a similar set of capabilities (or at least capabilities that map to my needs) then reduction in compute costs has the potential to drive the choice of vendor and unlock budget I can use to grow faster.
In the last few posts I’ve been exploring the performance of ARM processors in the cloud but ultimately what matters to me is not a processor architecture but the economics it brings – how much am I paying for a given level of performance and set of characteristics.
It struck me there were some interesting differences across ARM, x86, Azure and AWS and I’ve expanded my testing and attempted here to present these findings in (hopefully) useful terms.
All tests have been run on CentOS Linux (or the AWS derivative) using the .NET 5 runtime with Apache acting as a reverse proxy to Kestrel. I’ve followed the same setup process on every VM and then run performance tests directly against their public IP using loader.io all within the USA.
I’ve run two workloads:
Generate a Mandelbrot – this is computationally heavy with no asynchronous yield points.
A test that simulates handing off asynchronously to remote resources. I’ve included a small degree of randomness in this.
At the bottom of the post is a table containing the full set of tests I’ve run on the many different VM types available. I’m going to focus on some of the more interesting scenarios here.
Computational Workload
2 Core Tests
For these tests I picked what on AWS is a mid range machine and on Azure the entry level D series machine:
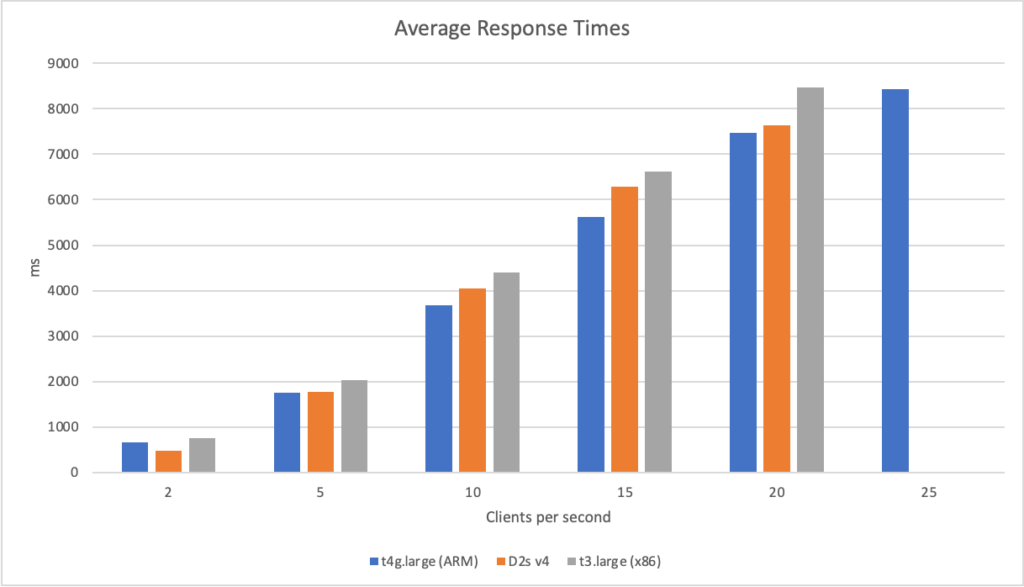
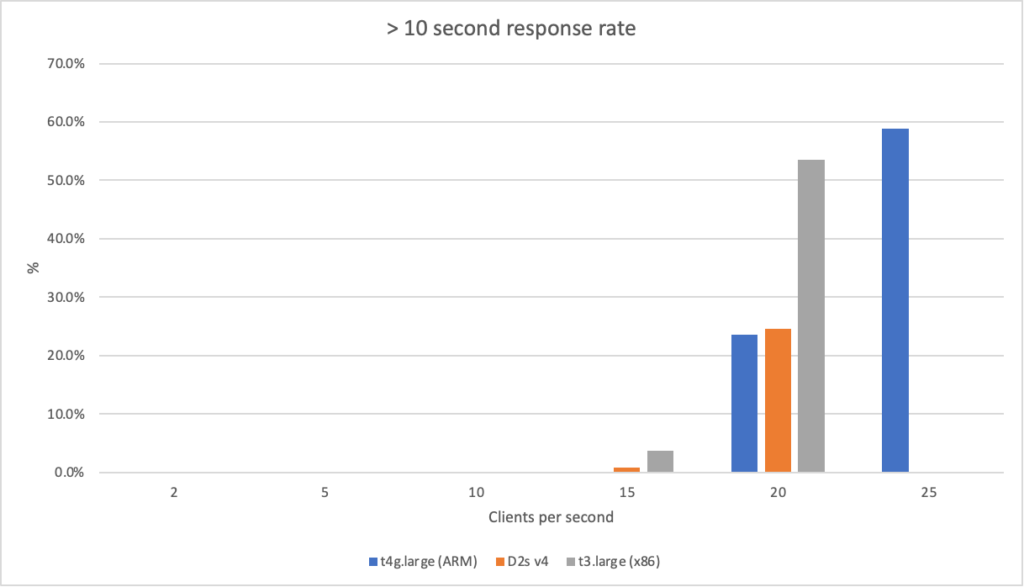
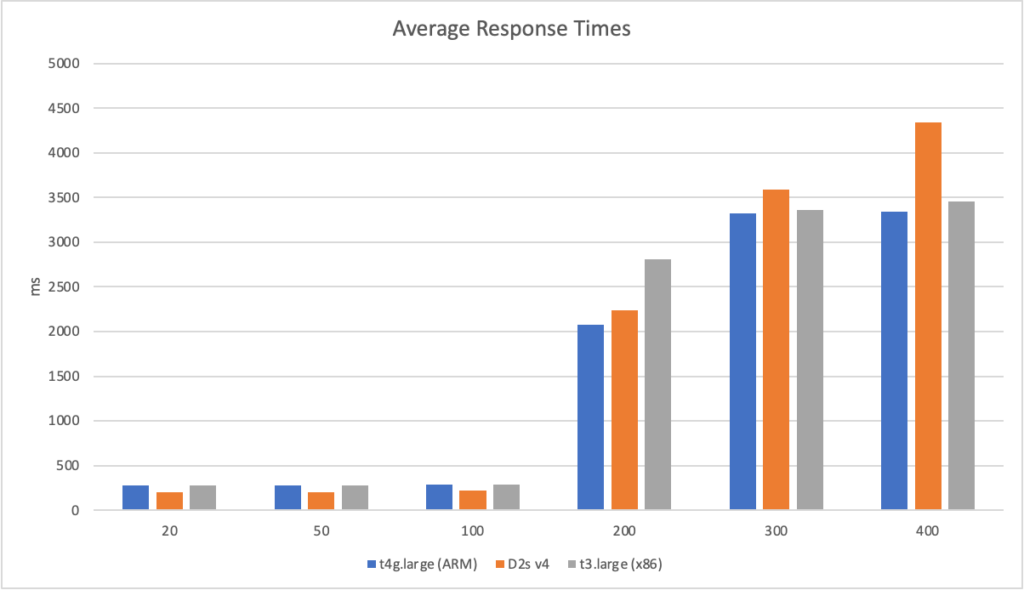
AWS (ARM): t4g.large – a 2 core VM with 8GiB of RAM and costing $0.06720 per hour AWS (x86): t3.large – a 2 core VM with 8GiB of RAM and costing $0.08320 per hour Azure (x86): D2s v4 – a 2 core VM with 8GiB of RAM and costing $0.11100 per hour
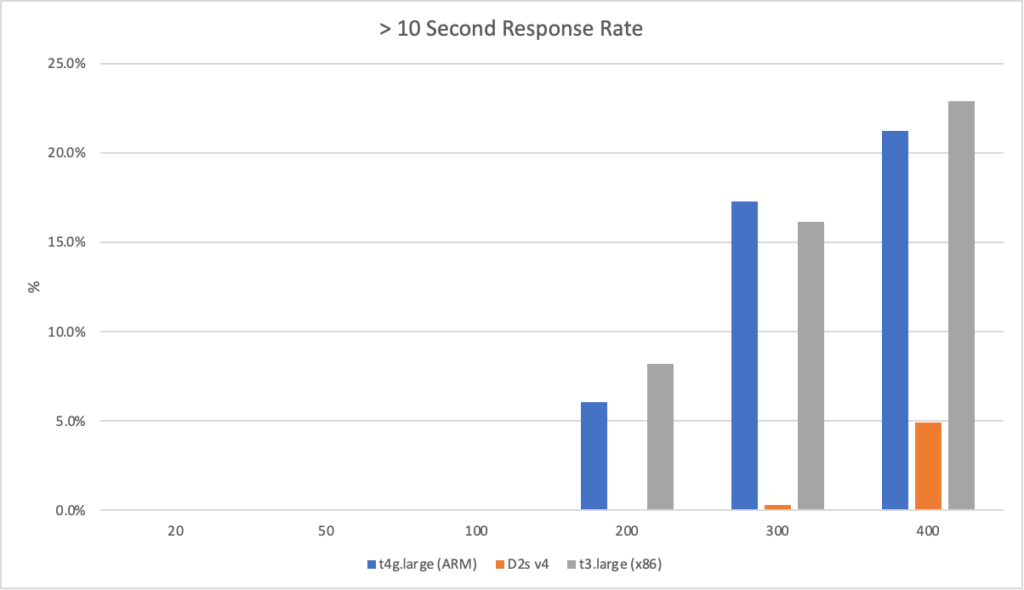
On these machines I then ran the workloads with different numbers of clients per seconds and measured their response times and the failure rate (failure being categorised as a response of > 10 seconds):
Both Intel VMs generated too many errors at the 25 client per second rate and the load tester aborted.
Its clear from these results that the ARM VM running on AWS has a significant bang for buck advantage – its more performant than the Intel machines and is 20% cheaper than the AWS Intel machine and 40% cheaper than the Azure machine.
Interestingly the Intel machine on AWS lags behind the Intel machine on Azure particularly when stressed. It is however around 20% cheaper and it feels as if performance between the Intel machines is largely on the same economic path (the AWS machine is slightly ahead if you normalise the numbers).
4 Core Tests
I wanted to understand what a greater number of cores would do for performance – in theory it should let me scale past the 20 client per second level of the smaller instances. Having concluded that ARM represented the best value for money for this workload on AWS I didn’t do an x86 test on AWS. I used:
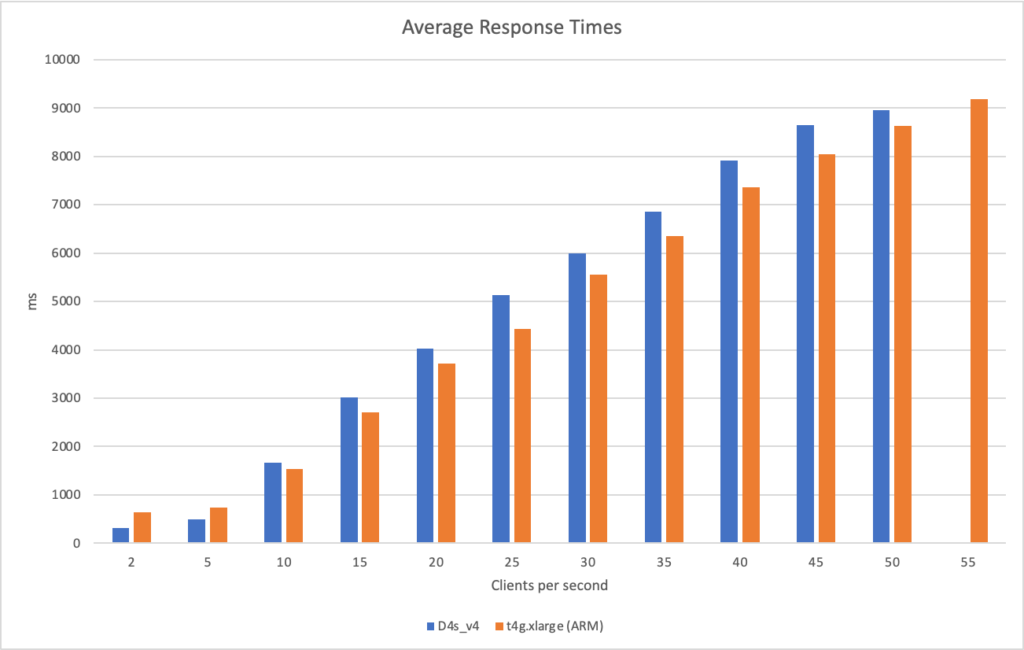
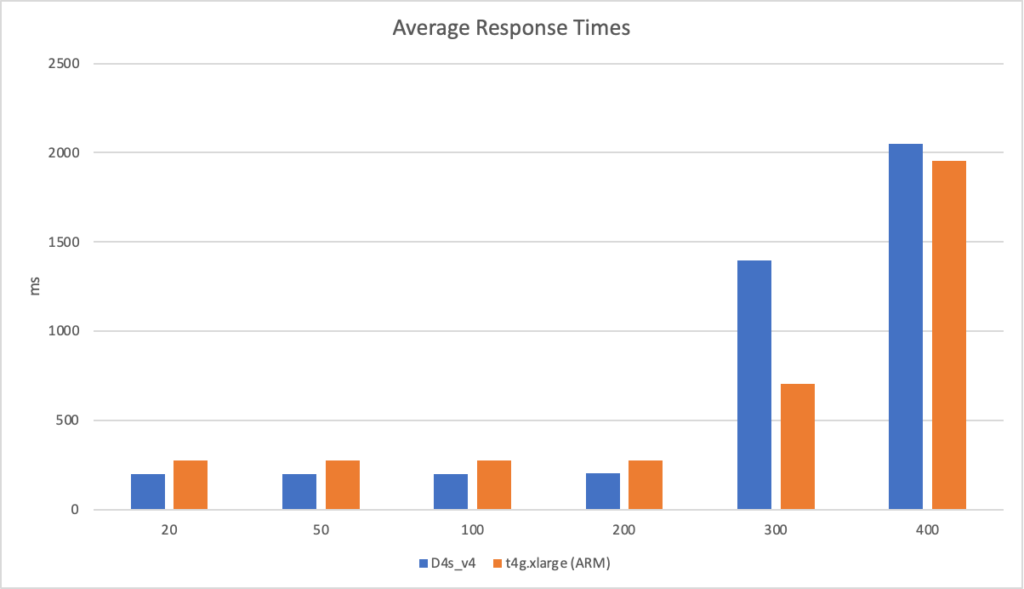
AWS: t4g.xlarge (ARM) – a 4 core VM with 16GiB of RAM and costing $0.13440 per hour Azure: D4s_v4 – a 4 core VM with 16GiB of RAM and costing $0.22200 per hour
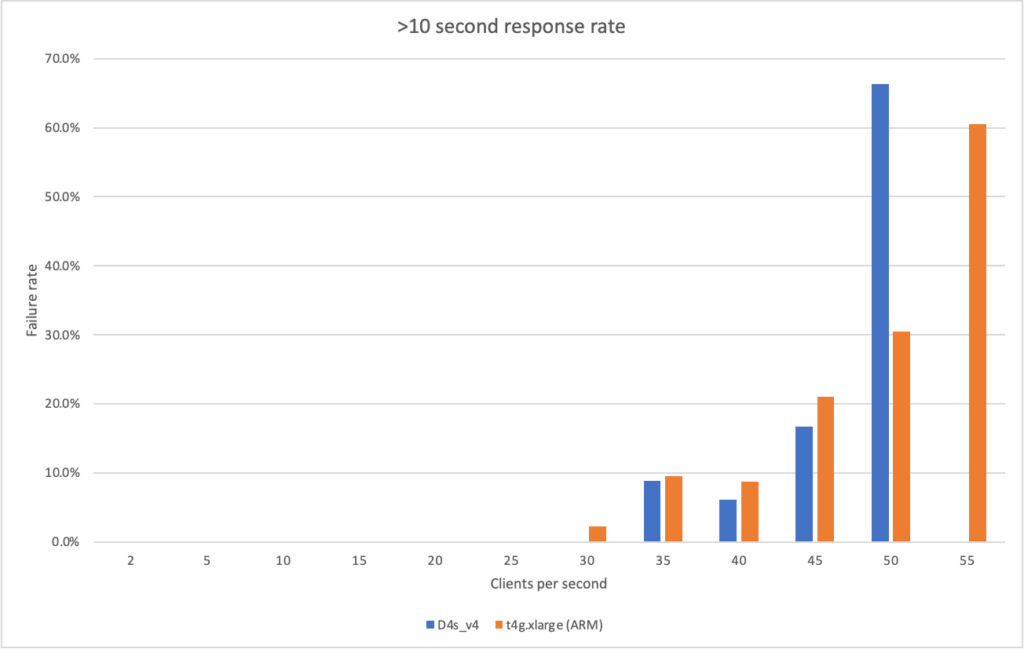
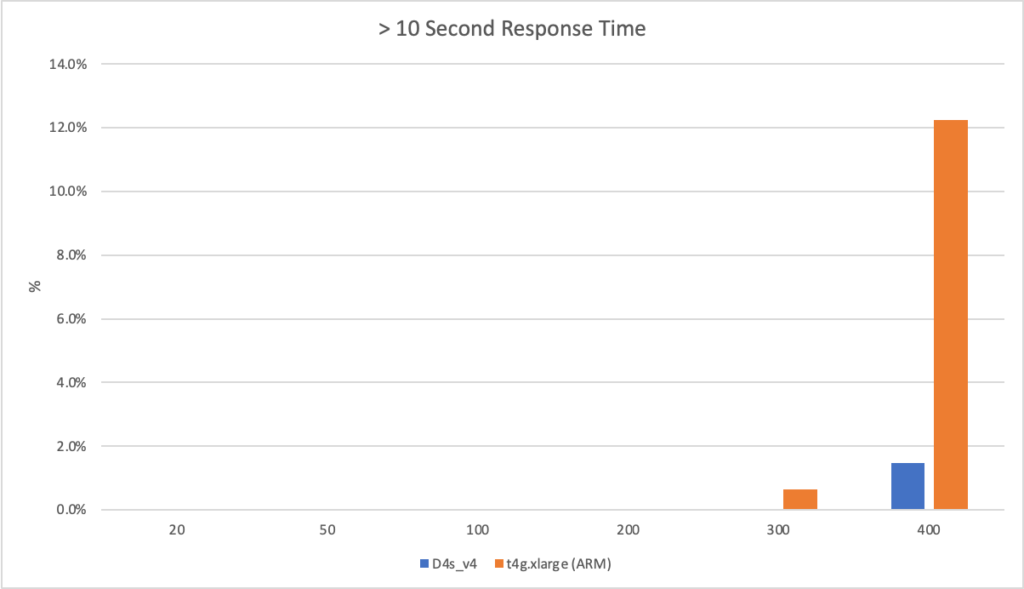
I then ran the workloads with different numbers of clients per seconds and measured their response times and the failure rate (failure being categorised as a response of > 10 seconds):
The Azure instance failed the 55 client per second rate – it had so many responses above 10 seconds in duration that the load test tool aborted the test.
Its clear from these graphs that the ARM VM running on AWS outperforms Azure both in terms of response time and massively in terms of bang for buck – its nearly half the price of the corresponding Azure VM.
Starter Workloads
One of the nice things about AWS and Azure is they offer very cheap VMs. The Azure VMs are burstable (and there is some complexity here with banked credits) which makes them hard to measure but as we saw in a previous post the ARM machines perform very well at this level.
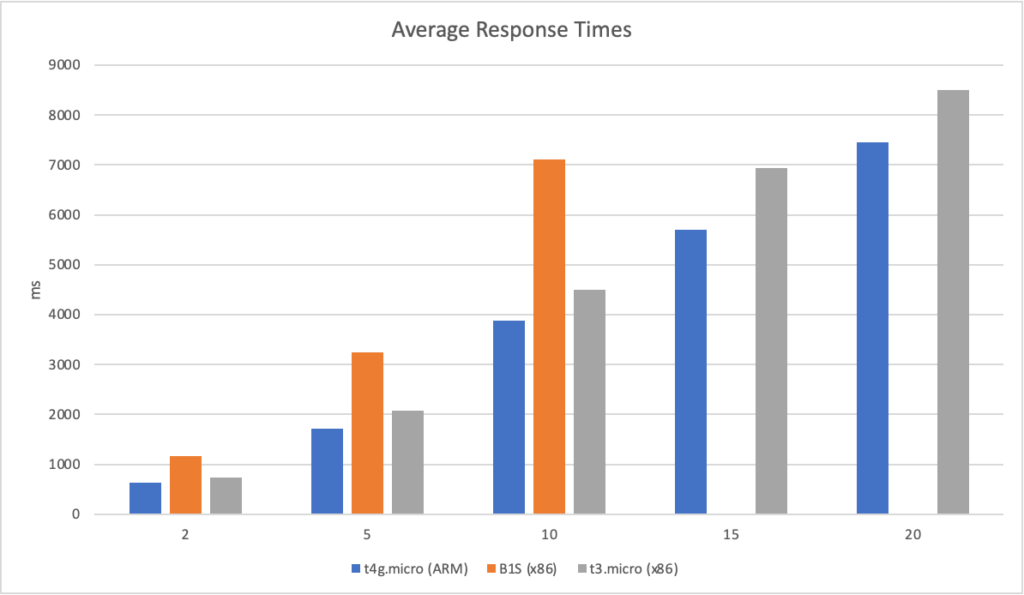
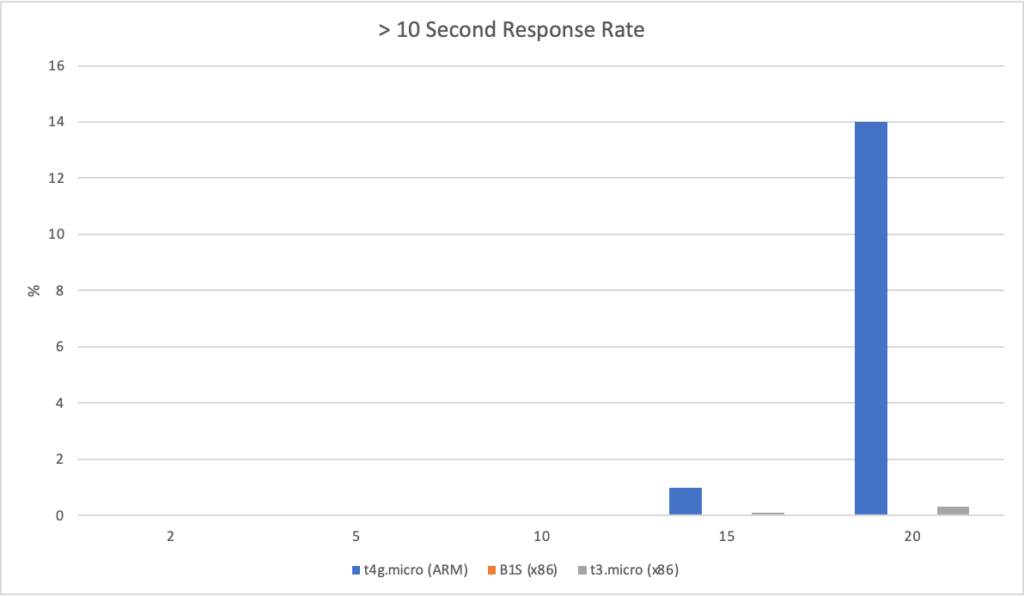
The three machines used are:
AWS (ARM): t4g.micro, 2 core, 1GiB of RAM costing $0.00840 per hour Azure (x86): B1S, 1 core, 1GiB of RAM costing $0.00690 per hour AWS (x86): t3.micro, 2 core, 1 GiB of RAM costing $0.00840 per hour
Its an easy victory for ARM on AWS here – its performant, cheap and predictable. The B1S instance on Azure couldn’t handle 15 or 20 clients per second at all but may be worth consideration if its bursting system works for you.
Simulated Async Workload
2 Core Tests
For these tests I used the same configurations as in the computational workload.
Their is less to separate the processors and vendors with a less computationally intensive workload. Interestingly the AWS machines have a less stable response time with more > 10 second response times but, in the case of the ARM chip, it does this while holding a lower average response time while under load.
Its worth noting that the ARM VM is doing this at 40% of the cost of the Azure VM and so I would argue again represents the best bang for buck. The AWS x86 VM is 20% cheaper than the Azure equivelant – if you can live with the extra “chop” that may still be worth it or you can use that saving to purchase a bigger tier unit.
4 Core Tests
For these tests I used the same virtual machines as for the computational workload:
There is little to separate the two VMs until they come under heavy load at which point we see mixed results – I would argue the ARM VM suffers more as it becomes much more spiky with no consistent benefit in average response time.
However in terms of bang for buck – this ARM VM is nearly half the price of the Azure VM. There’s no contest. I could put two of these behind a load balancer for nearly the same cost.
Starter Workloads
For these tests I used the same virtual machines as for the computational workload:
Its a pretty even game here until we hit the 100 client per second range at which point the AWS VMs begin to outperform the Azure VM though at the 200 client per second range at the expense of more long response times.
Conclusions
Given the results, at least with these workloads, its hard not to conclude that AWS currently offers significantly greater bang for buck than Azure for compute. Particularly with their use of ARM processors AWS seem to have taken a big leap ahead in terms of value for money for which, at the moment, Azure doesn’t look to have any response.
Perhaps tailoring Azure VMs to your specific workloads may get you more mileage.
I’ve tried to measure raw compute here in the simplest way I can – I’d stress that if you use more managed services you may see a different story (though ultimately its all running on the same infrastructure so my suspicion is not). And as always, particularly if you’re considering a switch of vendor, I’d recommend running and measuring representative workloads.
Having conducted my ARM and x64 tests on AWS yesterday I was curious to see how Azure would fair – it doesn’t support ARM but ultimately that’s a mechanism for delivering value (performance and price) and not an end in and of itself. And so this evening I set about replicating the tests on Azure.
In the end I’ve massively limited my scope to two instance sizes:
A2 – this has 2 CPUs and 4Gb of RAM (much more RAM than yesterdays) and costs $0.120 per hour
B1S – a burstable VM that has 1 CPUand 1Gb RAM (so most similar to yesterdays t2.micro) and costs $0.0124 per hour
Note – I’ve begun to conduct tests on D series too, preliminary findings is that the D1 is similar to the A2 in performance characteristics.
I was struggling to find Azure VMs with the same pricing as AWS and so had to start with a burstable VM to get something in the same kind of ballpark. Not ideal but they are the chips you are dealt on Azure! I started with the B1S which was still more expensive than the ARM VM. I created the VM, installed software, and ran the tests – the machine comes with 30 credits for bursting. However after running tests several times it was still performing consistently so these were either exhausted quickly, made little difference, or were used consistently.
I moved to the A2_V2 because, frankly, the performance was dreadful on my early tests with the B1S and I also wanted something that wouldn’t burst. I was also trying to match the spec of the AWS machines – 2 cores and 1Gb of RAM. I’ll attempt the same tests with a D series when I can.
Test setup was the same and all tests are run on VMs accessed directly on their public IP using Apache as a reverse proxy to Kestrel and our .NET application.
I’ve left the t2.micro instance out of this analysis
Mandelbrot
With 2 clients per test we see the following response times:
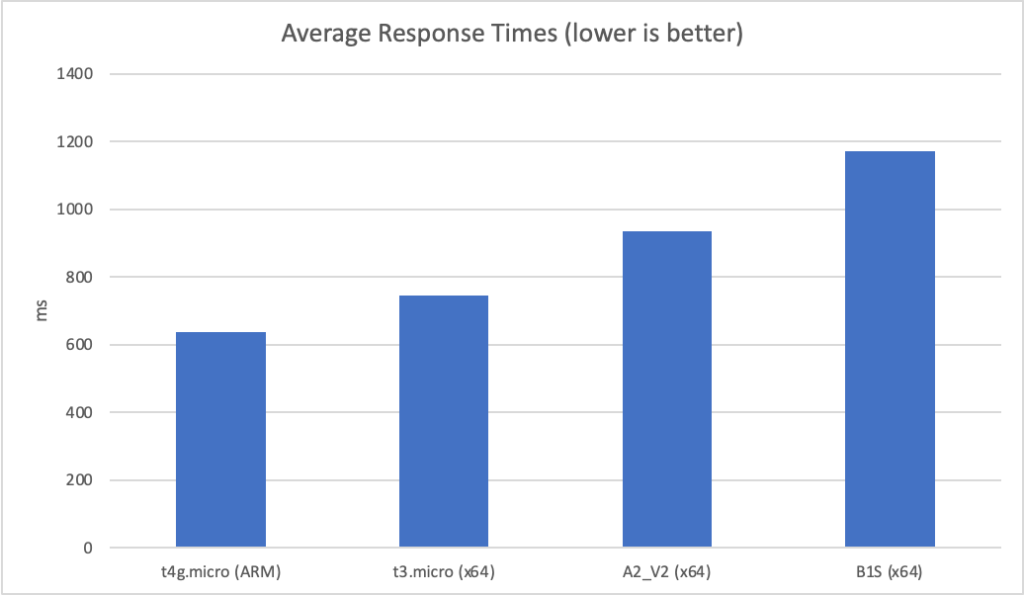
We can see that the two Azure instances are already off to a bad start on this computationally heavy test.
At 10 clients per second we continue to see this reflected:
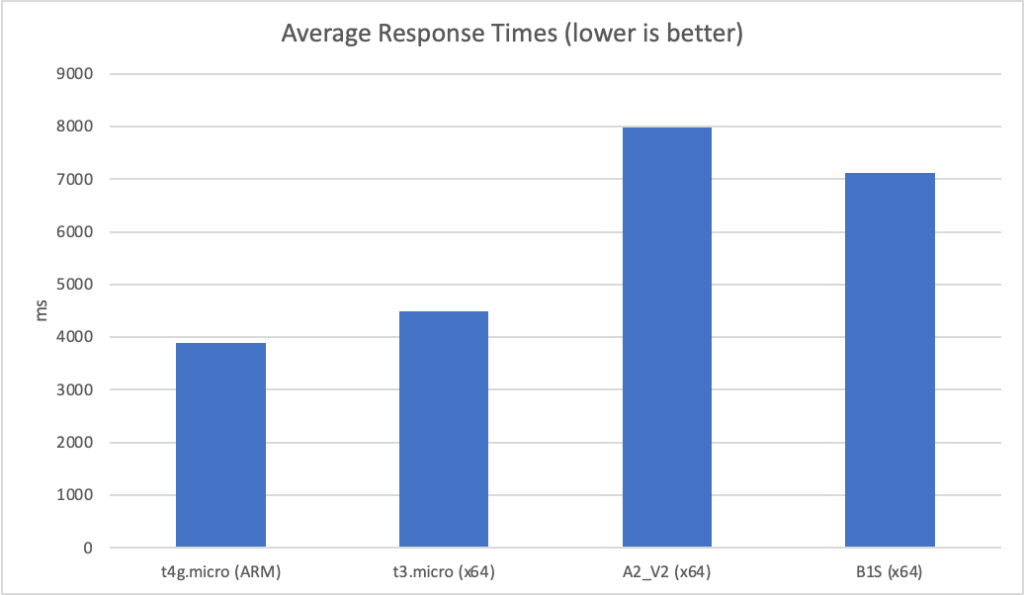
However at this point the two Azure instances begin to experience timeout failures (the threshold being set at 10 seconds in the load tester):
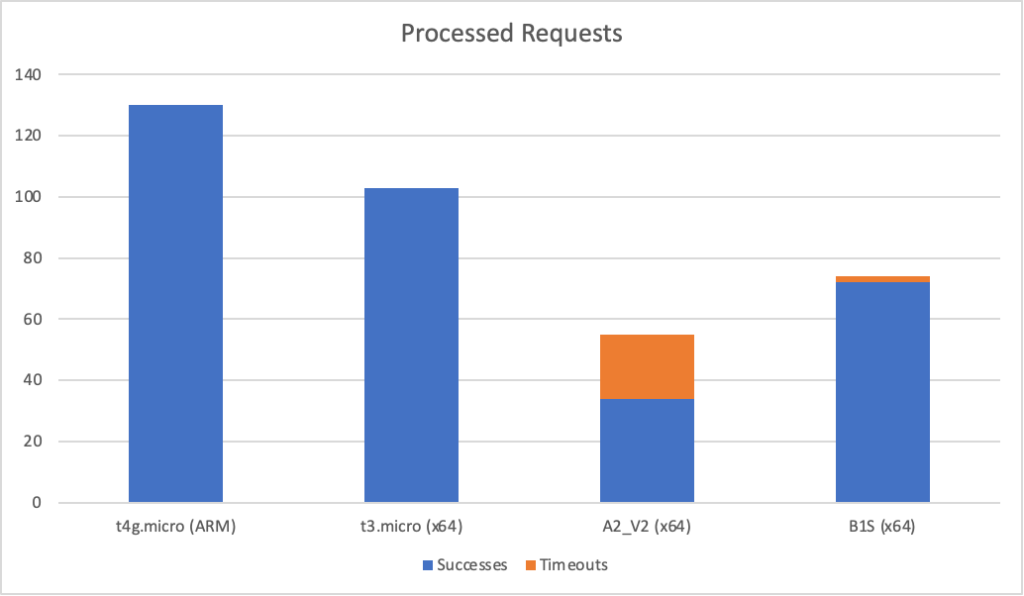
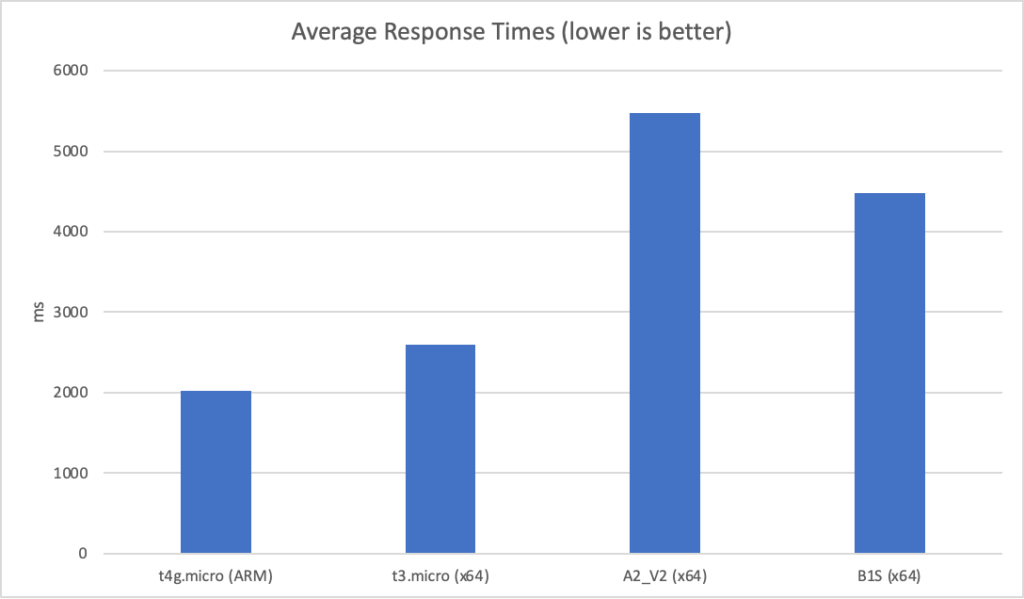
The A2_V2 instance is faring particularly badly particularly given it is 10x the cost of the AWS instances.
Unfortunately their is no meaningful compaison I can make under higher load as both Azure instances collapse when I push to 15 clients per second. For complete sake here are the results on AWS at 20 clients per second (average response and total requests):
Simulated Async Workload
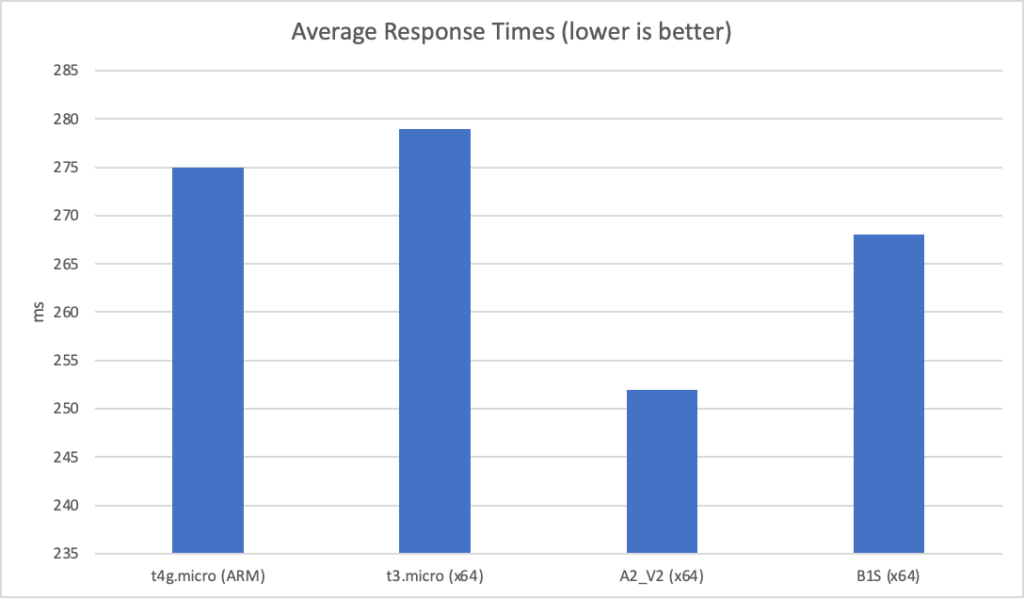
With our simulated async workload Azure fares better at low scale. Here are the results at 20 requests per second:
As we push the scale up things get interesting with different patterns across the two vendors. Here are the average response times at 200 clients per second:
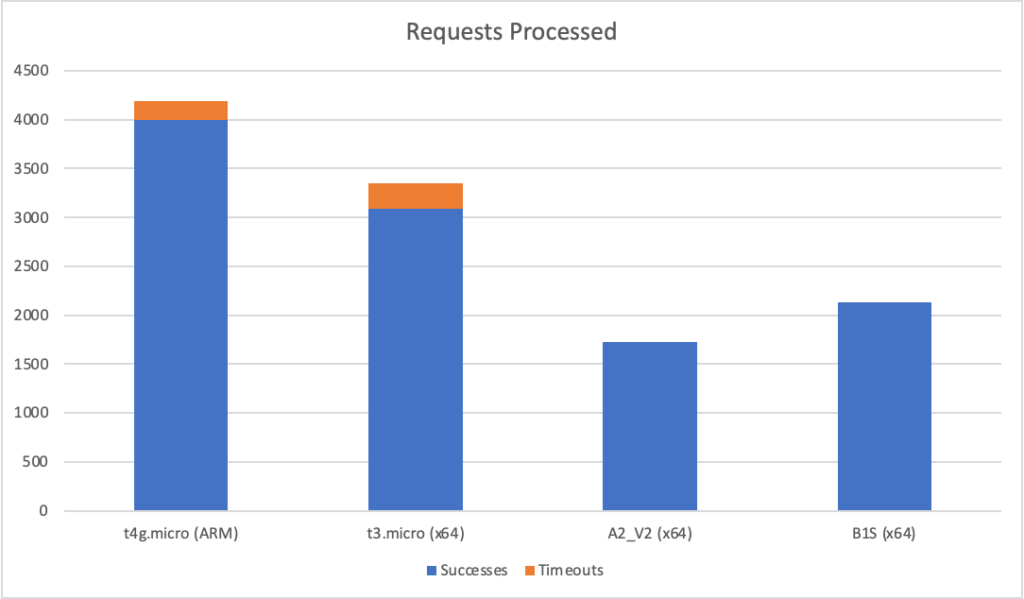
At first glance AWS looks to be running away with things however both the t4g.micro and t3.micro suffer from performance degradation at the extremes – the max response time is 17 seconds for both while for the Azure instances it is around 9 seconds.
You can see this reflected in the success and total counts where the AWS instances see a number of timeout failures (> 10 seconds) while the Azure instances stay more consistent:
However the AWS instances have completed many more requests overall. I’ve not done a percentile breakdown (see comments yesterday) but it seems likely that at the edges AWS is fraying and degrading more severely than Azure leading to this pattern.
Conclusions
The different VMs clearly have different strengths and weaknesses however in the computational test the Azure results are disappointing – the VMs are more expensive yet, at best, offer performance with different characteristics (more consistent when pushed but lower average performance – pick your poison) and at worst offer much lower performance and far less value for money. They seem to struggle with computational load and nosedive rapdily when pushed in that scenario.
With Microsoft and Apple both now beginning to use ARM chips in laptops, what was traditionally the domain of x86/x64 architecture, I found myself curious as to the ramifications of this move – particularly by Apple who are transitioning their entire lineup to ARM over the next 2 years.
While musing on the pain points of this I found myself wandering if Azure supported ARM processors, they don’t, and got pointed to AWS who do. @thebeebs (an AWS developer advocate) mentioned that some customers had seen significant cost reductions by moving some workloads over to ARM and so I, inevitably, found myself curious as to how typical .NET workloads might run in comparison to x64 and set about some tests.
The Tests
I quickly rustled up a simple API containing two invocable workloads:
A computation heavy workload – I’m rendering a Mandelbrot and returning it as an image. This involves floating point maths.
A simulated await workload – often with APIs we hand off to some other system (e.g. a database) and then do a small amount of computation. I’ve simulated this with Task.Delay and a (very small) random factor to simulate the slight variations you will get with any network / remote service request and then around this I compute two tiny Mandelbrots and return a couple of numbers. It would be nice to come back at some point and use a more structured approach for the simulated remote latency.
I’ve written this in F# (its not particularly “functional”) using Giraffe on top of ASP.Net Core just because that’s my go to language these days. Its running under the .NET 5 runtime.
The code for this is here. Its not particularly elegant and I simply converted some old JavaScript code of mine into F# for the Mandelbrot. It does a job.
The Setup
Within AWS I created three EC2 Linux instances:
t4g.micro – ARM based, 2 vCPU, 1Gb memory, $0.0084 per hour
Its worth noting that my ARM instance is costing me 20% less than the t3.micro.
I’ve deliberately chosen very small instances in order to make it easier to stress them without having to sell a kidney to fund the load testing. We should be able to stress these instances quite quickly.
I then SSHed into each box and installed .NET 5 from the appropriate binaries and setup Apache as a reverse proxy. On the ARM machine I also had to install GCC and compile a version of libicui18n for .NET to work.
Next I used git clone to bring down the source and ran dotnet restore followed by dotnet run. At this point I had the same code working on each of my EC2 instances. Easy to verify as the root of the site shows a Mandelbrot:
This was all pretty easy to set up. You can also do it using a Cloud Formation sample that I was pointed at (again by @thebeebs).
I still think its worth remarking how much .NET has changed in the last few years – I’ve not touched Windows here and have the same source running on two different CPU architectures with no real effort on my part. Yes its “get through the door” stakes these days but it was hard to imagine this a few years back.
Benchmarks
My tests were fairly simple – I’ve used loader.io to maintain a steady state of a given number of clients per second and gathered up the response times and total execution counts along with the number of timeouts. I had the timeout threshold set at 10 seconds.
Time allowing I will come back to this and run some percentile analysis – loader doesn’t support this and so I would need to do some additional work.
I’ve run the test several times and averaged the results – though they were all in the same ballpark.
Mandelbrot
Firstly as a baseline lets look at things running with just two clients per second:
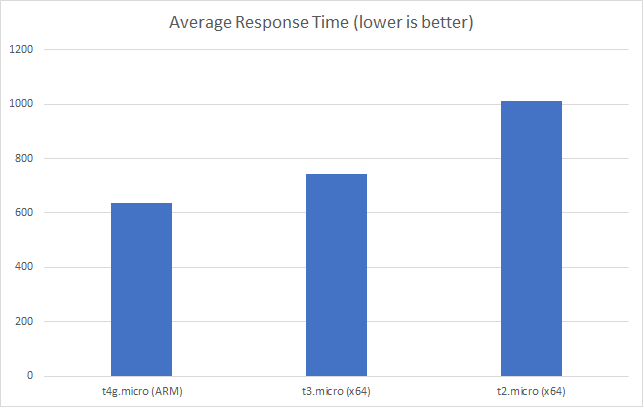
With little going on we can see that the ARM instance already has a slight advantage – its consistently (min, max and average) around 100ms faster than the closest x64 based instance.
Unsurprisingly if we push things a little harder to 5 clients per second this becomes magnified:
We’re getting no errors or timeouts at this point and you can see the total throughput over the 30 second run below:
The ARM instance has completed around 20% more requests than the nearest x64 instance, with a 18% improvement in average response time and at 80% of the cost.
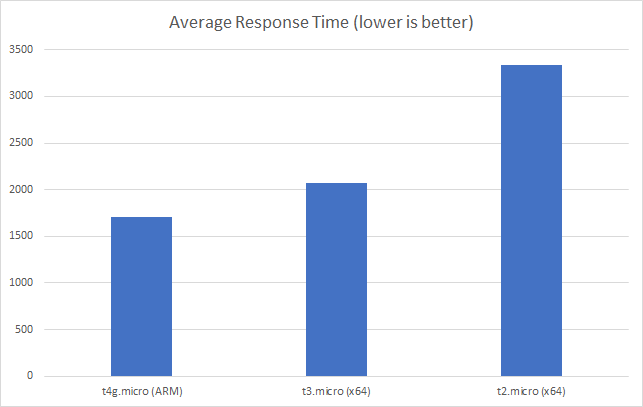
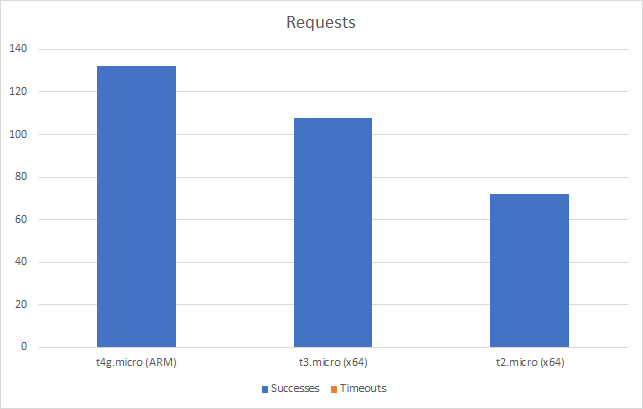
And if we push this out to 20 clients per second (my largest scale test) the ARM instance looks better again:
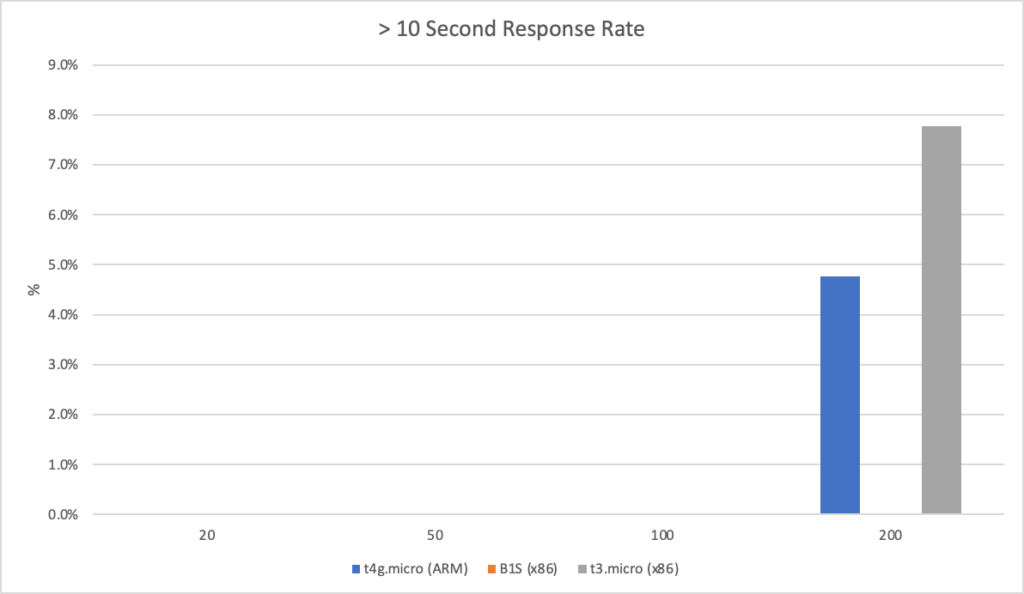
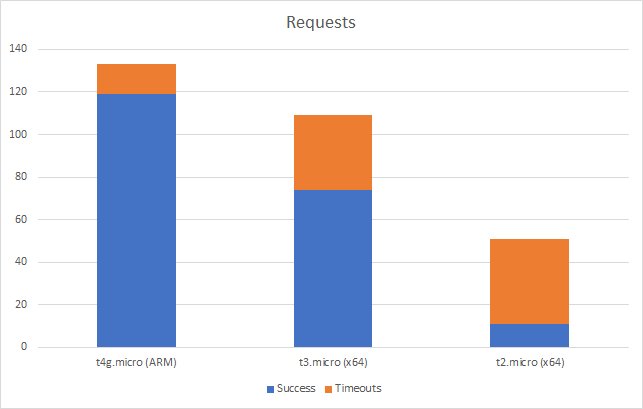
Its worth noting that at this point all three instances are generating timeouts in our load test suite but again the ARM instance wins out here – we get fewer timeouts and get through more overall requests:
You can see from this that our ARM instance is performing much better under this level of load. We can say that:
Its successfully completed 60% more requests than the nearest x64 instance
It has a roughly 12% improvement on average response time
And it is doing this at 80% of the cost of the x64 instance
With our Mandelbrot test its clear that the ARM instance has a consistent advantage both in performance and cost.
Simulated Async Workload
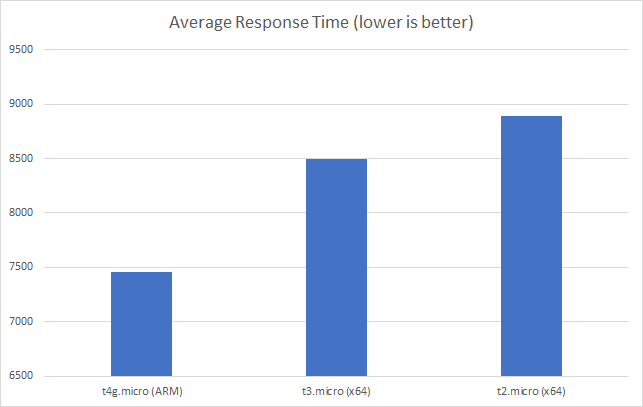
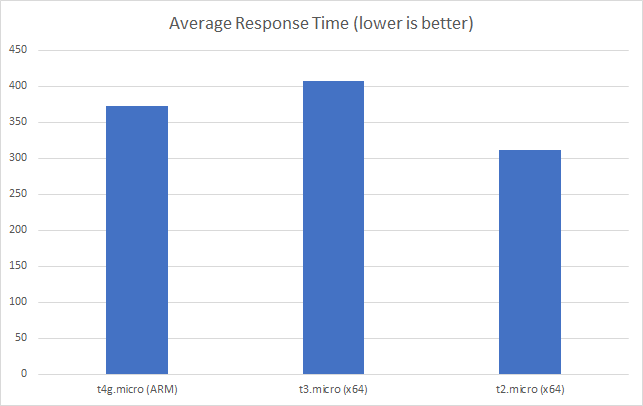
Starting again with a low scale test (in this case 50 clients per second – this test spends significant time awaiting) in this case we can see that our t2 x64 instance had an advantage of around 40ms:
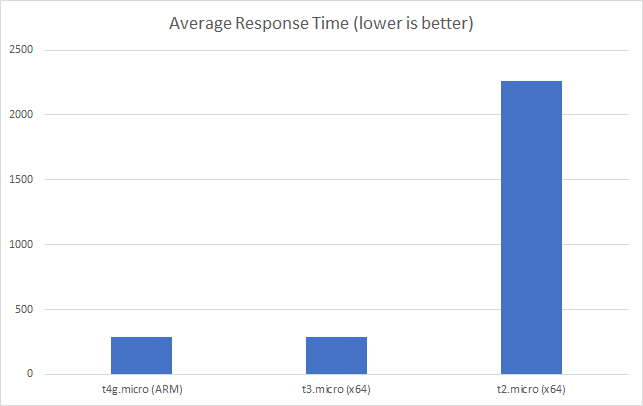
However if we move up to 100 clients per second we can see the t2 instance essentially collapse while out t4g ARM instance and t3 x64 instance are essentially level pegging (286ms and 292ms) respectively:
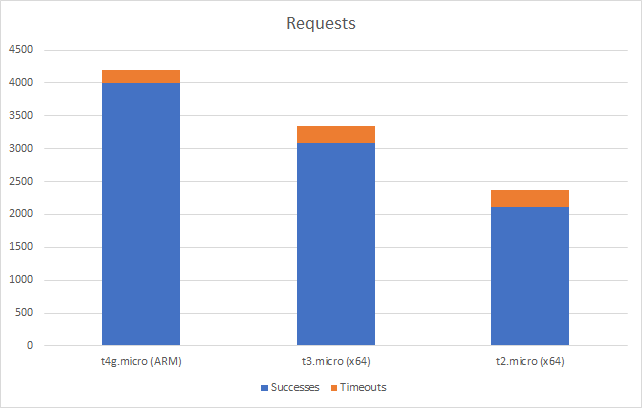
We get no timeouts at this point and our ARM and x64 instance level peg again on total requests:
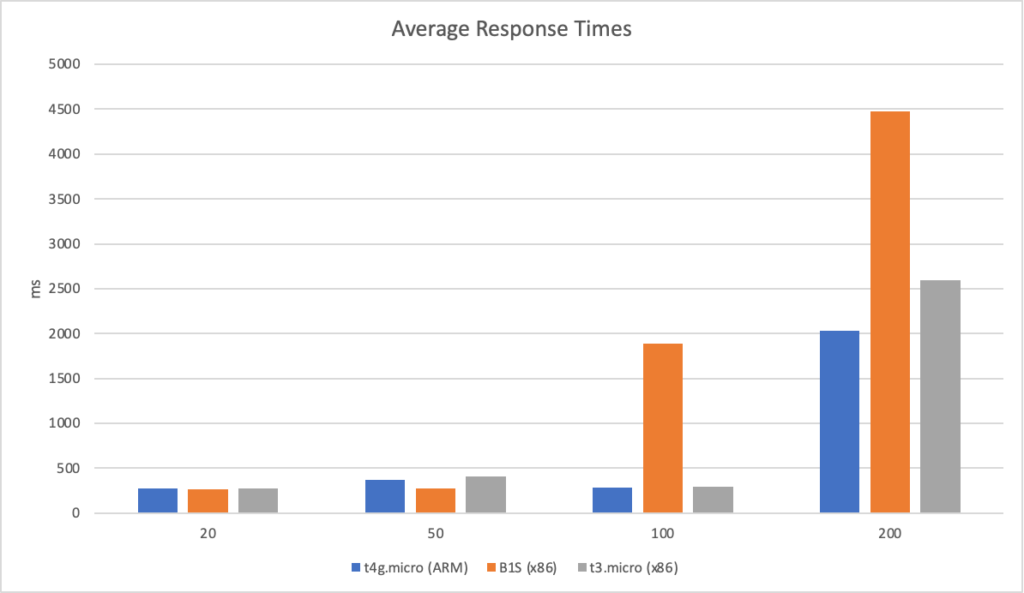
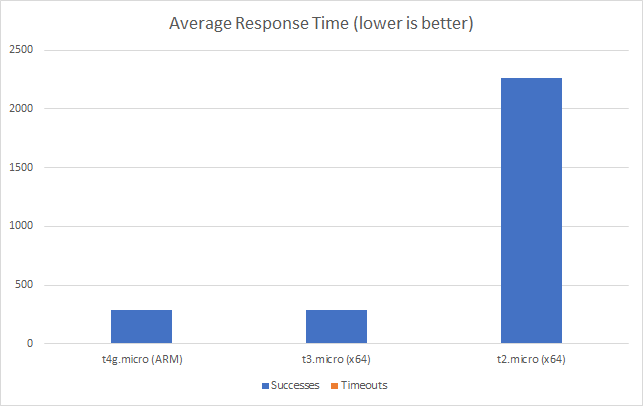
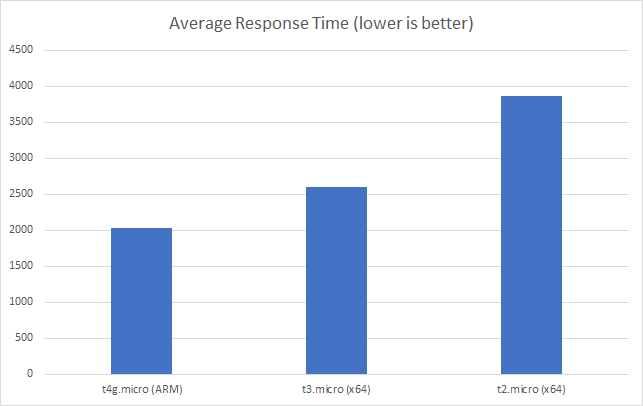
However if we push on to a higher scale test (200 clients per second) we can see the ARM instance begin to pull ahead:
Conclusions
Going into this I really didn’t know what to expect but these fairly simple tests suggest their is an economic advantage to running under ARM in the cloud. At worst you will see comparable performance at a lower price point but for some workloads you may see a significant performance gain – again at a lower price point.
20% performance gain at 80% the price is most certainly not to be sniffed at and for large workloads could quickly offset the cost of moving infrastructure to ARM.
Presumably the price savings are due to the power efficiency of the ARM chips. However what is hard to tell is how much of the pricing is “early adopter” to encourage people to move to CPUs that have long term advantage to cloud vendors (even minor power efficiency gains over cloud scale data centers must total significant numbers on the bottom line) and how much of that will be sustained and passed on to users in the long term.
Doubtless we’ll land somewhere in the middle.
Question I have now is: where the heck is Azure in all this? Between Lambda and ARM on AWS its hard not to feel as if the portability advantages, both processor and OS, of .NET Core / 5 are being realised more effectively by Amazon than they are by Microsoft themselves. Strange times.
Full Results
Response Times (ms)
Test
Instance
Clients per second
Min
Max
Average
Successful Responses
Timeouts
Mandelbrot
t4g.micro (ARM)
2
618
751
638
60
0
Mandelbrot
t4g.micro (ARM)
5
765
2794
1709
132
0
Mandelbrot
t4g.micro (ARM)
10
761
6958
3882
130
0
Mandelbrot
t4g.micro (ARM)
15
759
10203
5704
127
1
Mandelbrot
t4g.micro (ARM)
20
802
10207
7459
119
14
Mandelbrot
t3.micro (x64)
2
701
885
744
60
0
Mandelbrot
t3.micro (x64)
5
878
3313
2069
108
0
Mandelbrot
t3.micro (x64)
10
855
8037
4498
103
0
Mandelbrot
t3.micro (x64)
15
973
10202
6930
84
9
Mandelbrot
t3.micro (x64)
20
1030
10215
8495
74
35
Mandelbrot
t2.micro (x64)
2
675
1140
1010
58
0
Mandelbrot
t2.micro (x64)
5
651
5324
3332
72
0
Mandelbrot
t2.micro (x64)
10
1867
10193
6999
56
8
Mandelbrot
t2.micro (x64)
15
1445
10203
9458
32
44
Mandelbrot
t2.micro (x64)
20
1486
10206
8895
11
40
Async
t4g.micro (ARM)
20
236
371
275
600
0
Async
t4g.micro (ARM)
50
222
4178
373
1498
0
Async
t4g.micro (ARM)
100
231
414
286
2994
0
Async
t4g.micro (ARM)
200
310
17388
2028
3995
200
Async
t3.micro (x64)
20
233
402
279
600
0
Async
t3.micro (x64)
50
235
4912
407
1498
0
Async
t3.micro (x64)
100
235
545
292
2994
0
Async
t3.micro (x64)
200
234
17376
2598
3089
260
Async
t2.micro (x64)
20
242
412
298
600
0
Async
t2.micro (x64)
50
241
545
312
1497
0
Async
t2.micro (x64)
100
244
9829
2260
1989
0
Async
t2.micro (x64)
200
347
17375
3858
2118
252
Contact
If you're looking for help with C#, .NET, Azure, Architecture, or would simply value an independent opinion then please get in touch here or over on Twitter.


Recent Comments