If you're looking for help with C#, .NET, Azure, Architecture, or would simply value an independent opinion then please get in touch here or over on Twitter.
I’m a big fan of the serverless compute model (known as Azure Functions on the Azure platform), but in some ways its greatest strength is also its weakness: the serverless model essentially asks you to run small units of code inside a fully managed environment on a pay for what you need basis that in theory will scale infinitely in response to demand. With the increased granularity this is the next evolution in cloud elasticity with no more need to buy and reserve CPUs which sit partially idle until the next scaling point is reached. However as a result you lose control over the levers you might be used to pulling in a more traditional cloud compute environment – it’s very much a black box. Using typical queue processing patterns as an example this includes the number of “threads” or actors looking at a queue and the length of the back off timings.
Most of the systems I’ve transitioned onto Azure Functions to date have been more focused on cost than scale and have had no particular latency requirements and so I’ve just been happy to reduce my costs without a particularly close examination. However I’m starting to look at moving spikier higher volume queue systems onto Azure Functions and so I’ve been looking to understand the opaque aspects more fully through running a series of experiments.
Before continuing it’s worth noting that Microsoft continue to evolve the runtime host for Azure Functions and so the results are only really valid at the time they are run – run them again in 6 months and you’re likely to see, hopefully subtle and improved, changes in behaviour.
Most of my higher volume requirements are light in terms of compute power but heavy on volume and so I’ve created a simple function that pulls a message from a Service Bus queue and writes it, along with a timestamp, onto an event hub:
[FunctionName("DequeAndForwardOn")]
[return: EventHub("results", Connection = "EhConnectionString")]
public static string Run([ServiceBusTrigger("testqueue", Connection = "SbConnectionString")]string myQueueItem, TraceWriter log)
{
log.Info($"C# ServiceBus queue trigger function processed message: {myQueueItem}");
EventHubOutput message = JsonConvert.DeserializeObject<EventHubOutput>(myQueueItem);
message.ProcessedAtUtc = DateTime.UtcNow;
string json = JsonConvert.SerializeObject(message);
return json;
}
Once the items are on the Event Hub I’m using a Streaming Analytics job to count the number of dequeues per second with a tumbling window and output them to table storage:
SELECT
System.TimeStamp AS TbPartitionKey,
'' as TbRowKey,
SUBSTRING(CAST(System.TimeStamp as nvarchar(max)), 12, 8) as Time,
COUNT(1) AS totalProcessed
INTO
resultsbysecond
FROM
[results]
TIMESTAMP BY EventEnqueuedUtcTime
GROUP BY TUMBLINGWINDOW(second,1)
For this initial experiment I’m simply going to pre-load the Service Bus queue with 1,000,000 messages and analyse the dequeue rate. Taking all the above gives us a workflow that looks like this:

Executing all this gave some interesting results as can be seen from the graph below:
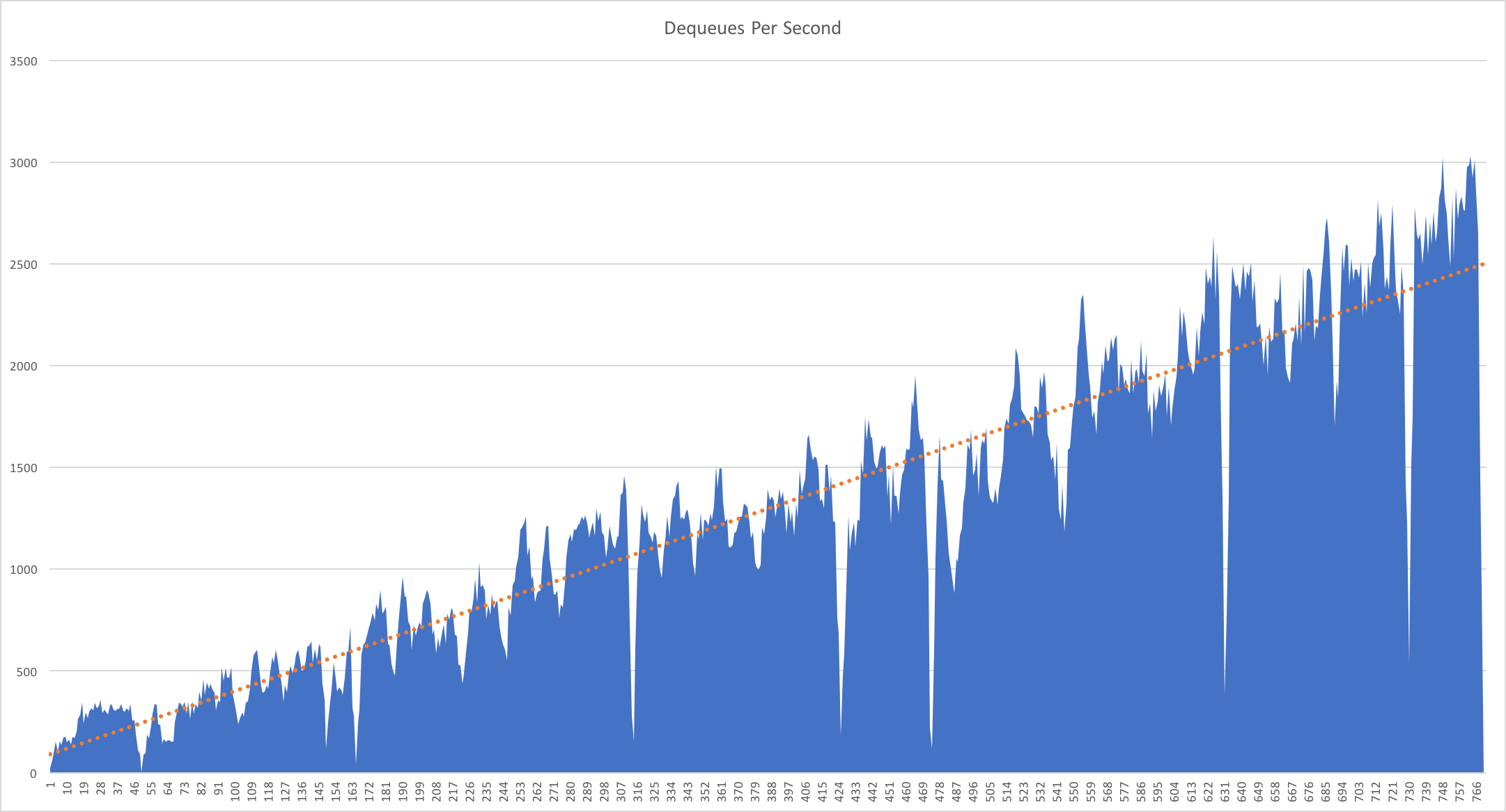
From a cold start it took just under 13 minutes to dequeue all 1,000,000 messages with a fairly linear, if spiky, approach to scaling up the dequeue rate from a low at the beginning of 23 dequeues per second to a peak of over 3000 increasing at a very rough rate of 3.2 messages per second. It seems entirely likely that this will go on until we start to hit IO limits around the Service Bus. We’d need to do more experiments to be certain but it looks like the runtime is allocating more queue consumers while all existing consumers continue to find their are items on the queue to process.
In the next part we’re going to run a few more experiments to help us understand the scaling rate better and how it is impacted by quiet periods.
