This part focuses on addressing cross cutting concerns in a DRY manner by implementing a custom command dispatcher.
I’ve also switched over to Rider as my main IDE now and in this video I’m making use of its Presentation Mode. I think it works really well but let me know.
I’ve just pushed out a new version of Function Monkey with one fairly minor but potentially important change – the ability to create functions without routes.
You can now use the .HttpRoute() method without specifying an actual route. If you then also specify no path on the .HttpFunction<TCommand>() method that will result in an Azure Function with no route specified – it will then be named in the usual way based on the function name, which in the case of Function Monkey is the command name.
I’m not entirely comfortable with the approach I’ve taken to this at an API level but didn’t want to break anything – next time I plan a set of breaking changes I’ll probably look to clean this up a bit.
The reason for this is to support Logic Apps. Logic Apps only support routes with an accompanying Swagger / OpenAPI doc and you don’t necessarily want the latter for your functions.
While I was using proxies HTTP functions had no route and so they could be called from Logic Apps using the underlying function (while the outside world would use the shaped endpoint exposed through the proxy).
Having moved to a proxy-less world I’d managed to break a production Logic App of my own because the Logic App couldn’t find the function (404 error). Redeployment then generated a more meaningful error – that routed functions aren’t supported. Jeff Hollan gives some background on why here.
I had planned a bunch of improvements for 2.1.0 (which I’ve started) which will now move to 2.2.0.
Part 3 of my series on writing Azure Functions with Function Monkey focuses on writing tests using the newly released testing package – while this is by no means required it does make writing high value acceptance tests that use your applications full runtime easy and quick.
Lessons Learned
It really is amazing how quickly time passes when you’re talking and coding – I really hadn’t realised I’d recorded over an hours footage until I came to edit the video. I thought about splitting it in two but the contents really belonged together so I’ve left it as is.
Part 2 in my series of writing and testing Azure Functions with Function Monkey looks at adding validation and returning appropriate status codes from HTTP requests. Part 3 will look at acceptance testing this.
(Don’t worry – we’re going to look at some additional trigger types soon!)
Lessons Learned
I made a bunch of changes following some awesome feedback on Twitter and hopefully that results in an improved viewing experience for people.
I still haven’t got the font size right – I used a mix of Windows 10 scaling and zoomed text in Visual Studio but its not quite there. I also need to start thinking of actually using zoom when I’m pointing at something.
Hopefully part 3 I can address more of these things.
I’ve long thought about creating some video content but forever put it off – like many people I dislike seeing and hearing myself on video (as I quipped half in jest, half in horror, on Twitter “I have a face made for radio and a voice for silent movies”). I finally convinced myself to just get on with it and so my first effort is presented below along with some lessons learned.
Hopefully video n+1 will be an improvement on video n in this series – if I can do that I’ll be happy!
The Process and Lessons Learned
This was very much a voyage of discovery – I’ve never attempted recording myself code before and I’ve never edited video before.
To capture the screen and initial audio I used the free OBS Studio which after a little bit of fiddling to persuade it to capture at 4K and user error resulting in the loss of 20 minutes of video worked really well. It was unobtrusive and did what it says on the tin.
I use a good quality 4K display with my desktop machine and so on my first experiment the text was far too smaller, I used the scaling feature in Windows 10 to bump things up to 200% and that seemed about right (but you tell me!).
I sketched out a rough application to build but left things fairly loose as I hoped the video would feel natural and I know from presentations (which I don’t mind at all – in contrast to seeing and hearing myself!) that if I plan too much I get a bit robotic. I also figured I’d be likely to make some mistakes and with a bit of luck they’d be mistakes that would be informative to others.
This mostly worked but I could have done with a little more practice up front as I took myself down a stupid route at one point as my brain struggled with coding and narrating simulatanously! Fortunately I was able to fix this later while editing but I made things harder for myself than it needed to be and there’s a slight alteration in audo tone as I cut the new voice work in.
Having captured the video I transferred it to my MacBook to process in Final Cut Pro X and at this point realised I’d captured the video in flv – a format Final Cut doesn’t import. This necessitated downloading Handbrake to convert the video into something Final Cut could import. Not a big deal but I could have saved myself some time – even a pretty fast Mac takes a while to re-encode 55 minutes of 4K video!
I’d never used Final Cut before but it turned out to be fairly easy to use and I was able to cut out my slurps of coffee and the time wasting uninformative mistake I made. I did have to recut some audio as I realised I’d mangled some names – this was fairly simple but the audio doesn’t sound exactly the same as it did when recorded earlier despite using the same microphone in the same room. Again not the end of the world (I’m not challenging for an Oscar here).
Slightly more irritating – I have a mechanical cherry switch keyboard which I find super pleasant to type on, but carries the downside of making quite a clatter which is really rather loud in the video. Hmmm. I do have an Apple bluetooth keyboard next to me, I may try connecting that to the PC for the next installment but it might impede my typing too much.
Overall that was a less fraught experience than I’d imagined – I did slowly get used to hearing myself while editing the video, though listening to it fresh again a day later some of that discomfort has returned! I’m sure I’ll get used to it in time.
I’ve been meaning to write about a real cloud based project for some time but the criteria a good candidate project needs to fit are challenging:
Significant enough to illustrate numerous design and implementation decisions
Not so large that the time investment for a reader to get into it is prohibitive
I need to own, or have free access to, the intellectual property
It needs to be something I want, or am contracted, to build for reasons beyond writing about it
To expand upon that last point a little – I don’t have the time to build something just for a series of blog posts and if I did I suspect it would be too artificial and essentially would end up a strawman.
The real world and real development is constrained messy, you come across things that you can’t economically solve in an ivory towered fashion. You can’t always predict everything in advance, you get things wrong and don’t always have the time available to start again and so have to do the best that you can with what you have.
In the case of this project I hadn’t really thought about it as a candidate for writing about until I neared the end of building the MVP and so it comes, rather handily, with warts and all. For sure I’ve refactored things but no more than you’d expect to on any time and budget constrained project.
My intention is, over the course of a series of posts, to explore this application in an end to end fashion: the requirements, the architecture, the code, testing, deployment – pretty much its end to end lifecycle. Hopefully this will contain useful nuggets of information that can be applied on other projects and help those new to Azure get up and running.
About the project
So what does the project do?
If you’re a keen cyclist you’ll know that you need to check various components on your bike at regular intervals. You’ll also know that some of the components last just long enough that you’ll forget about them – my personal nemesis is chain wear, more than once I’ve taken that to the point where it is likely to start damaging the rear cassette having completely forgotten about it.
I’m fortunate enough to have a rather nice bike and so there is nothing cheap about replacing anything so really not a mistake you want to be making. Many bikes also now contain components that need charging – Di2 and eTap are increasingly common and though I’ve yet to get caught out on a ride I’ve definitely run it closer than I realised.
After the last time I made this mistake I decided to do something about it and thus was born Bike Reminders: a website that links up with Strava to send you reminders as you accrue mileage on each of your bikes. While not a substitute for regularly checking your bike I’m hopeful it will at least give me a prod over chain wear! I contemplated going direct to Garmin but they seem to want circa $5000 for API access and thats a lot of component damage before I break even – ouch.
In terms of an MVP that distilled out into a handful of high level requirements:
Authenticate with Strava
Access a users bikes in Strava
Allow a mileage based maintenance schedule to be set up against a bike
Allow email reminders to be dismissed / reset
Allow email reminders to be snoozed
Update the progress towards each reminder based on rider activity in Strava
There were also some requirements I wanted to keep in mind for the future:
Time based reminders
“First ride of the week” type reminders
Allow reminders to be sent via push notifications
Predictive information – based on a riders history when is a reminder likely to be triggered, this is useful if you’re going away on a training camp for example and want to get maintenance done before you go
Setting off on the project I set a number of overarching goals / none functional requirements for it:
Keep it small enough that it could be built alongside a two (expanded to three!) week cycling training block in Mallorca
To have a very low cost to run both in terms of minimum footprint (cost to run 1 user) and per user cost as the system scales up
To require little to no maintenance and a fully automated delivery mechanism
To support multiple client types (initially web but to be followed up with a Flutter app)
Keep personal data out of it as far as possible
As far as possible spin out any work that isn’t specific to the problem domain as open source (I’m fairly likely to reuse it myself if nothing else)
And although I try not to jump ahead of myself that mapped nicely onto using Azure as a cloud provider with Azure Functions for compute and Azure DevOps and Application Insights for the operational side of things.
Architecture
The next step was to figure out what I’d need to build – initially I worked this through on a “mental beermat” while out cycling but I like to use the C4 Model to describe software systems. It gives a basic structure and just enough tools to think about and describe systems at different levels of architecture without disappearing up its own backside in complexity and becoming an end in and of itself.
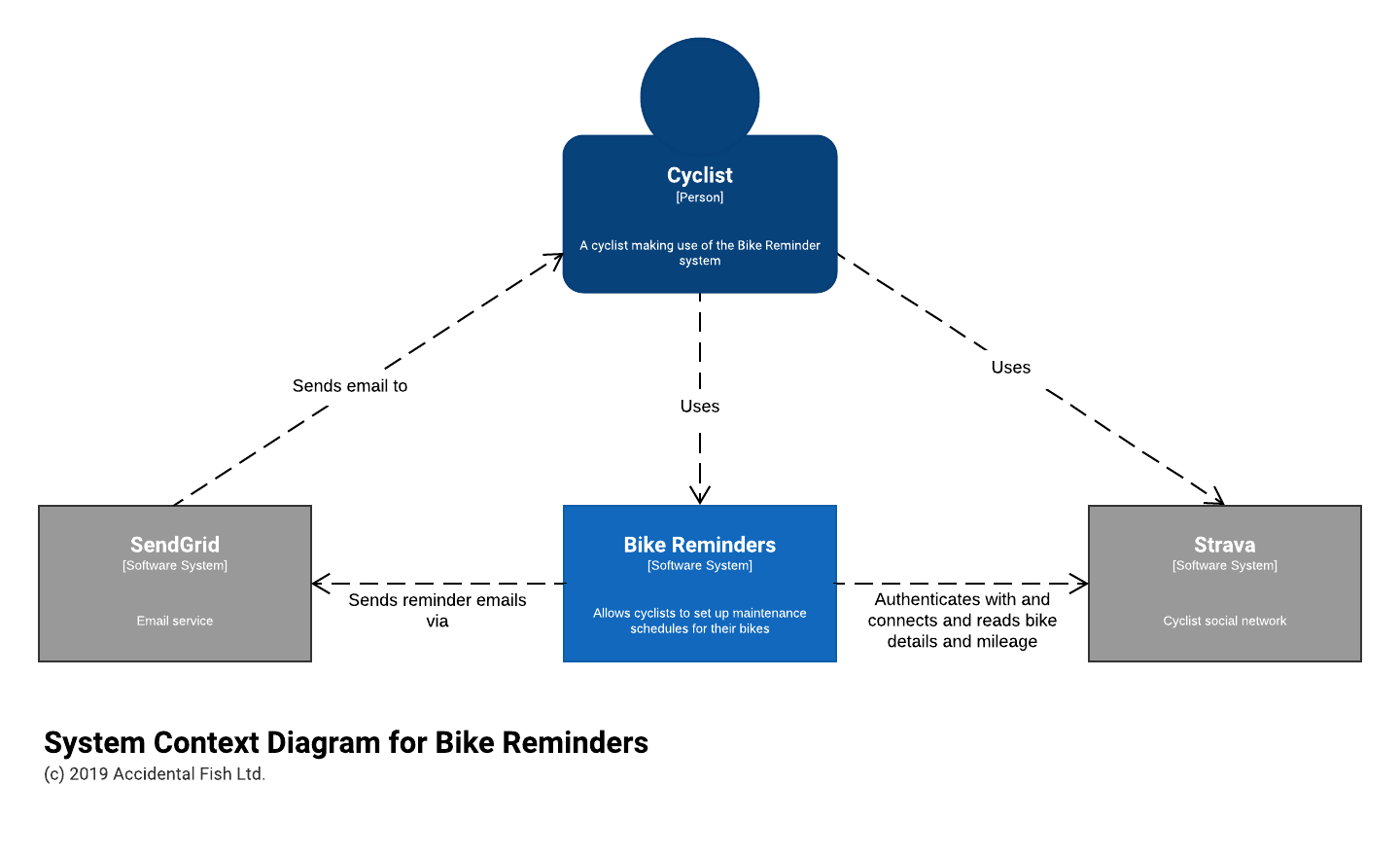
System Context
For this fairly simple and greenfield system establishing the big picture was fairly straight forward. It’s initially going to comprise of a website accessed by cyclists with their Strava logins, connecting to Strava for tracking mileage, and sending emails for which I chose SendGrid due to existing familiarity with it.
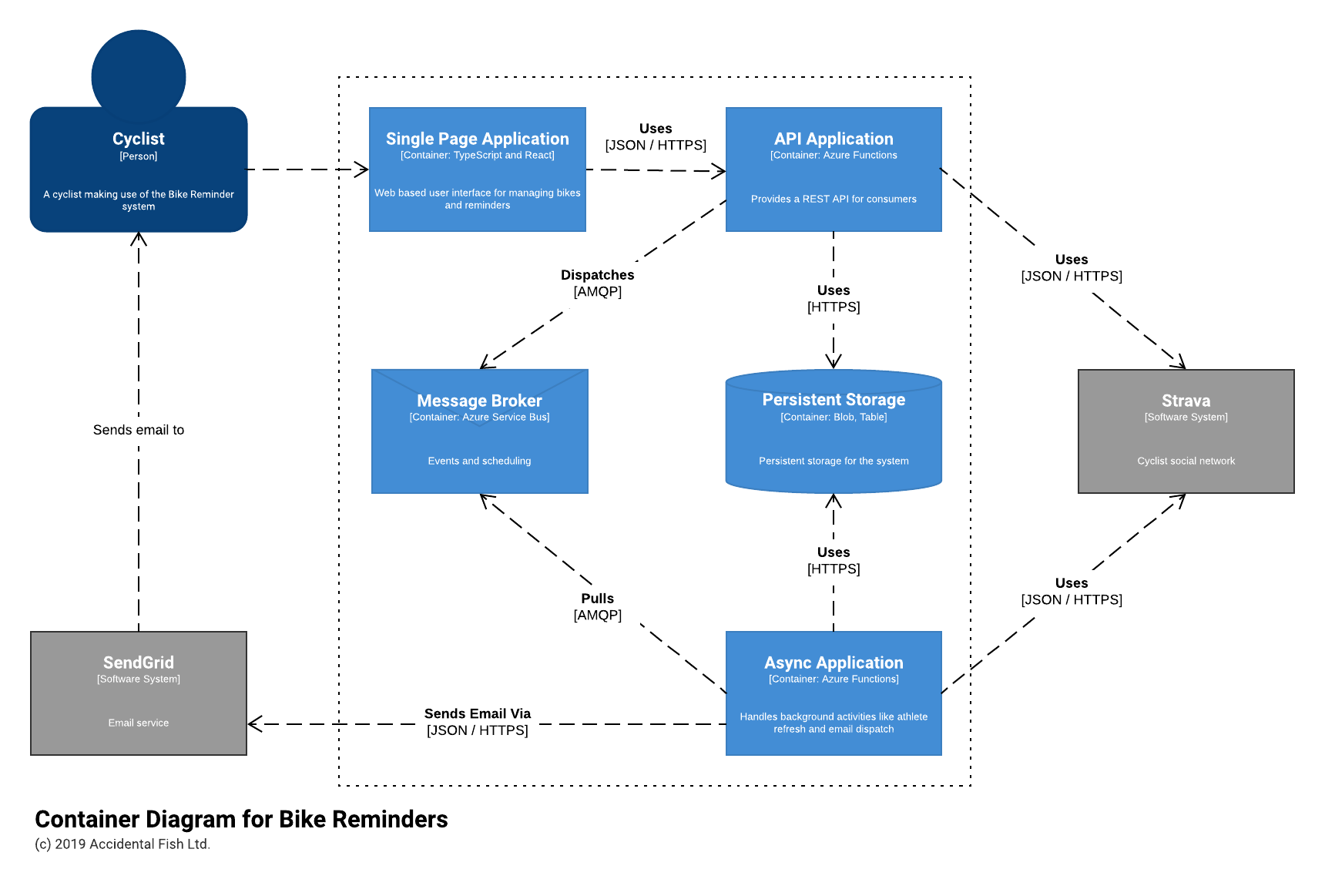
Containers
Breaking this down into more detail forced me to start making some additional decisions. If I was going to build an interactive website / app I’d need some kind of API for which I decided to use Azure Functions. I’ve done a lot of work with them, have a pretty good library for building REST APIs with them (Function Monkey) and they come with a generous free usage allowance which would help me meet my low cost to operate criterion. The event based programming model would also lend itself to handling things like processing queues which is how I envisaged sending emails (hence a message broker – the Azure Service Bus).
For storage I wanted something simple – although at an early stage it seemed to me that I’d be able to store all the key details about cyclists, their bikes and reminders in a JSON document keyed off the cyclists ID. And if something more complex emerged I reasoned it would be easy to convert this kind of format into another. Again cost was a factor and as I couldn’t see, based on my simple requirements, any need for complex queries I decided to at least start with plain old Azure Storage Blob Containers and a filename based on the ID. This would have the advantage of being really simple and really cheap!
The user interface was a simple decision: I’ve done a lot of work with React and I saw no reason it wouldn’t work for this project. Over the last few months I’ve been experimenting with TypeScript and I’ve found it of help with the maintainability of JavaScript projects and so decided to use that from the start on this project.
Finally I needed to figure out how I’d most likely interact with the Strava API to track changes in mileage. They do have a push API that is available by email request but I wanted to start quickly (and this was Christmas and I had no idea how soon I’d hear back from them) and I’d probably have to do some buffering around the ingestion – when you upload a route its not necessarily associated with the right bike (for example my Zwift rides always end up on my main road bike, not my turbo trainer mounted bike) to prevent confusing short term adjustments.
So to begin with I decided to poll Strava once a day for updates which would require some form of scheduling. While I wasn’t expecting huge amounts of overnight for the website Strava do rate limit APIs and so I couldn’t use a timer function with Azure as that would run the risk of overloading the API quite easily. Instead I figured I could use enqueue visibility on the Service Bus and spread out athletes so that the API would never be overloaded. I’ve faced a similar issue before and so I figured this might also make for a useful piece of open source (it did).
All this is summarised in the diagram below:
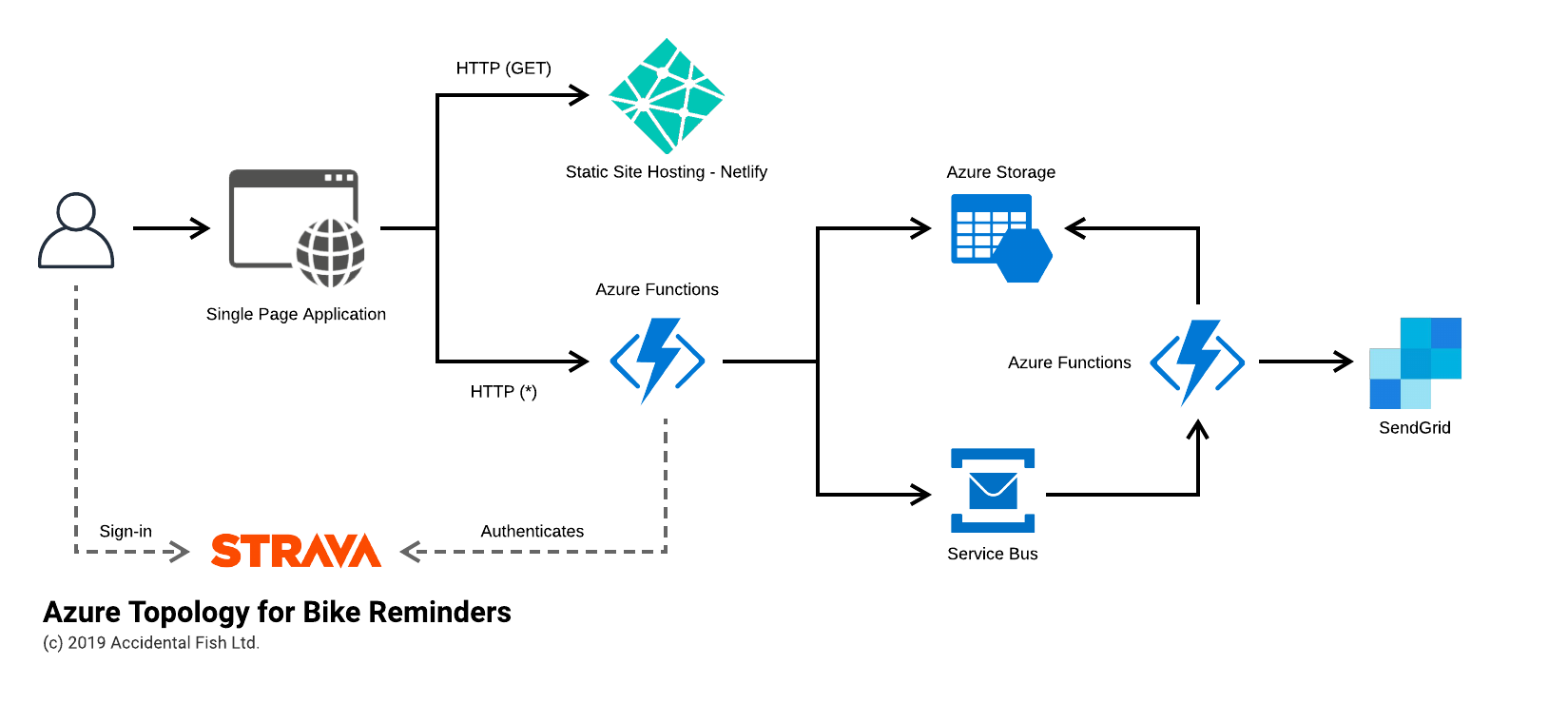
Azure Topology
Mapped (largely) onto Azure I expected the system to look something like the below:
The notable exception is the introduction of Netlify for my static site hosting. While you can host static sites on Azure it is inelegant at best (and the Azure Storage SPA support is useless as you can’t use SSL and a custom domain) and so a few months back I went searching for an alternative and came across Netlify. It makes building, deploying and hosting sites ridiculously easy and so I’ve been gradually switching my work over to here.
I also, currently, don’t have API Management in front of the Azure Functions that present the REST API – the provisioned approach is simply too expensive for this system at the moment and the consumption model, at least at the time of writing, has a horrific cold start time. I do plan to revisit this.
Next Steps
In the next part we’ll break out the code and begin by taking a look at how I structured the Azure Function app.
When I originally posted this piece the library I was using and developing was in an early stage of development. The good news if you’re looking to build REST APIs with Azure Functions its now pretty mature, well documented, and carries the name Function Monkey.
A good jumping off point is this video series here:
Serverless technologies bring a lot of benefits to developers and organisations running compute activities in the cloud – in fact I’d argue if you’re considering compute for your next solution or looking to evolve an existing platform and you are not considering serverless as a core component then you’re building for the past.
Serverless might not form your whole solution but for the right problem the technology and patterns can be transformational shifting the focus ever further away from managing infrastructure and a platform towards focusing on your application logic.
Azure Functions are Microsoft’s offering in this space and they can be very cost-effective as not only do they remove management burden, scale with consumption, and simplify handling events but they come with a generous monthly free allowance.
That being the case building a REST API on top of this model is a compelling proposition.
However… its a bit awkward. Azure Functions are more abstract than something like ASP.Net Core having to deal with all manner of events in addition to HTTP. For example the out the box example for a function that responds to a HTTP request looks like this:
public static class Function1
{
[FunctionName("Function1")]
public static IActionResult Run([HttpTrigger(AuthorizationLevel.Function, "get", "post", Route = null)]HttpRequest req, TraceWriter log)
{
log.Info("C# HTTP trigger function processed a request.");
string name = req.Query["name"];
string requestBody = new StreamReader(req.Body).ReadToEnd();
dynamic data = JsonConvert.DeserializeObject(requestBody);
name = name ?? data?.name;
return name != null
? (ActionResult)new OkObjectResult($"Hello, {name}")
: new BadRequestObjectResult("Please pass a name on the query string or in the request body");
}
}
It’s missing all the niceties that come with a more dedicated HTTP framework, there’s no provision for cross cutting concerns, and if you want a nice public route to your Function you also need to build out proxies in a proxies.json file.
I think the boilerplate and cruft that goes with a typical ASP.NET Core project is bad enough and so I wouldn’t want to build out 20 or 30 of those to support a REST API. Its not that there’s anything wrong with what these teams have done (ASP.NET Core and Azure Functions) but they have to ship something that allows for as many user scenarios as possible – whereas simplifying something is generally about making decisions and assumptions on behalf of users and removing things. That I’ve been able to build both my REST framework and now this on top of the respective platforms is testament to a job well done!
In any case to help with this I’ve built out a framework that takes advantage of Roslyn and my commanding mediator framework to enable REST APIs to be created using Azure Functions in a more elegant manner. I had some very specific technical objectives:
A clean separation between the trigger (Function) and the code that executes application logic
Promote testable code
No interference with the Function runtime
An initial focus on HTTP triggers but extensible to support other triggers
Support for securing Functions using token based security methods such as Open ID Connect
Simple routing
No complicated JSON configuration files
Open API / Swagger generation – under development
Validation – under development
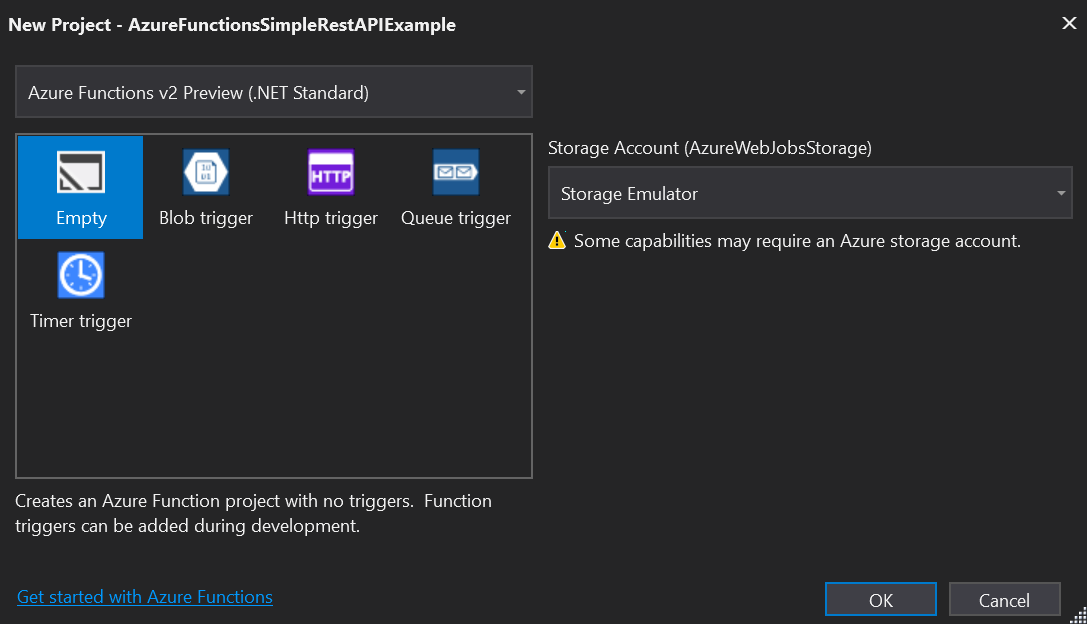
Probably the easiest way to illustrate how this works is by way of an example – so fire up Visual Studio 2017 and follow the steps below.
Firstly create a new Azure Function project in Visual Studio. When you’re presented with the Azure Functions new project dialog make sure you use the Azure Functions v2 Preview and create an Empty project:
After your project is created you should see an empty Azure Functions project. The next step is to add the required NuGet packages – using the Package Manager Console run the following commands:
The first package adds the references we need for the commanding framework and Function specific components while the second adds an MSBuild build target that will be run as part of the build process to generate an assembly containing our Functions and the corresponding JSON for them.
Next create a folder in the project called Model and into that add a class named BlogPost:
class BlogPost
{
public Guid PostId { get; set; }
public string Title { get; set; }
public string Body { get; set; }
}
Next create a folder in the solution called Queries and into that add a class called GetBlogPostQuery:
public class GetBlogPostQuery : ICommand<BlogPost>
{
public Guid PostId { get; set; }
}
This declares a command which when invoked with a blog post ID will return a blog post.
Now we need to write some code that will actually handle the invoked command – we’ll just write something that returns a blog post with some static content but with a post ID that mirrors that supplied. Create a folder called Handlers and into that add a class called GetBlogPostQueryHandler:
class GetBlogPostQueryHandler : ICommandHandler<GetBlogPostQuery, BlogPost>
{
public Task<BlogPost> ExecuteAsync(GetBlogPostQuery command, BlogPost previousResult)
{
return Task.FromResult(new BlogPost
{
Body = "Our blog posts main text",
PostId = command.PostId,
Title = "Post Title"
});
}
}
At this point we’ve written our application logic and you should have a solution structure that looks like this:
With that in place its time to surface this as a REST end point on an Azure Function. To do this we need to add a class into the project that implements the IFunctionAppConfiguration interface. This class is used in two ways: firstly the FunctionMonkey.Compiler package will look for this in order to compile the assembly containing our function triggers and the associated JSON, secondly it will be invoked at runtime to provide an operating environment that supplies implementations for our cross cutting concerns.
Create a class called ServerlessBlogConfiguration and add it to the root of the project:
public class ServerlessBlogConfiguration : IFunctionAppConfiguration
{
public void Build(IFunctionHostBuilder builder)
{
builder
.Setup((serviceCollection, commandRegistry) =>
{
commandRegistry.Discover<ServerlessBlogConfiguration>();
})
.Functions(functions => functions
.HttpRoute("/api/v1/post", route => route
.HttpFunction<GetBlogPostQuery>(HttpMethod.Get)
)
);
}
}
The interface requires us to implement the Build method and this is supplied a IFunctionHostBuilder and its this we use to define both our Azure Functions and a runtime environment. In this simple case its very simple.
Firstly in the Setup method we use the supplied commandRegistry (an ICommandRegistry interface – for more details on my commanding framework please see the documentation here) to register our command handlers (our GetBlogPostQueryHandler class) via a discovery approach (supplying ServerlessBlogConfiguration as a reference type for the assembly to search). The serviceCollection parameter is an IServiceCollection interface from Microsofts IoC extensions package that we can use to register any further dependencies.
Secondly we define our Azure Functions based on commands. As we’re building a REST API we can also group HTTP functions by route (this is optional – you can just define a set of functions directly without routing) essentially associating a command type with a verb. (Quick note on routes: proxies don’t work in the local debug host for Azure Functions but a proxies.json file is generated that will work when the functions are published to Azure).
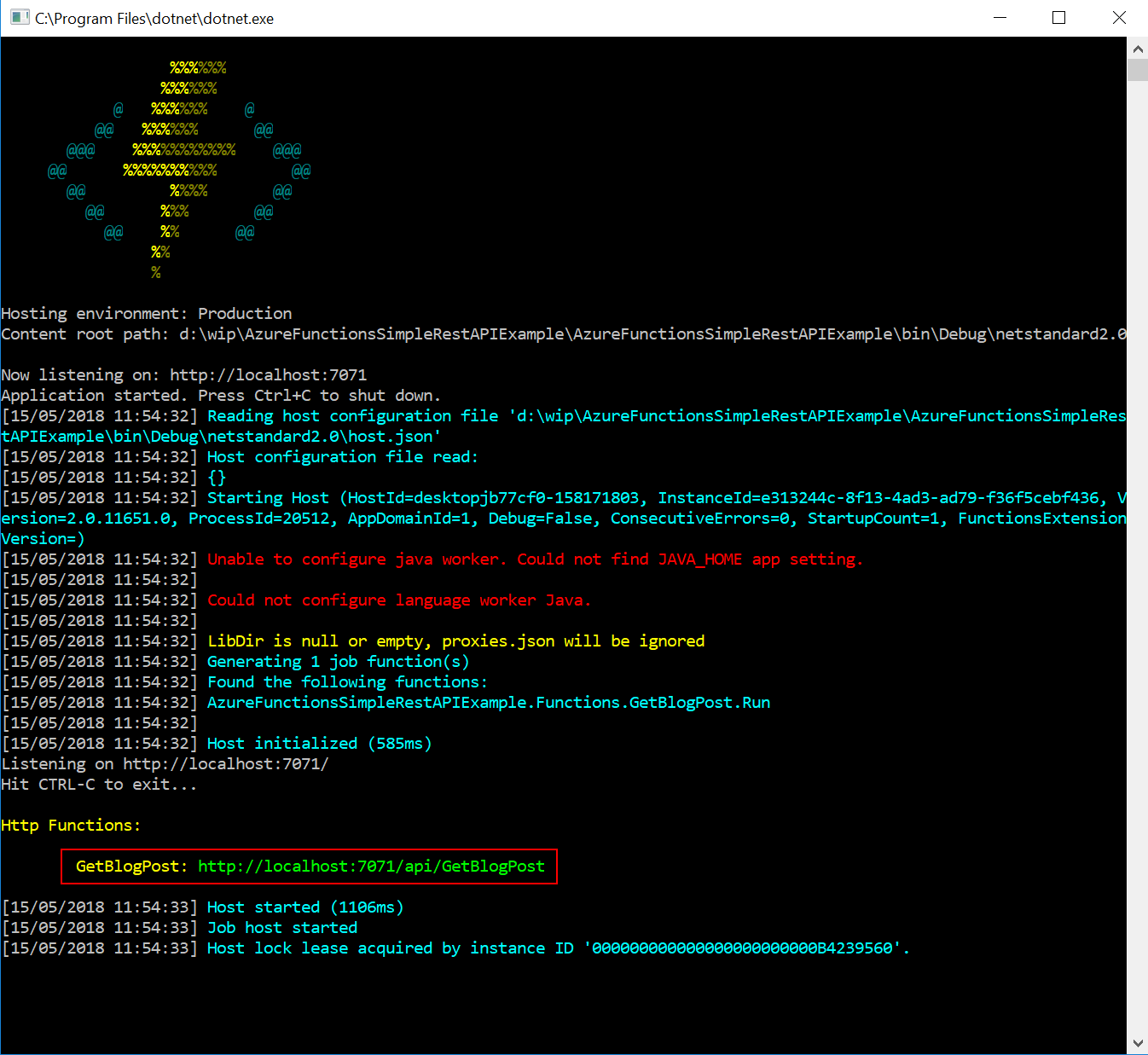
If you run the project you should see the Azure Functions local host start and a HTTP function that corresponds to our GetBlogPostQuery command being exposed:
The function naming uses a convention based approach which will give each function the same name as the command but remove a postfix of Command or Query – hence GetBlogPost.
If we run this in Postman we can see that it works as we’d expect – it runs the code in our GetBlogPostQueryHandler:
The example here is fairly simple but already a little cleaner than rolling out functions by hand. However it starts to come into its own when we have more Functions to define. Lets elaborate on our configuration block:
In this example we’ve defined more API endpoints and we’ve also introduced a Function with a storage queue trigger – this will behave just like our HTTP functions but instead of being triggered by an HTTP request will be triggered by an item on a queue and so applying the same principles to this trigger type (note: I haven’t yet pushed this to the public package).
You can also see me registering a dependency in our IoC container – this will be available for injection across the system and into any of our command handlers.
We’ve also added support for token based security with our Authorization block – this adds in a class that validates tokens and builds a ClaimsPrincipal from them which we can then use by mapping claims onto the properties of our commands. This works in exactly the same way as it does on my REST API commanding library and with or without claims mapping or Authorization sensitive properties can be prevented from user access with the SecurityPropertyAttribute in the same way as in the REST API library too.
The eagle eyed will have noticed that these packages I’ve referenced here are in preview (as is the v2 Azure Functions runtime itself) and for sure I still have more work to do but they are already usable and I’m using them in three different serverless projects at the moment – as such development on them is moving quite fast, I’m essentially dogfooding.
As a rough roadmap I’m planning on tackling the following things (no particular order, they’re all important before I move out of beta):
Fix bugs and tidy up code (see 6. below)
Documentation
Validation of input (commands)
Open API / Swagger generation
Additional trigger / function support
Return types
Automated tests – lots of automated tests. Currently the framework is not well covered by automation tests – mainly because this was a non-trivial thing to figure out. I wasn’t quite sure what was going to work and what wouldn’t and so a lot of the early work was trying different approaches and experimenting. Now all that’s settled down I need to get some tests written.
I’ve pushed this out as a couple of people have been asking if they can take a look and I’d really like to get some feedback on it. The code for the implementation of the NuGet packages is in GitHub here (make sure you’re in the develop branch).
Please do let me have any feedback over on Twitter or on the GitHub Issues page for this project.
A while back I wrote about the improvements Microsoft were working on in regard to the HTTP trigger function scaling issues. The Functions team got in touch with me this week to let me know that they had an initial set of improvements rolling out to Azure.
To get an idea of how significant these improvements are I’m first going to contrast this new update to Azure Functions with my previous measurements and then re-examine Azure Functions in the wider context of the other cloud vendors. I’m specifically separating out the Azure vs Azure comparison from the Azure vs Other Cloud Vendors comparison as while the former is interesting given where Azure found itself in the last set of tests and to highlight how things have improved but isn’t really relevant in terms of a “here and now” vendor comparison.
A quick refresh on the tests – the majority of them are run with a representative typical real world mix of a small amount of compute and a small level of IO though tests are included that remove these and involve no IO and practically no computer (return a string).
Although the improvements aren’t yet enabled by default towards the end of this post I’ll highlight how you can enable these improvements for your own Function Apps.
Azure Function Improvements
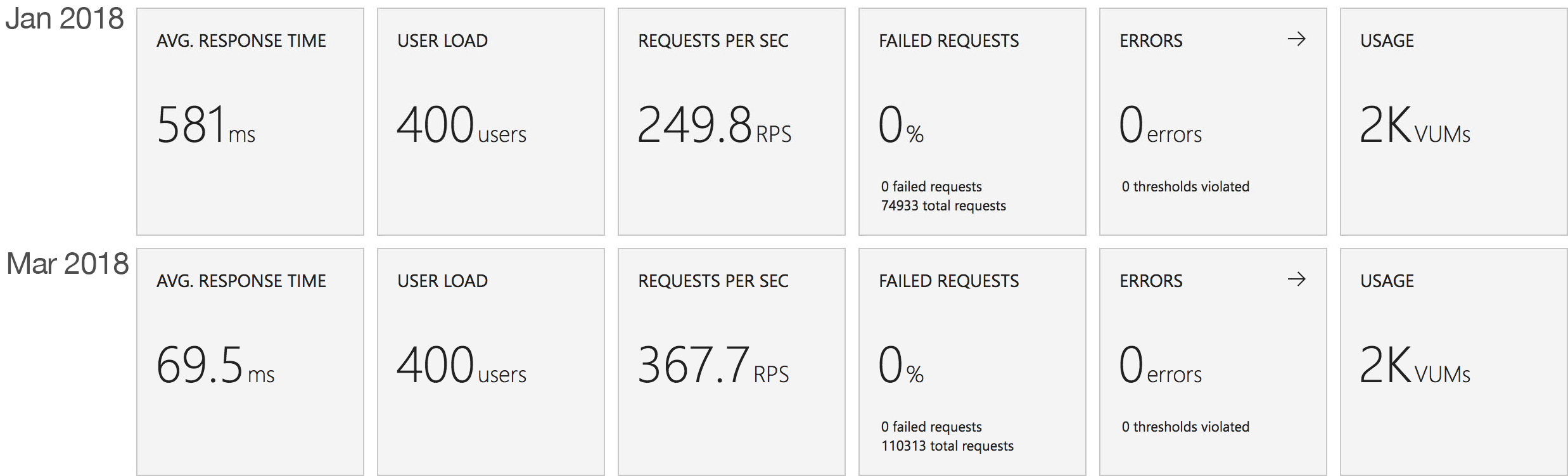
First I want to take a look at Azure Functions in isolation and see just how the new execution and scaling model differs from the one I tested in January. For consistency the tests are conducted against the exact same app I tested back in January using the same VSTS environment.
Gradual Ramp Up
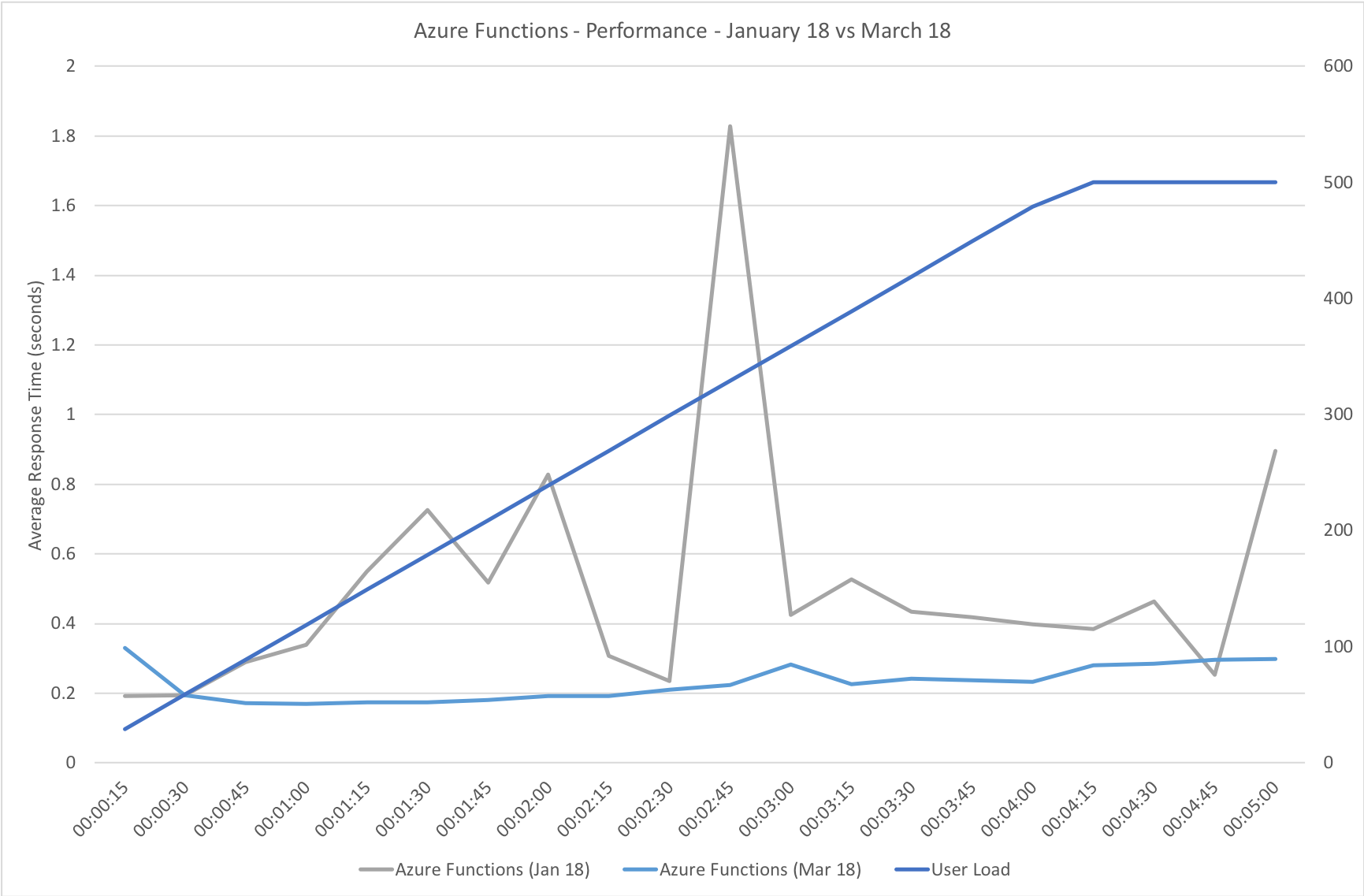
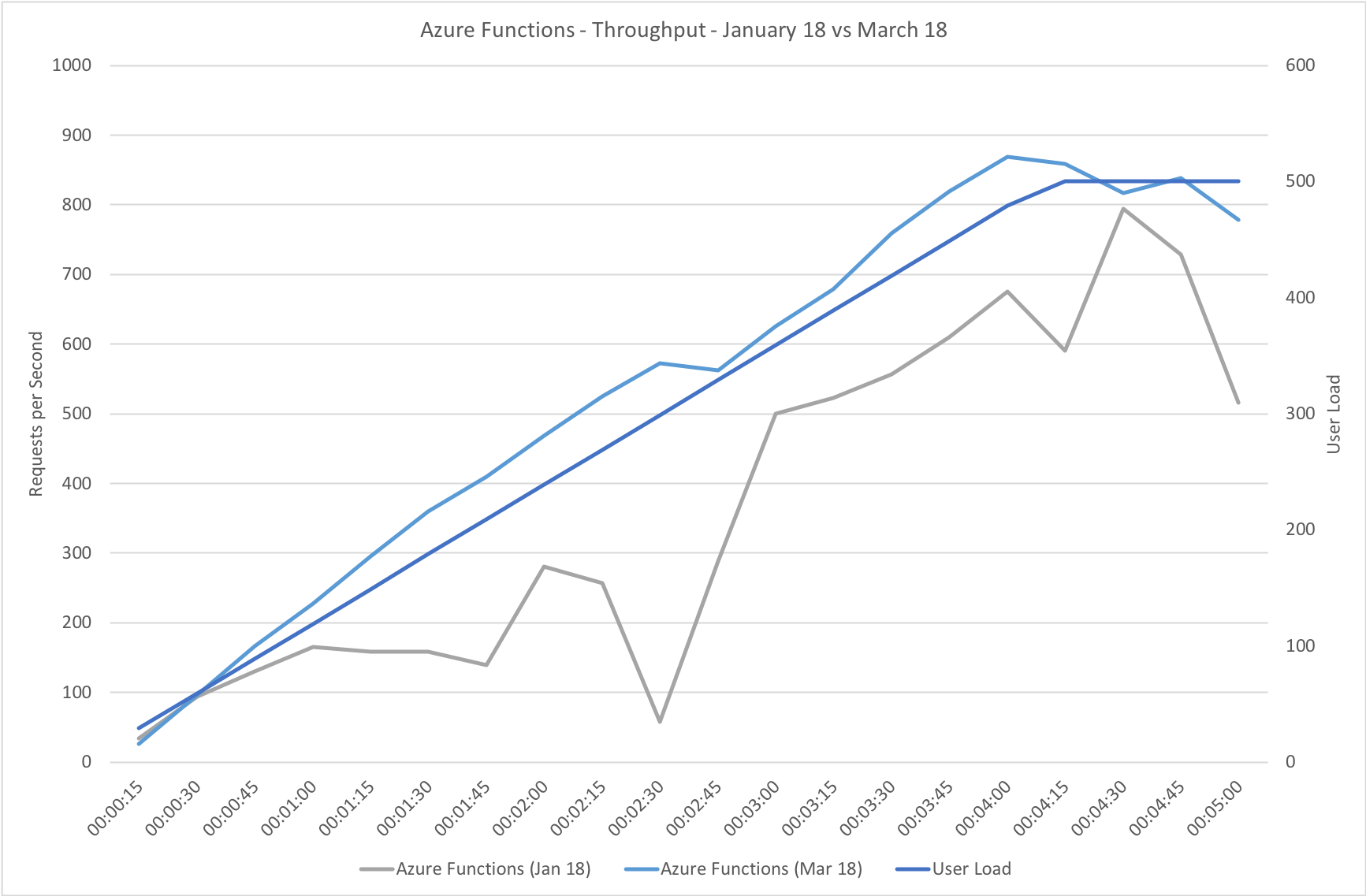
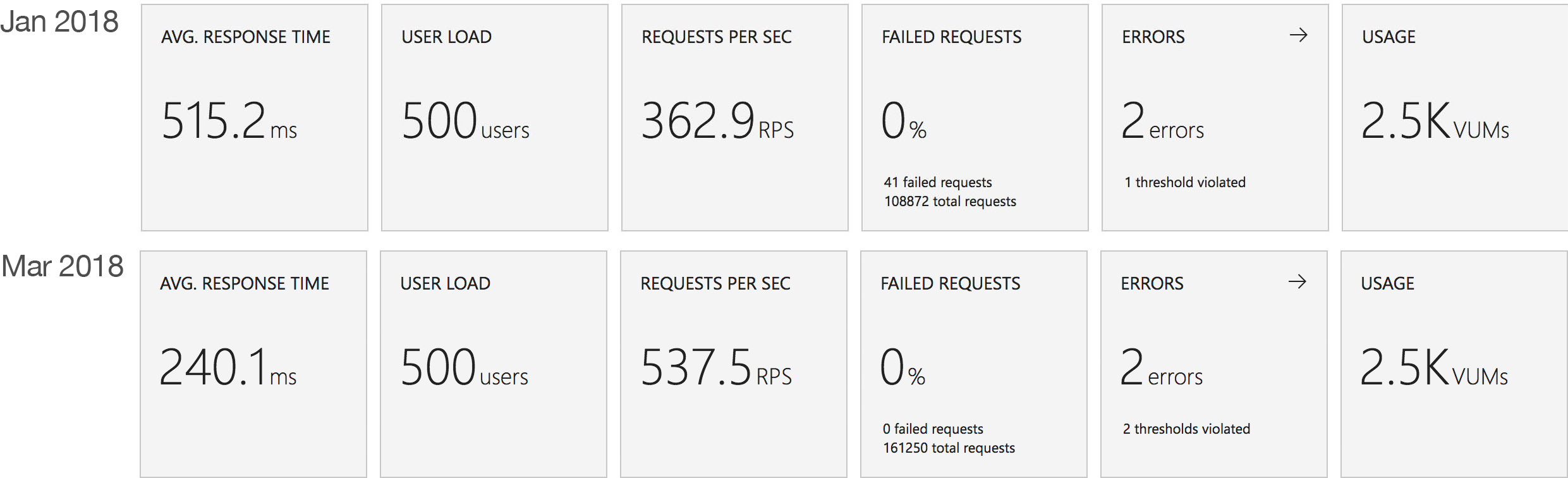
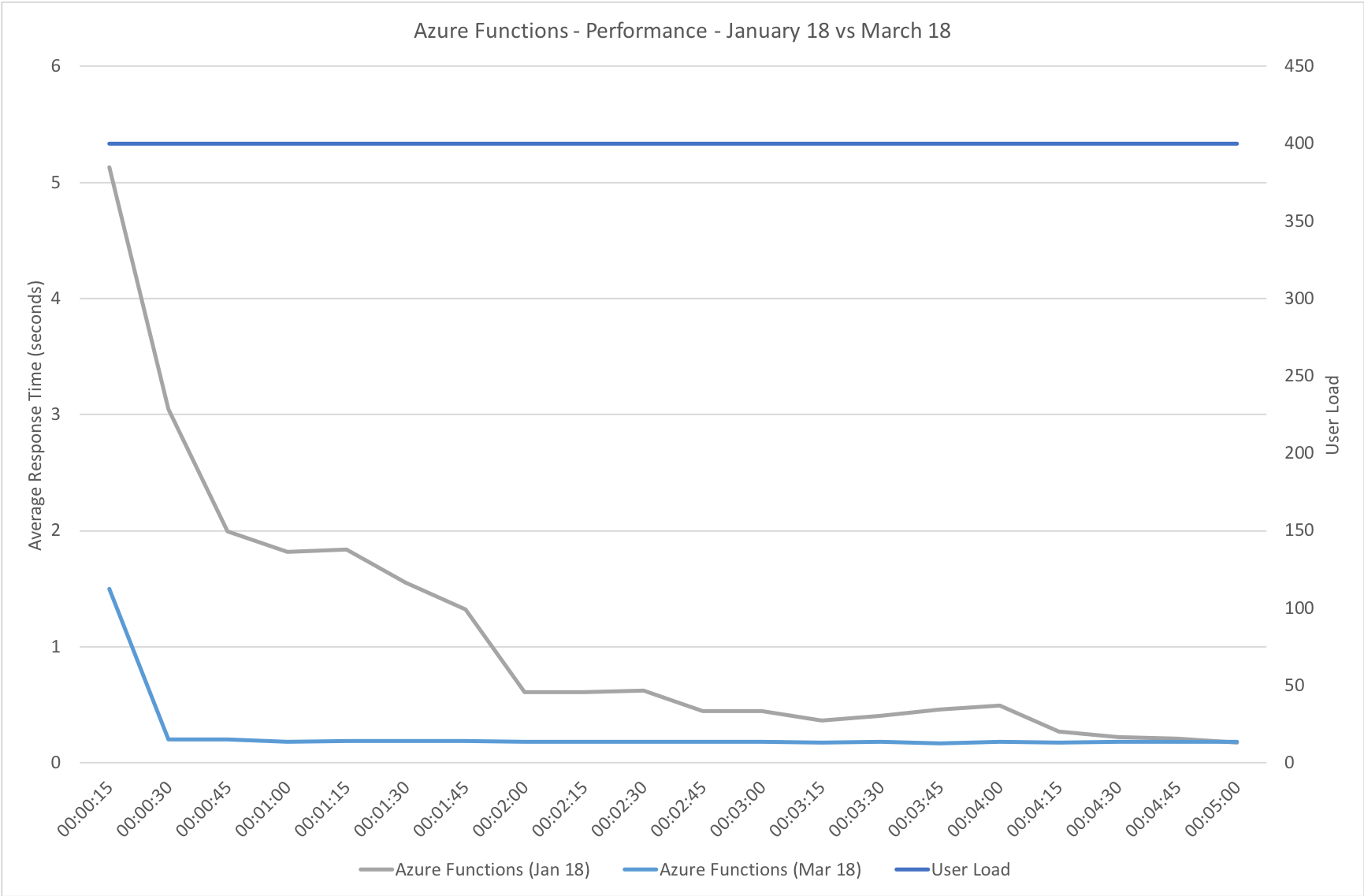
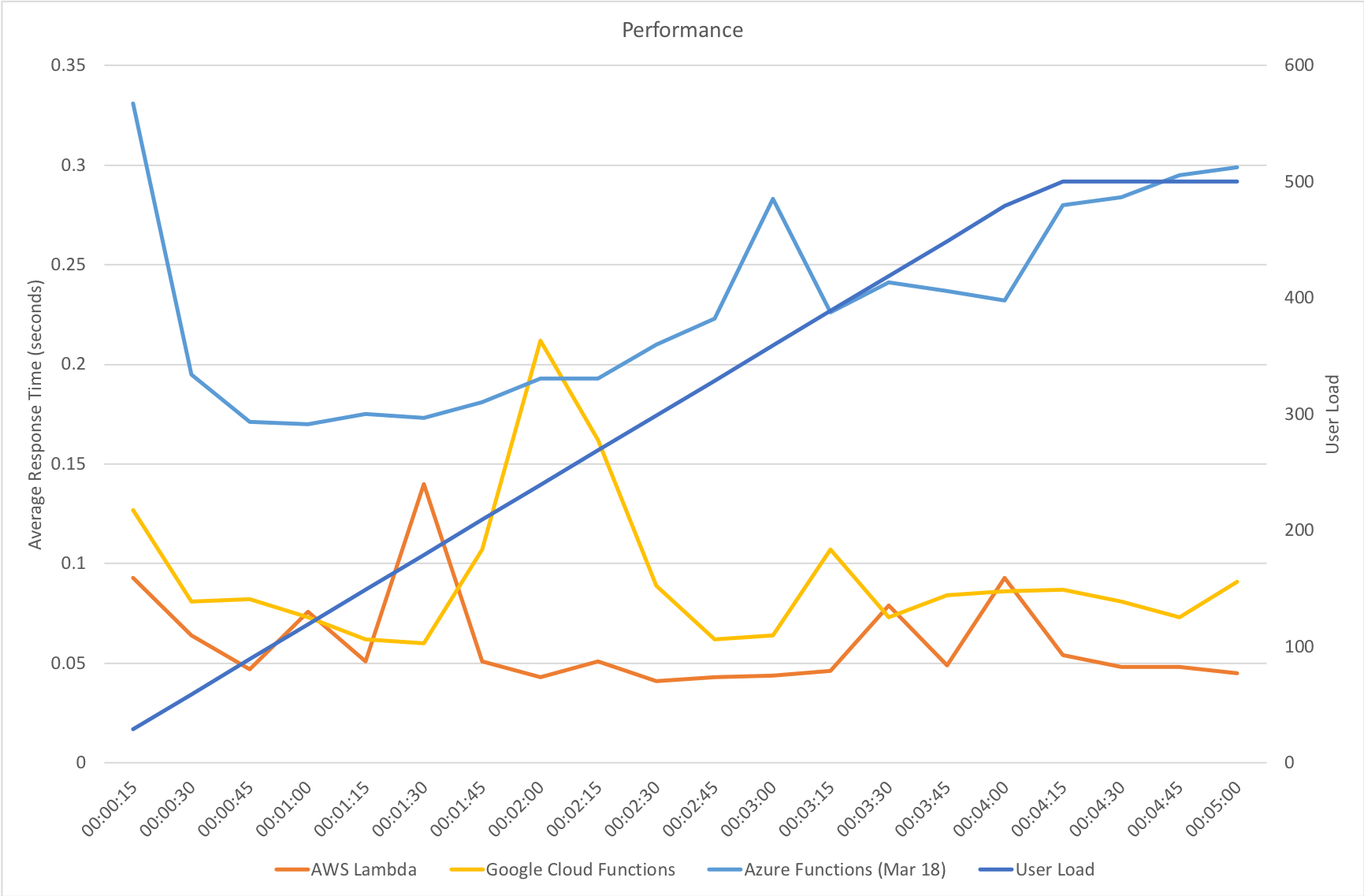
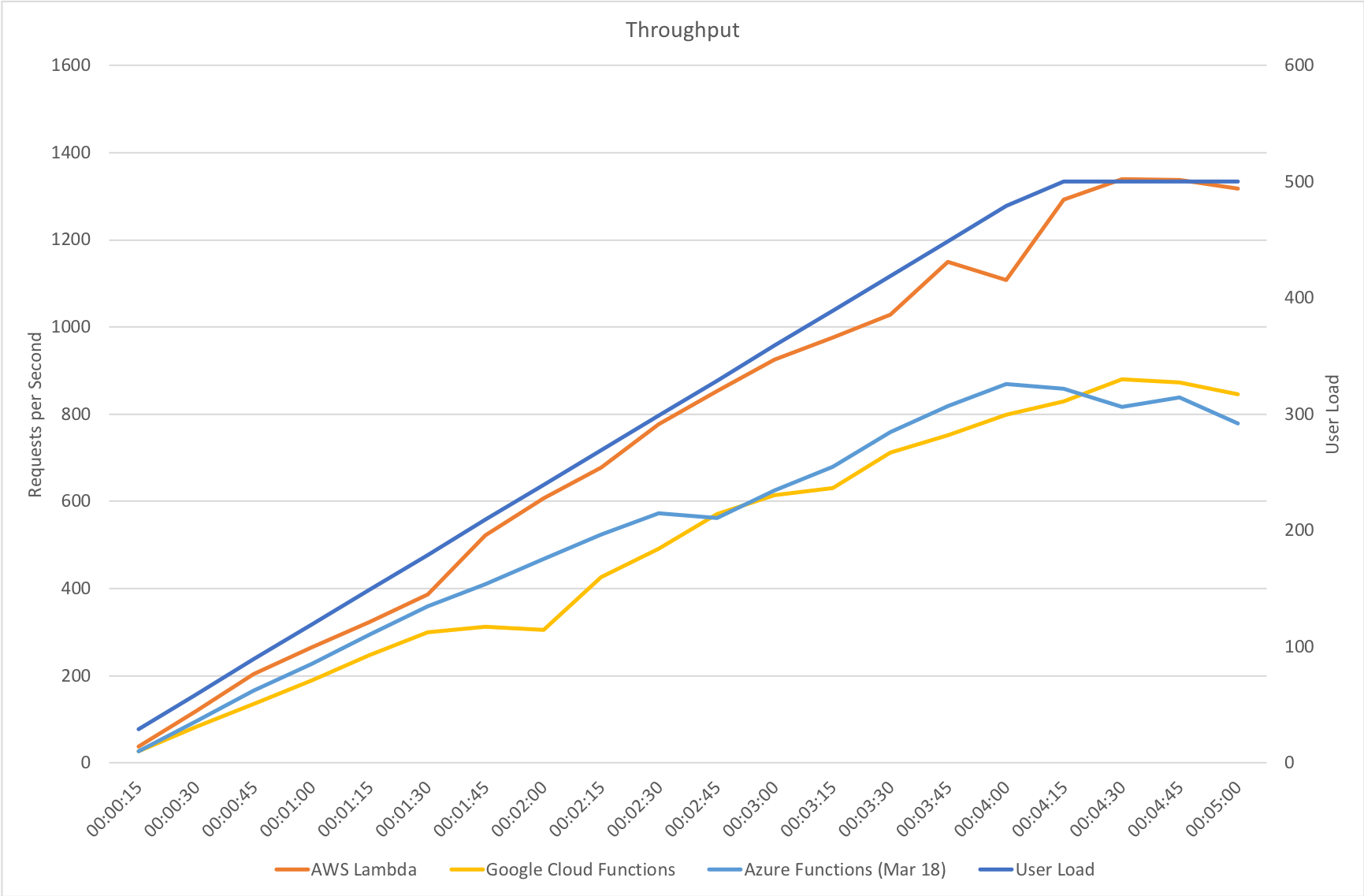
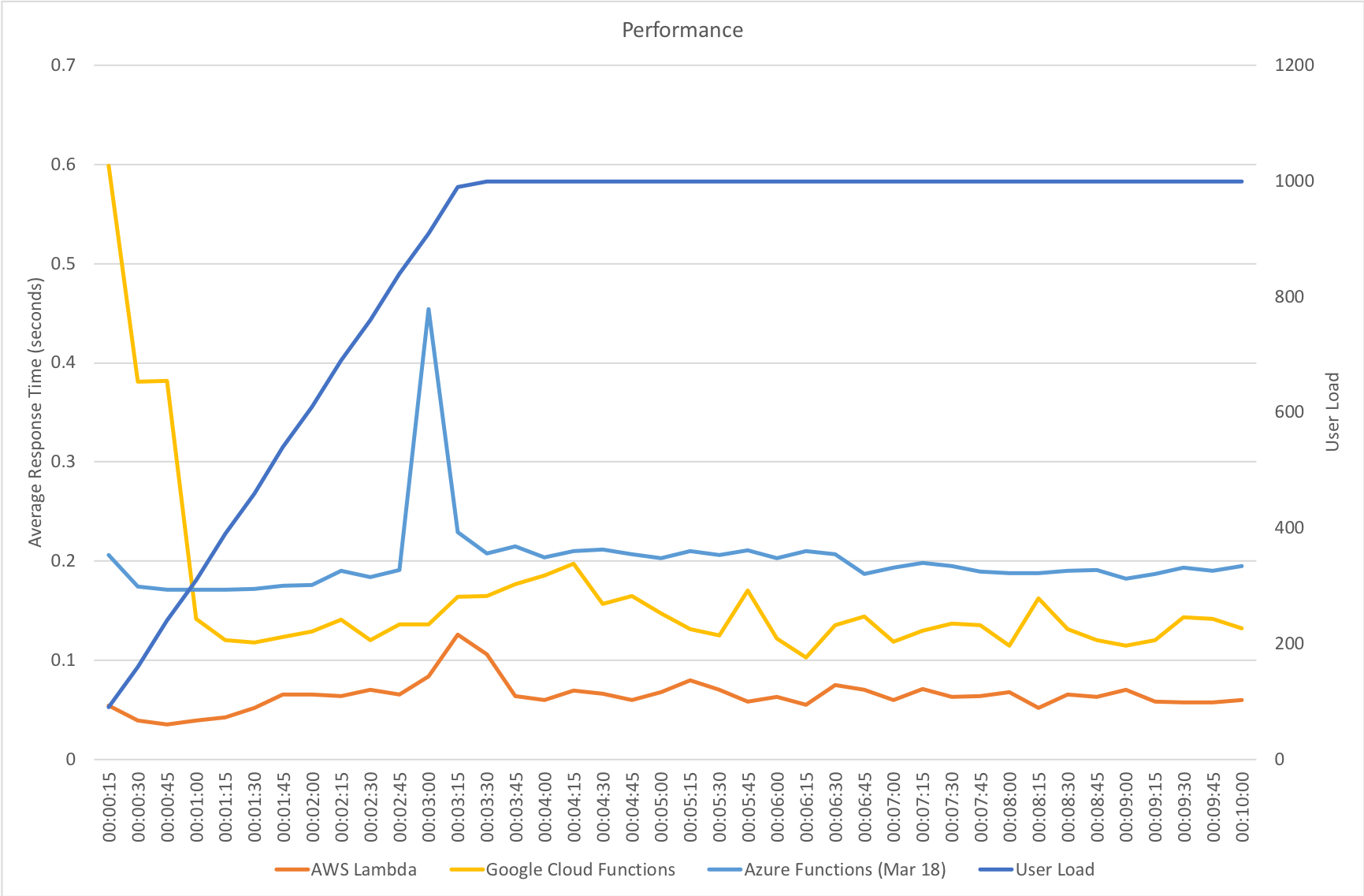
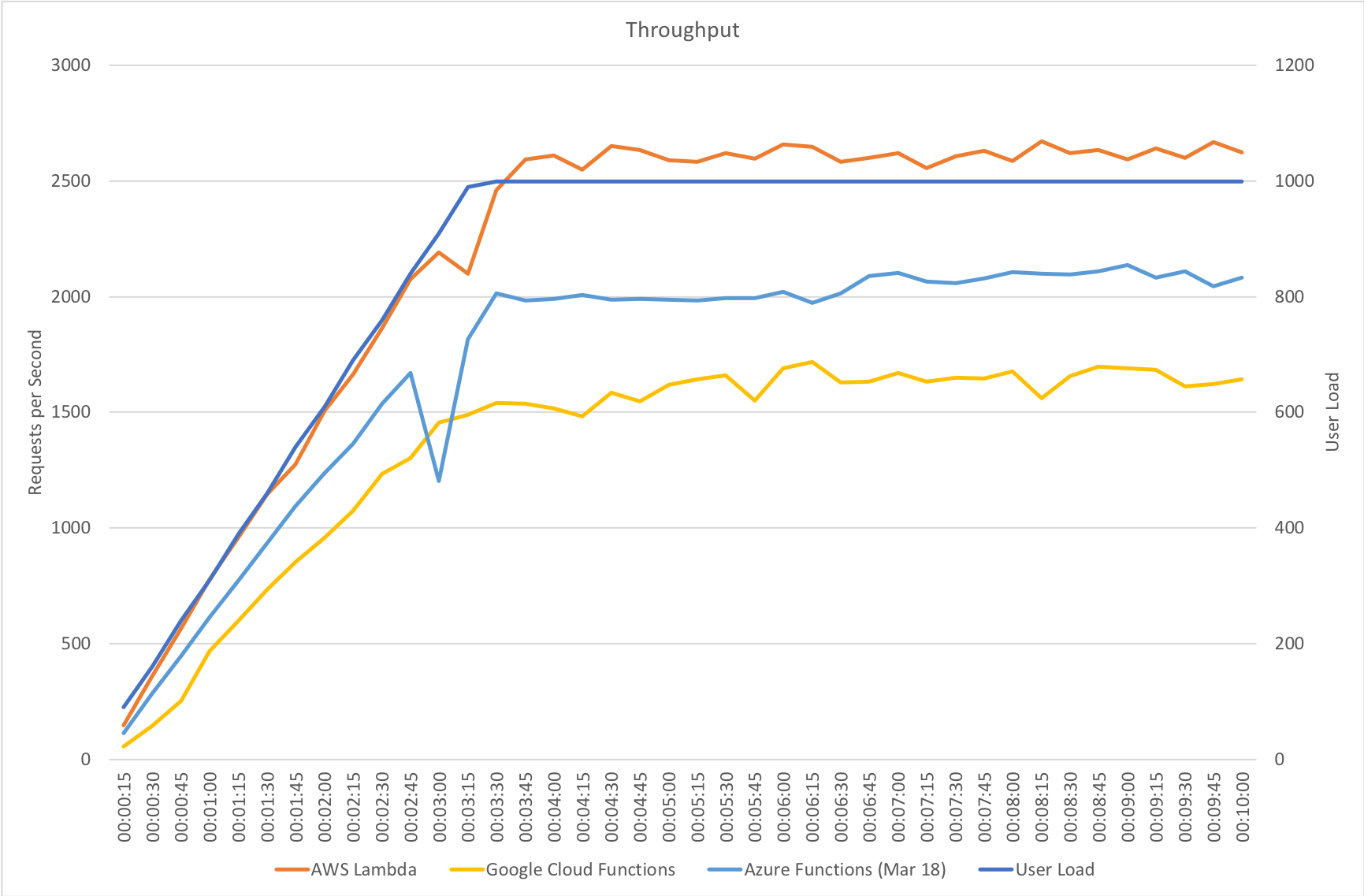
This test case starts with 1 user and adds 2 users per second up to a maximum of 500 concurrent users to demonstrate a slow and steady increase in load.
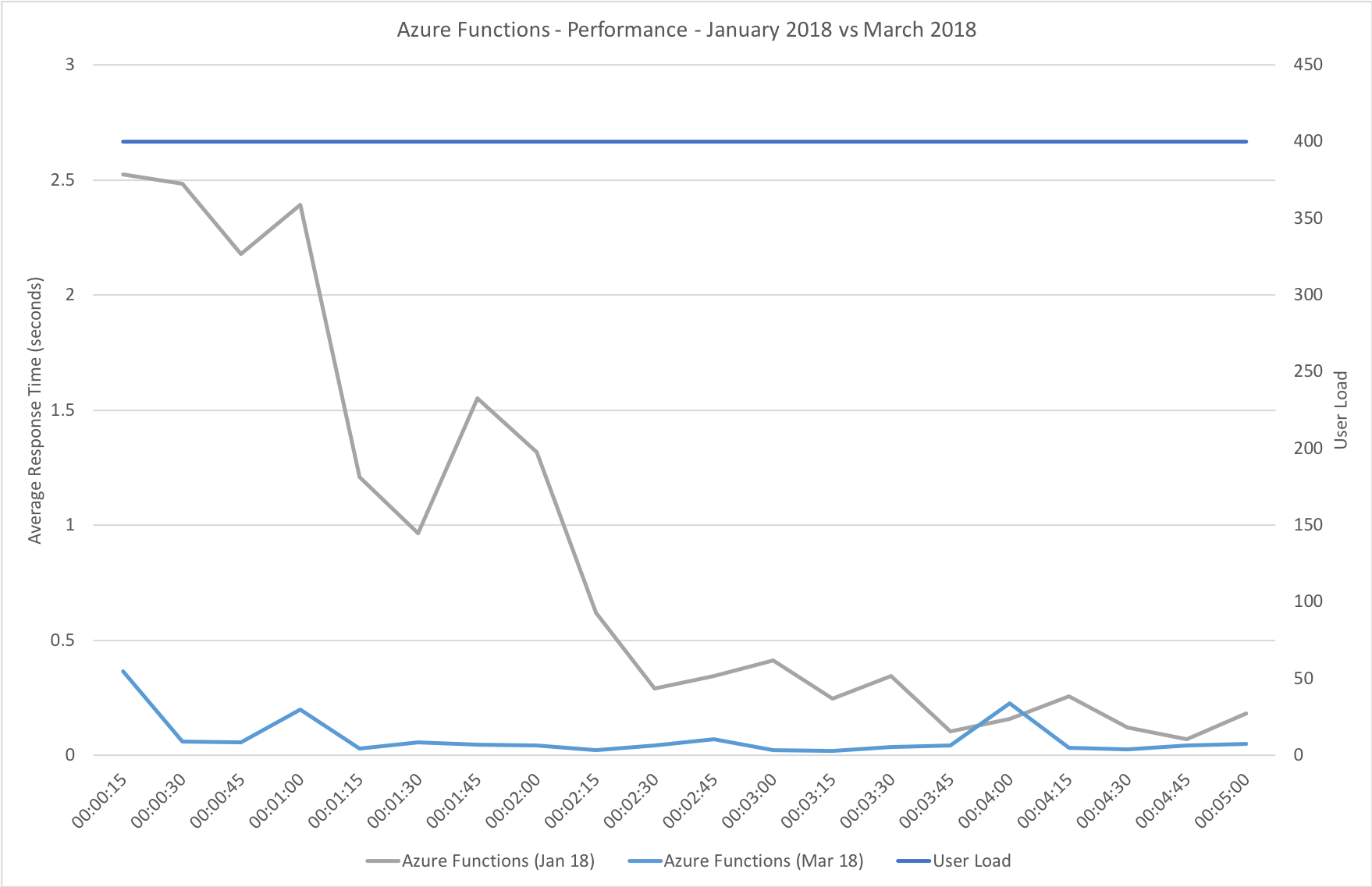
This is the least demanding of my tests but we can immediately see how much better the new Functions model performs. When I ran these tests in January the response time was very spiky and averaged out around the 0.5 second mark – the new model holds a fairly steady 0.2 seconds for the majority of the run with a slight increase at the tail and manages to process over 50% more requests.
Rapid Ramp Up
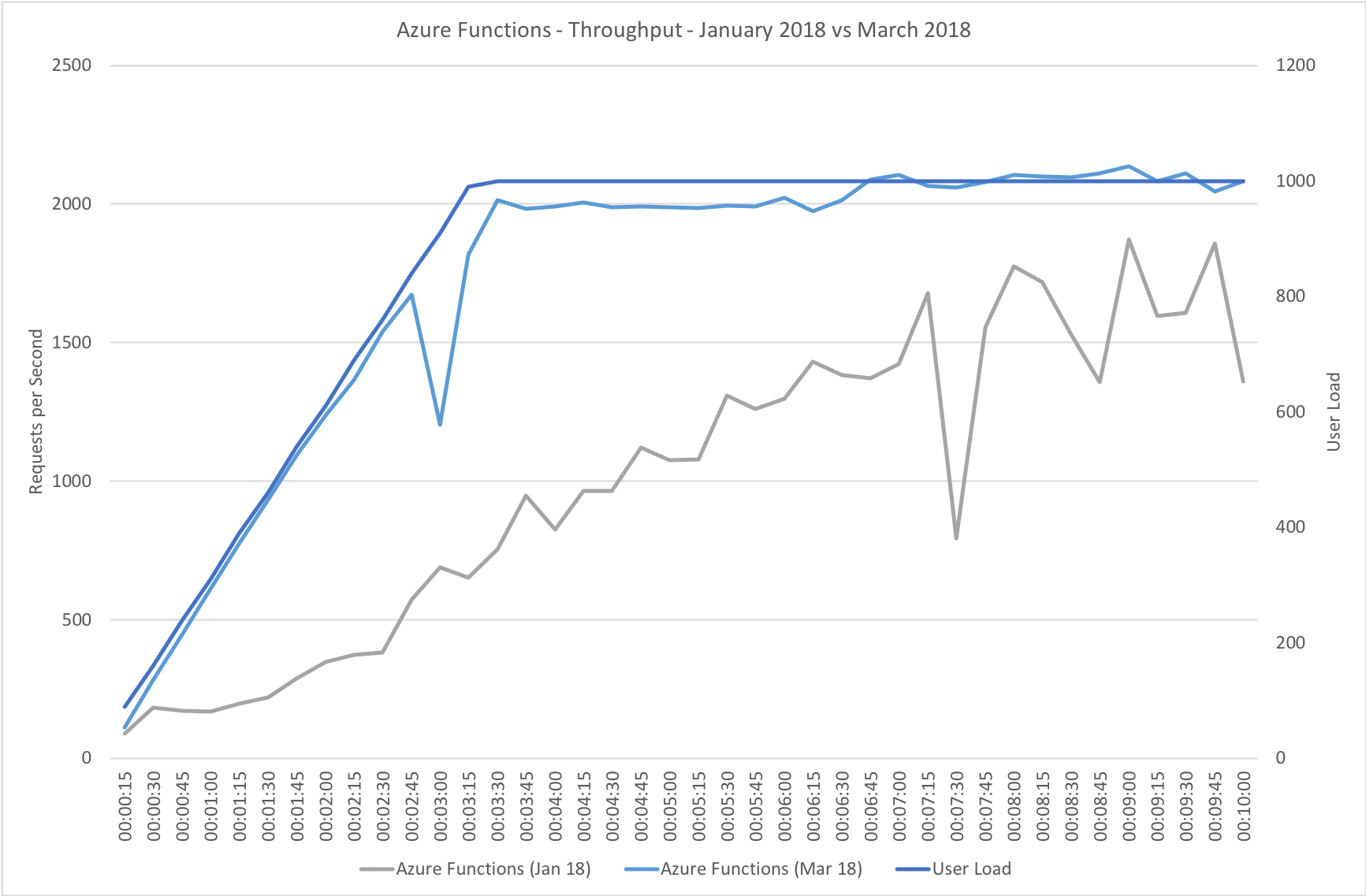
This test case starts with 10 users and adds 10 users every 2 seconds up to a maximum of 1000 concurrent users to demonstrate a more rapid increase in load and a higher peak concurrency.
In the previous round of tests Azure Functions really struggled to keep up with this rate of growth. After a significant period of stability in user volume it eventually reached a state of being semi-acceptable but the data vividly showed a system really straining to respond and gave me serious concerns about its ability to handle traffic spikes. In contrast the new model grows very evenly with the increasing demand and, other than a slight spike early on, maintaining a steady response time throughout.
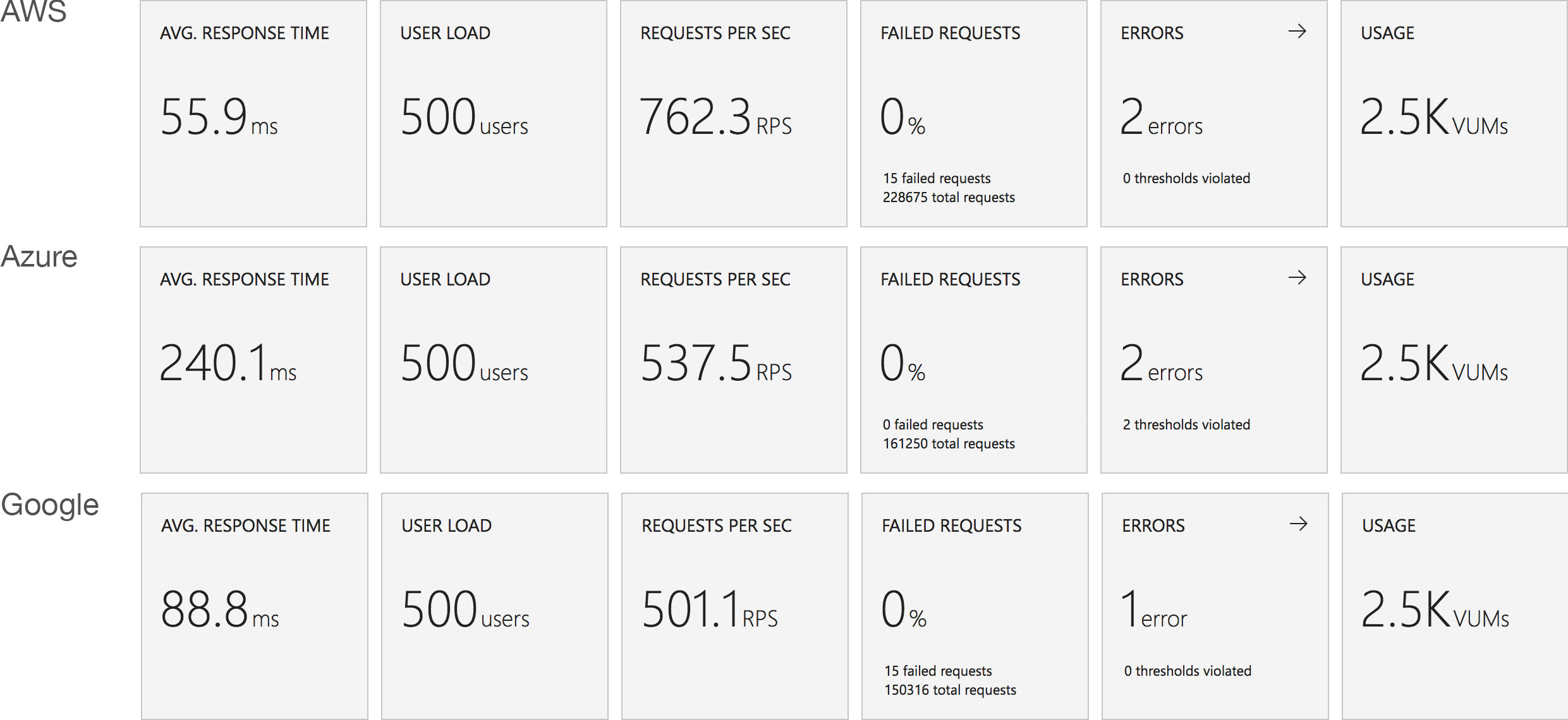
Immediate High Demand
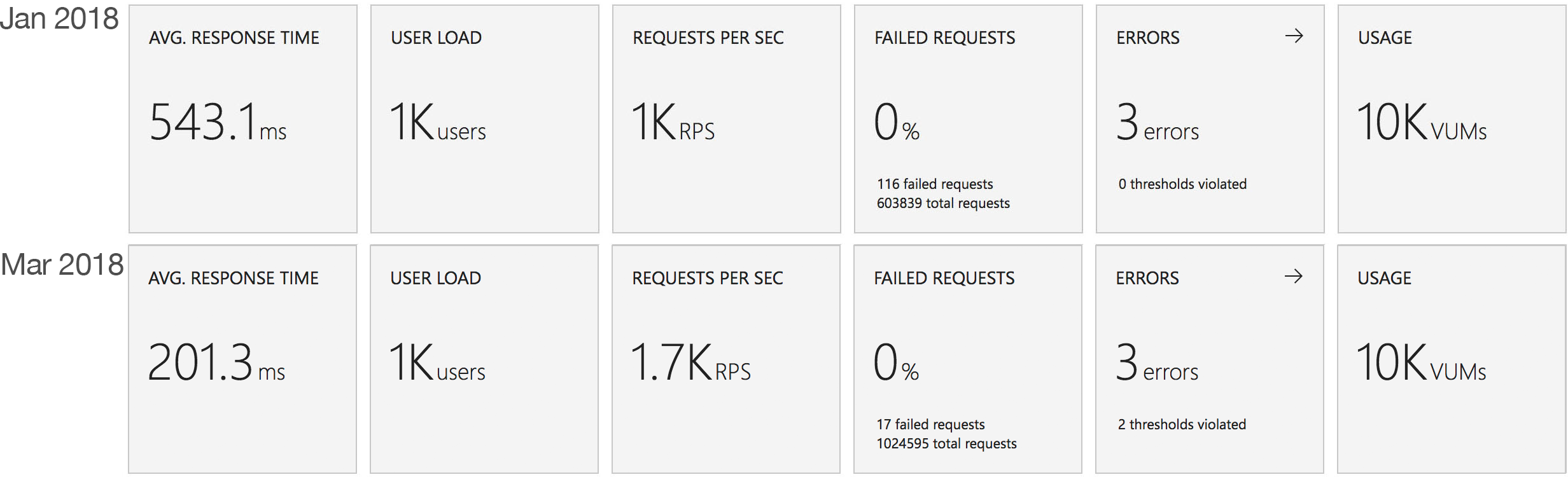
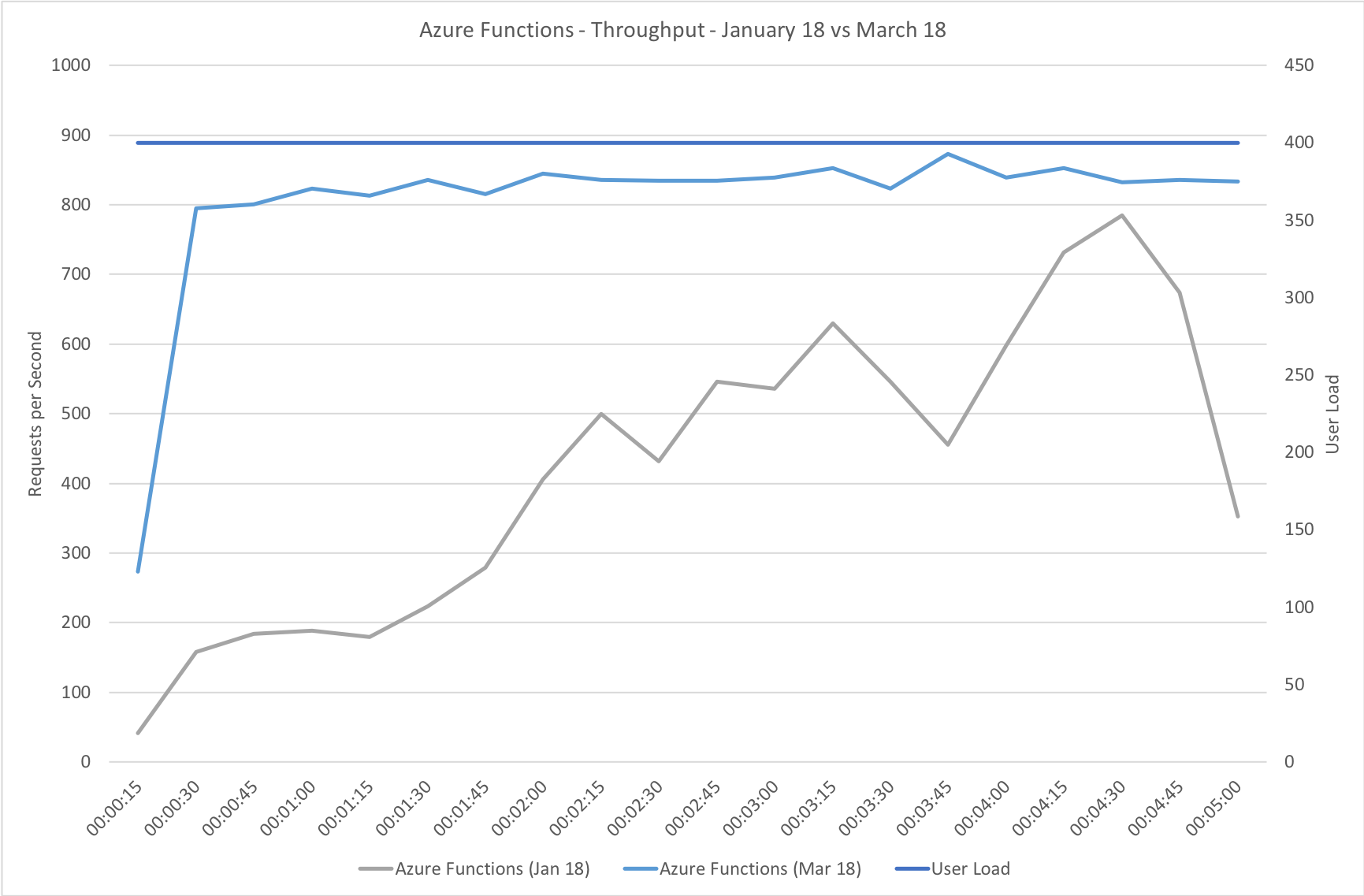
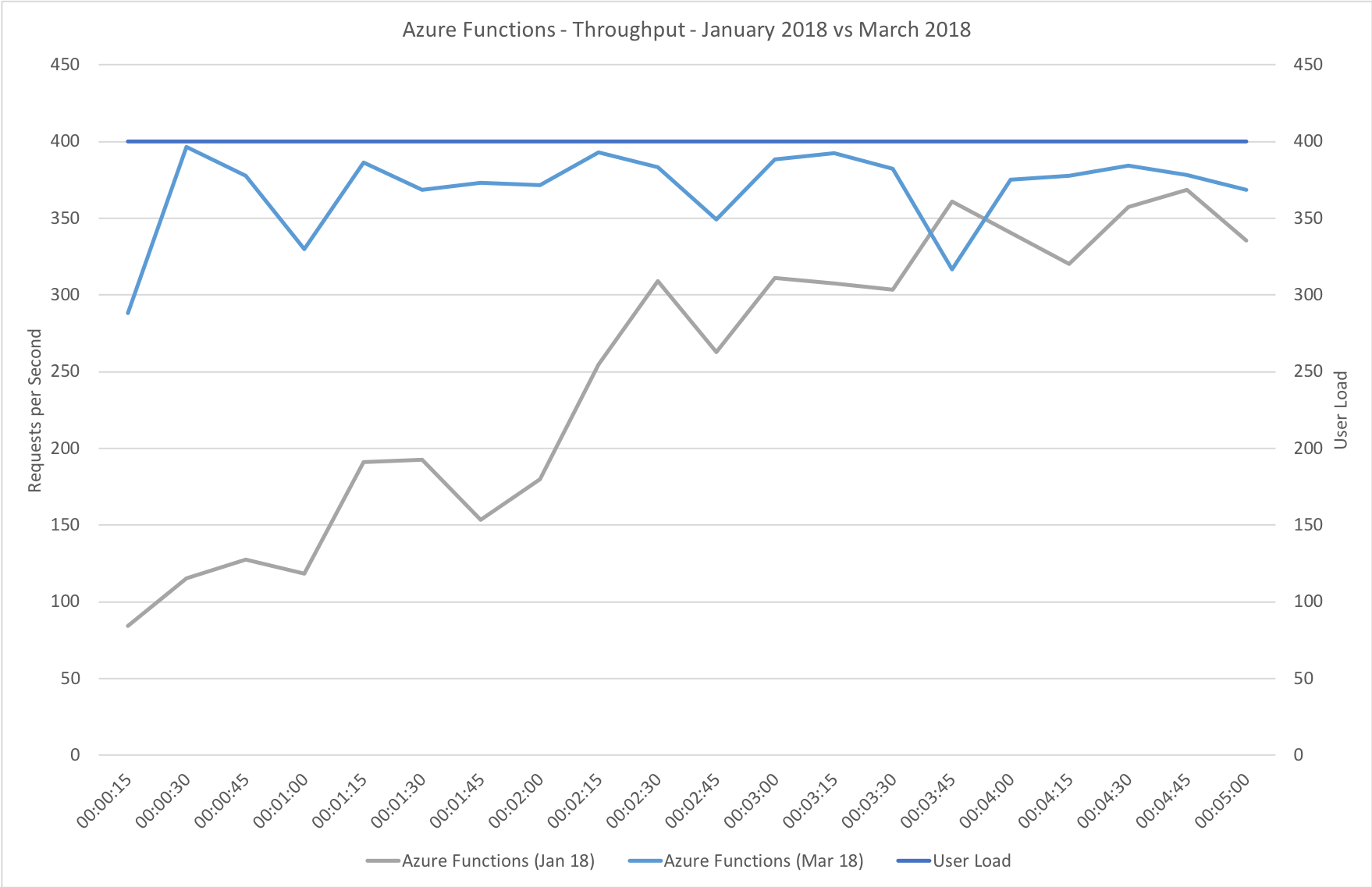
This test case starts immediately with 400 concurrent users and stays at that level of load for 5 minutes demonstrating the response to a sudden spike in demand.
Again this test highlights what a significant improvement has been made in how Azure Functions responds to demand – the new model is able to deal with the sudden influx of users immediately, whereas in January it took nearly the full execution of the test for the system to catch up with the demand.
Stock Functions
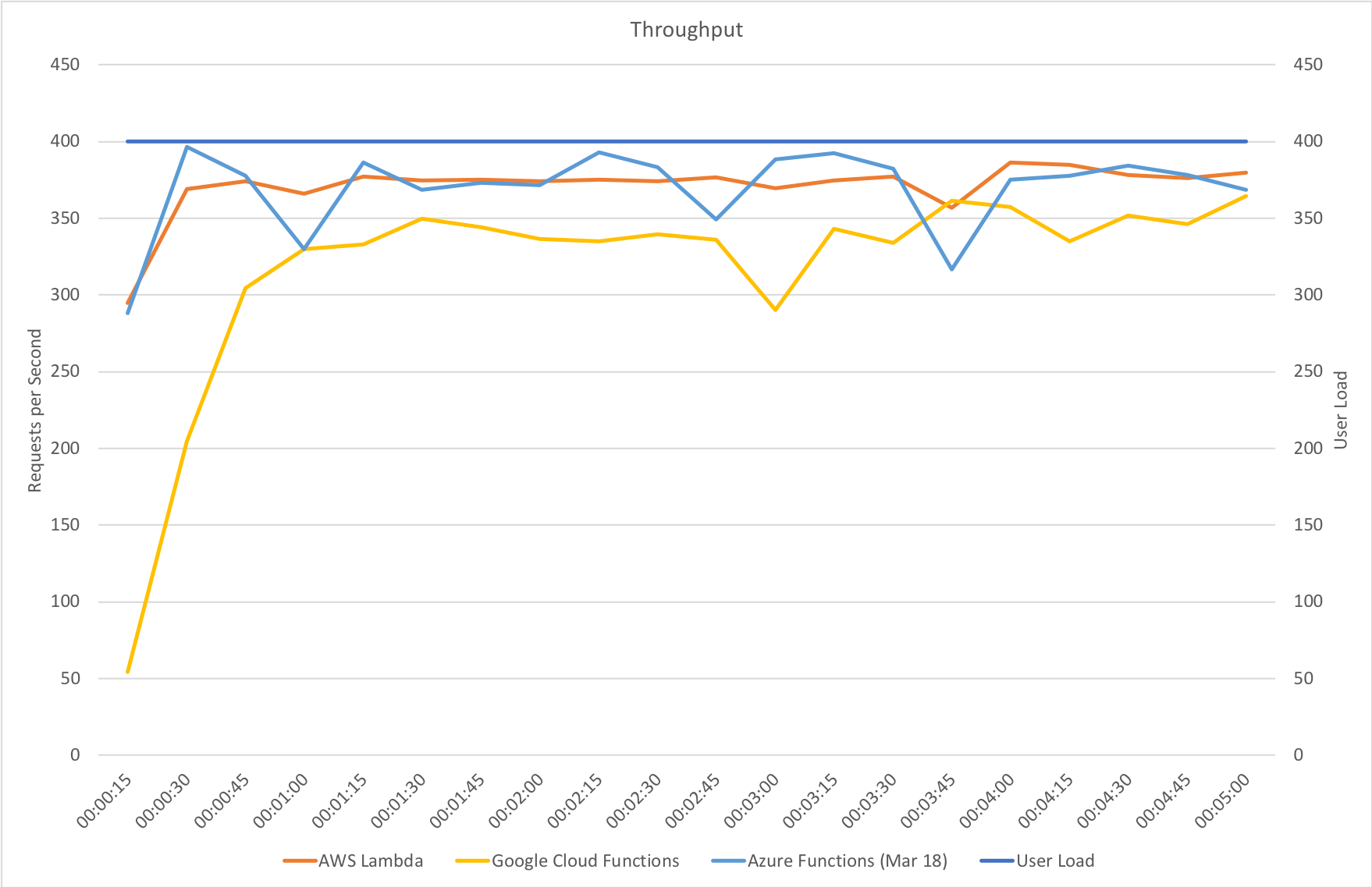
This test uses the stock “return a string” function provided by each platform (I’ve captured the code in GitHub for reference) with the immediate high demand scenario: 400 concurrent users for 5 minutes.
The minimalist nature of this test (return a string) very much highlights the changes made to the Azure Functions hosting model and we can see that not only is there barely any lag in growing to meet the 400 user demand but that response time has been utterly transformed. It’s, to say the least, a significant improvement over what I saw in January when even with essentially no code to execute and no IO to perform Functions suffered from horrendous performance in this test.
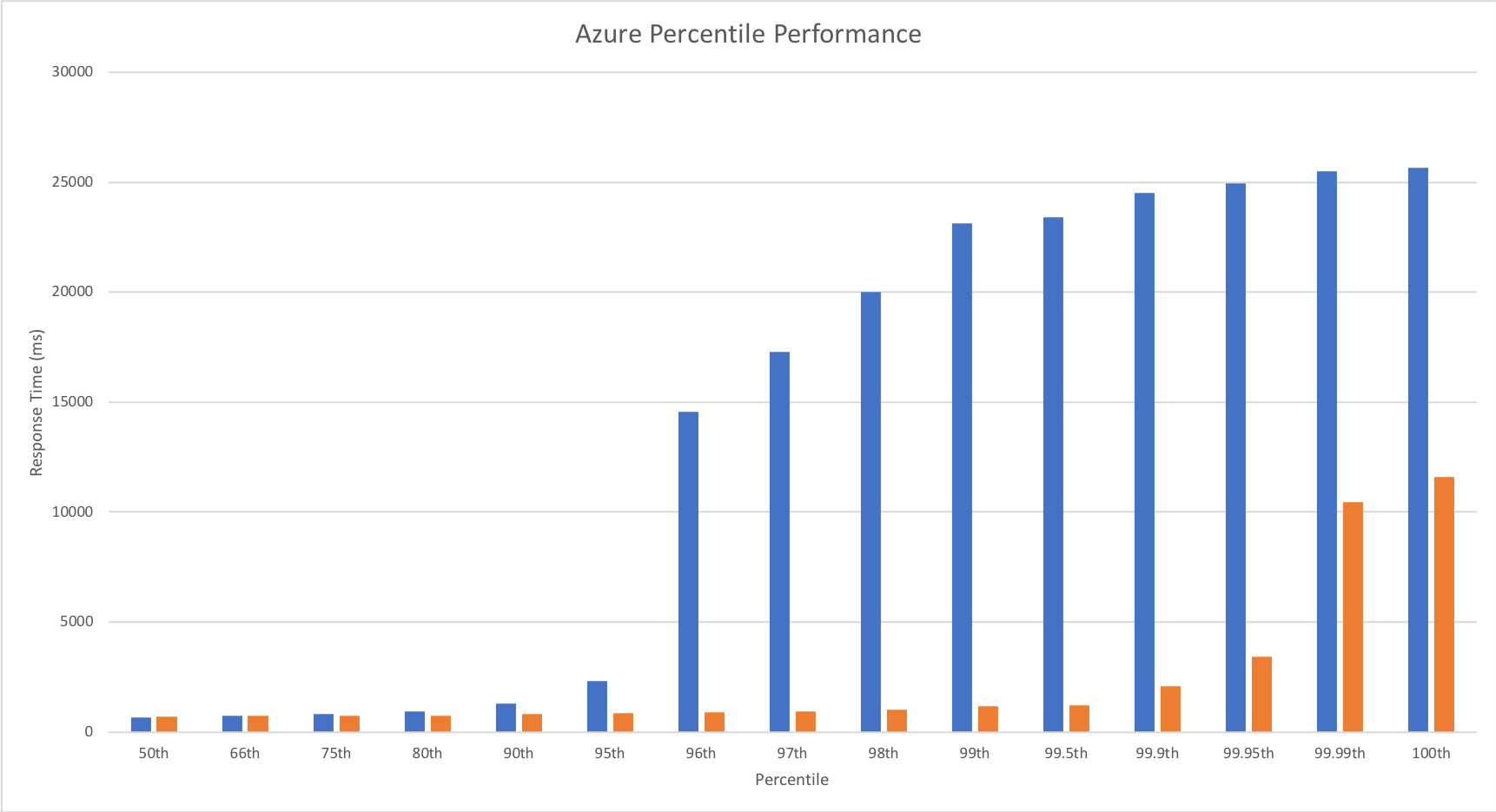
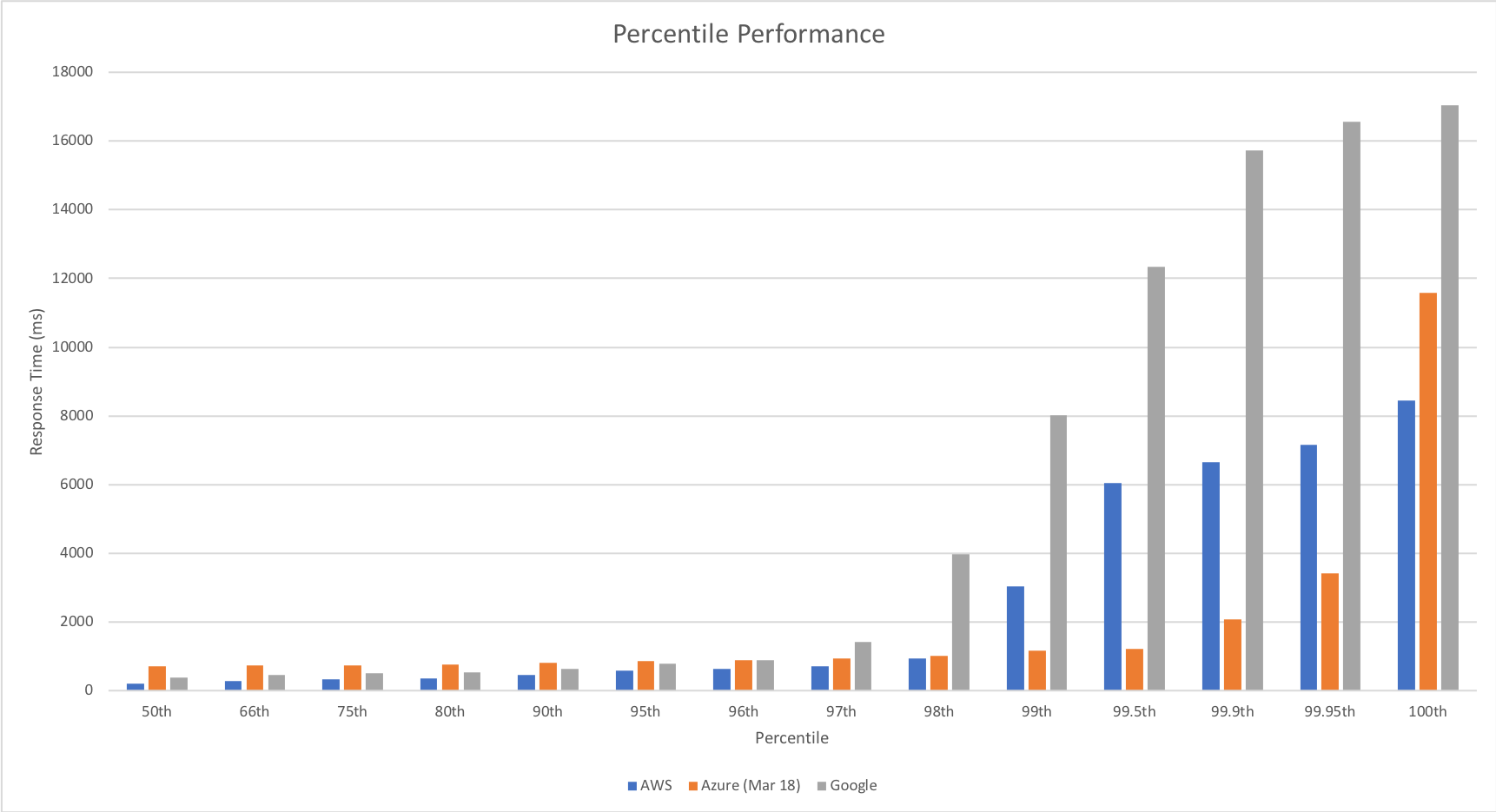
Percentile Performance
I was unable to obtain this data from VSTS and so resorted to running Apache Benchmarker. For this test I used settings of 100 concurrent requests for a total of 10000 requests, collected the raw data, and processed it in Excel. It should be noted that the network conditions were less predictable for these tests and I wasn’t always as geographically close to the cloud function as I was in other tests though repeated runs yielded similar patterns:
Yet again we can see the massive improvements made by the Azure Functions team – performance remains steady up until 99.9th percentile. Full credit to the team – the improvement here is so significant that I actually had to add in the fractional percentiles to uncover the fall off.
Revised Comparison With Other Vendors
We can safely say by now that this new hosting model for Azure Functions is a dramatic improvement for HTTP triggered functions – but how does it compare with the other vendors? Last time round Functions was barely at the party – this time… lets see!
Gradual Ramp Up
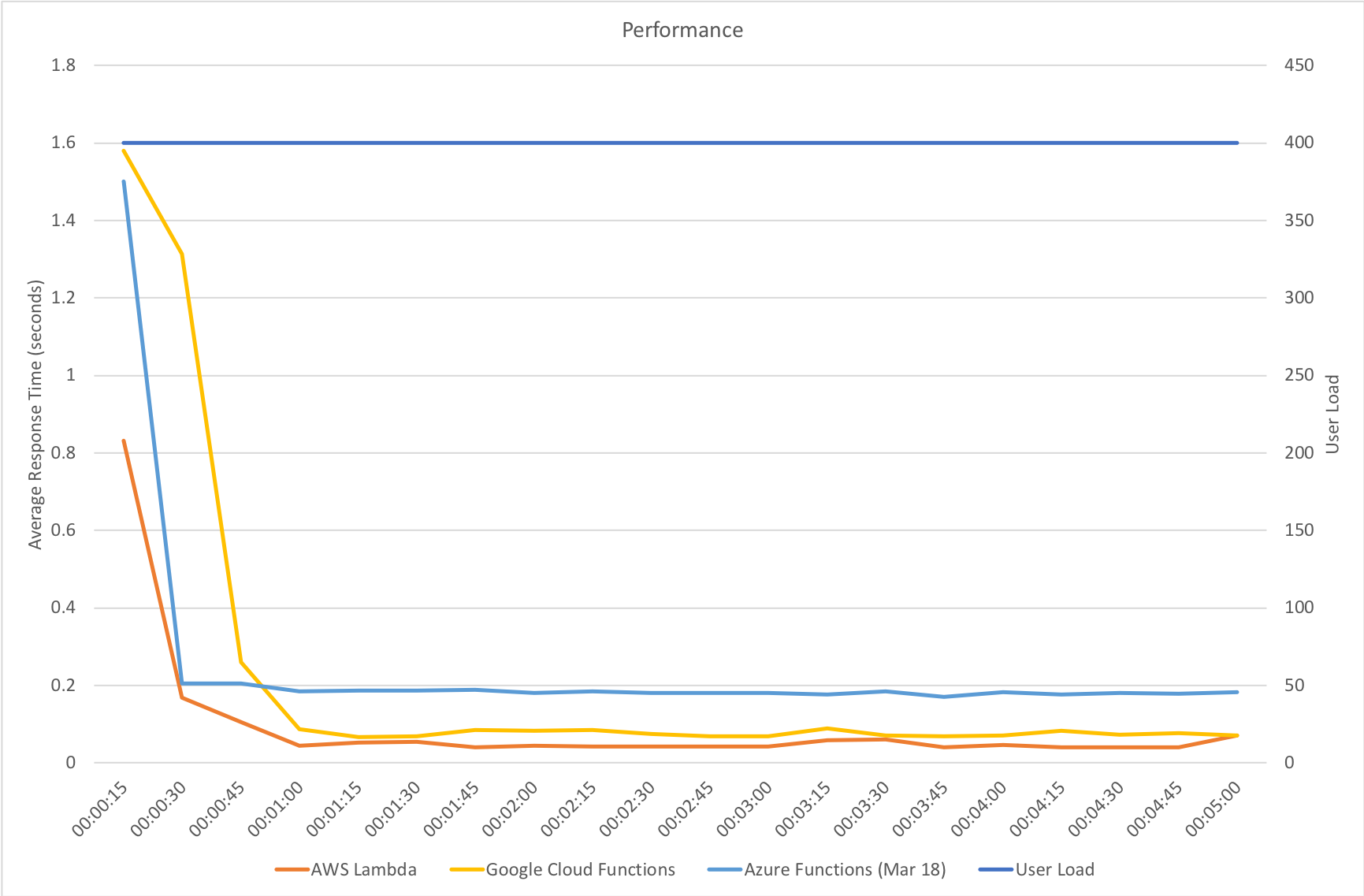
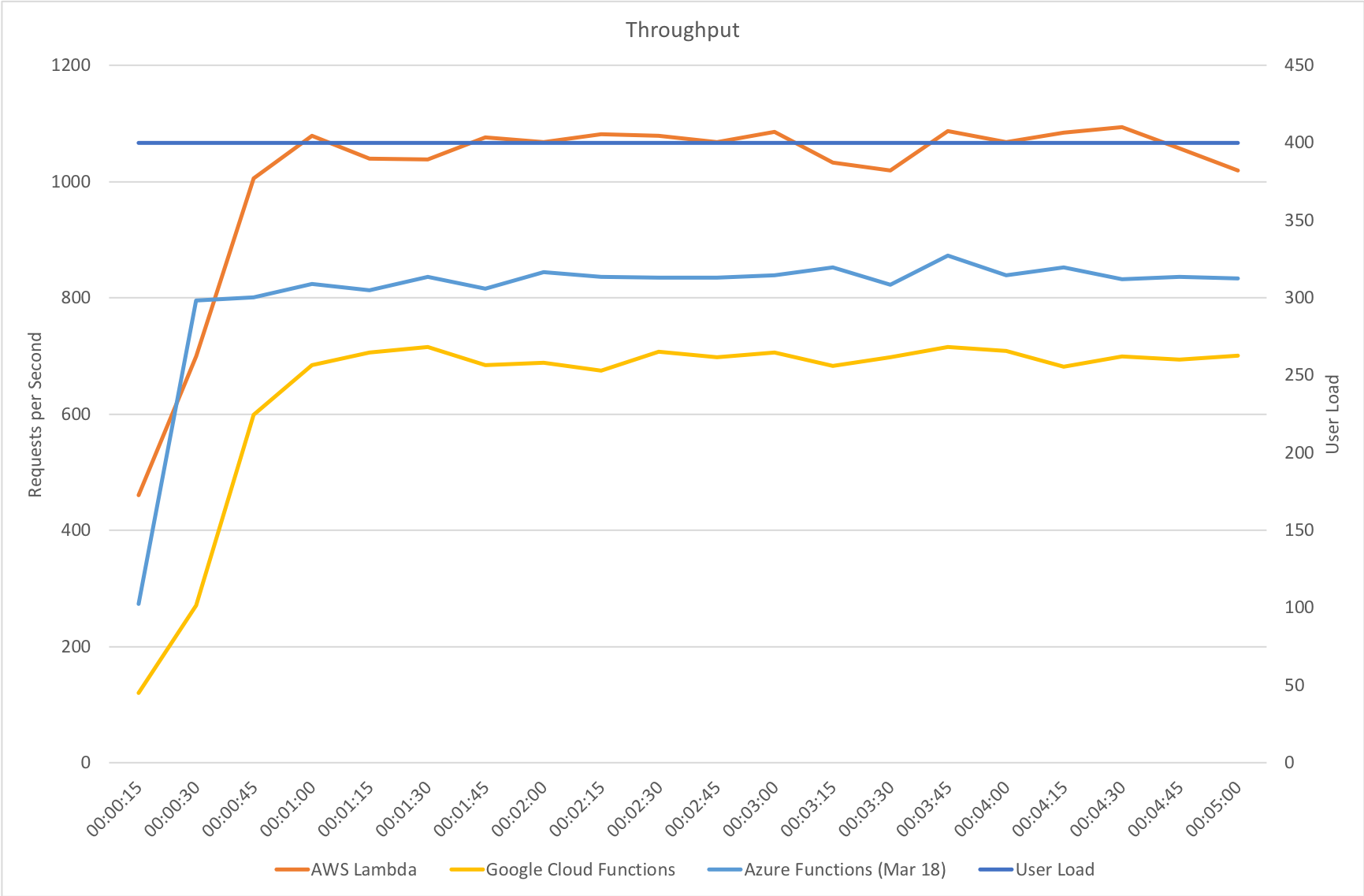
On our gradual ramp up test Azure still lags behind both AWS and Google in terms of response time but actually manages a higher throughput than Google. As demand grows Azure is also experiencing a slight deterioration in response time where the other vendors remain more constant.
Rapid Ramp Up
Response time and throughput results for our rapid ramp up test are not massively dissimilar to the gradual ramp up test. Azure experiences a significant fall in performance around the 3 minute mark as the number of users approaches 1000 – but as I said earlier the Functions team are working on further area at this level of scale and beyond and I would assume at this point that some form of resource reallocation is causing this that needs smoothing out.
It’s also notable that although some way behind AWS Lambda Azure manages a reasonably higher throughput that Google Cloud – in fact it’s almost half way between the two competing vendors so although response times are longer there seems to be more overall capacity which could be an important factor in any choice between those two platforms.
Immediate High Demand
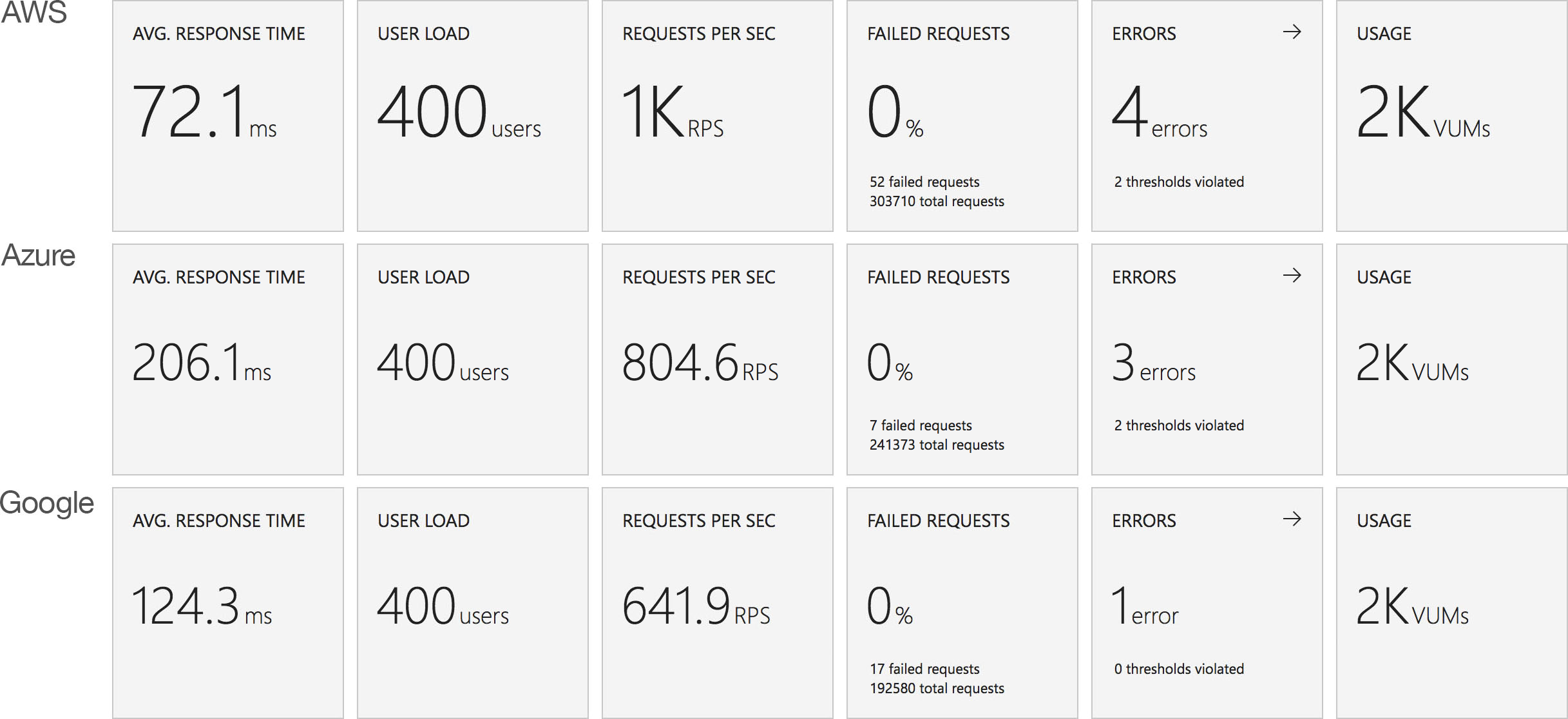
Again we see very much the same pattern – AWS Lambda is the clear leader in both response time and throughput while 2nd place for response time goes to Google and 2nd place for throughput goes to Azure.
Stock Functions
Interestingly in this comparison of stock functions (returning a string and so very isolated) we can see that Azure Functions has drawn extremely close to AWS Lambda and ahead of Google Cloud which really is an impressive improvement.
This suggests that other factors are now playing a proportionally bigger factor in the scaling tests than Functions capability to scale – previously this was clearly driving the results. Additional tests would need to be run to isolate if this is the case and whether or not this is related to the IO capabilities of the Functions host or the capabilities of external dependencies.
Percentile Performance
The percentile comparison shows some very interesting differences between the three platforms. At lower percentiles AWS and Google outperform Azure however as we head into the later percentiles they both deteriorate while Azure deteriorates more gradually with the exception of the worst case response time.
Across the graph Azure gives a more generally even performance suggesting that if consistent performance across a broader percentile range is more important than outright response time speed it may be a better choice for you.
Enabling The Improvements
The improvements I’ve measured and highlighted here are not yet enabled by default, but will be with the next release. In the meantime you can give them a go by adding an App Setting with the name WEBSITE_HTTPSCALEV2_ENABLED to 1.
Conclusions
In my view the Azure Functions team have done some impressive work in a fairly short space of time to transform the performance of Azure Functions triggered by HTTP requests. Previously the poor performance made them difficult to recommend except in a very limited range of scenarios but the work the team have done has really opened this up and made this a viable platform for many more scenarios. Performance is much more predictable and the system scales quickly to deal with demand – this is much more in line with what I’d hoped for from the platform.
I was sceptical about how much progress was possible without significant re-architecture but, as an Azure customer and someone who wants great experiences for developers (myself included), I’m very happy to have been wrong.
In the real world representative tests there is still a significant response time gap for HTTP triggered compute between Azure Functions and AWS Lambda however it is not clear from these tests alone if this is related to Functions or other Azure components. Time allowing I will investigate this further.
Finally my thanks to the @azurefunctions team, @jeffhollan and @davidebbo both for their work on improving Azure Functions but also for the ongoing dialogue we’ve had around serverless on Azure – it’s great to see a team so focused on developer experience and transparent about the platform.
If you want to discuss my findings or tech in general then I can be found on Twitter: @azuretrenches.
Since I published this piece Microsoft have made significant improvements to HTTP scaling on Azure Functions and the below is out of date. Please see this post for a revised comparison.
Following the analysis I published on Azure Functions and the latency in scaling HTTP triggered functions the Microsoft development team got in touch to discuss my findings and provide some information about the future which they were happy for me to share.
Essentially the team are already at work making improvements in this area. Understandably they were unable to commit to timescales or make specific claims as to how significant those improvements but my sense is we’re looking at a handful of months and so, hopefully, half one of this year. They are going to get in touch with me once something is available and I’ll rerun my tests.
I must admit I’m slightly sceptical as to if they’ll be able to match the scaling capability of AWS Lambda (and to be clear they did not make any such claim), which is what I’d like to see, as that looks to me as if it would require a radical uprooting of the Functions runtime model rather than an evolution but ultimately I’m just a random, slightly informed, punter. Hopefully they can at least get close enough that Azure Functions can be used in more latency critical and spiky scenarios.
I’d like to thank @jeffhollan and the team for the call – as a predominantly Azure and .NET developer it’s both helpful and encouraging to be able to have these kinds of dialogues around the platform so critical to our success.
In the interim I’m still finding I can use HTTP functions – I just have to be mindful of their current limitations – and have some upcoming blog posts on patterns that make use of them.
After my last few posts on the scaling of Azure Functions I was intrigued to see if they would perform any better running on a dedicated App Service Plan. Hosting them in this way allows for the functions to take full advantage of App Service features but, to my mind, is no long a serverless approach as rather than being billed based on usage you are essentially renting servers and are fully responsible for scaling.
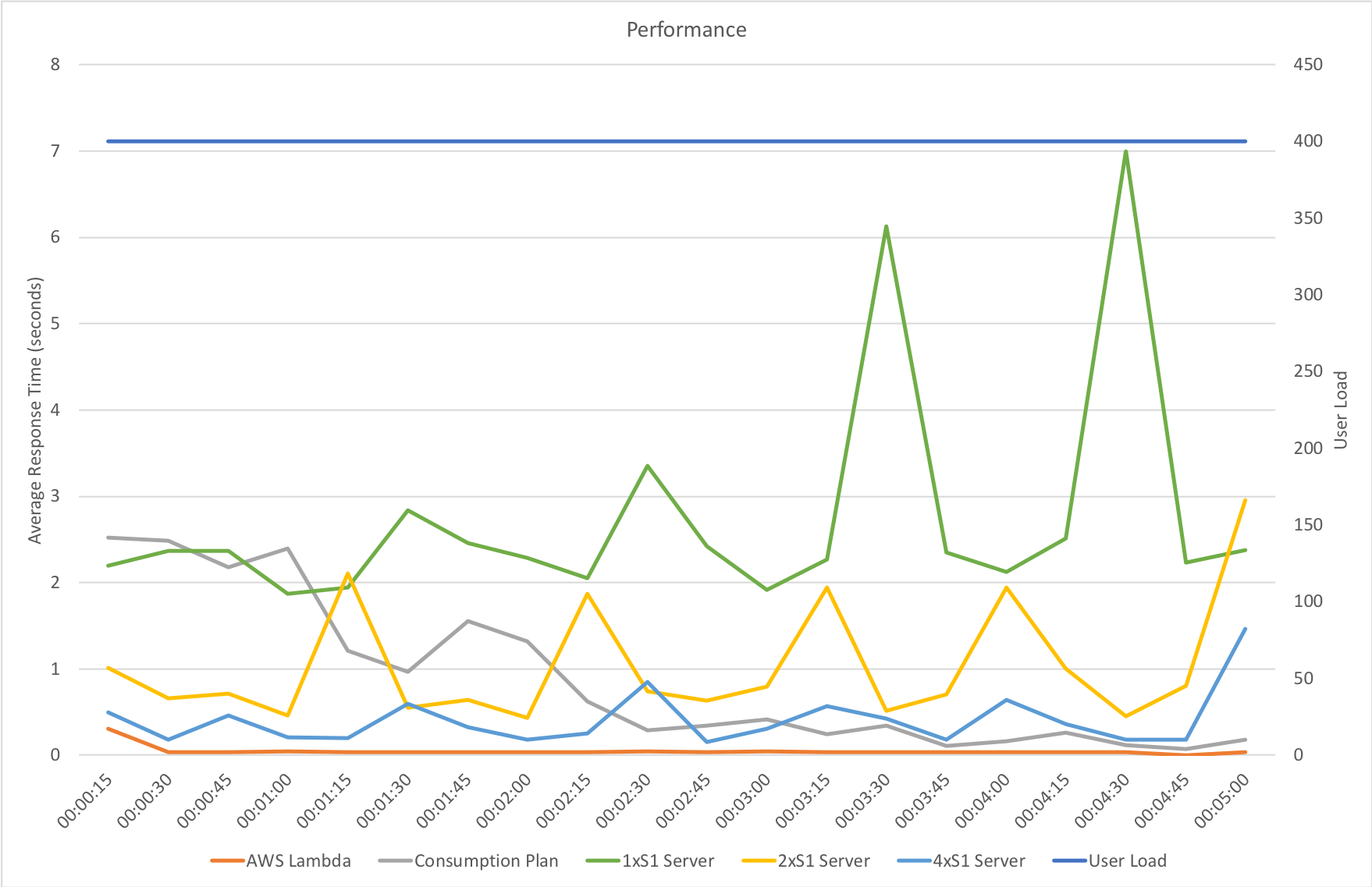
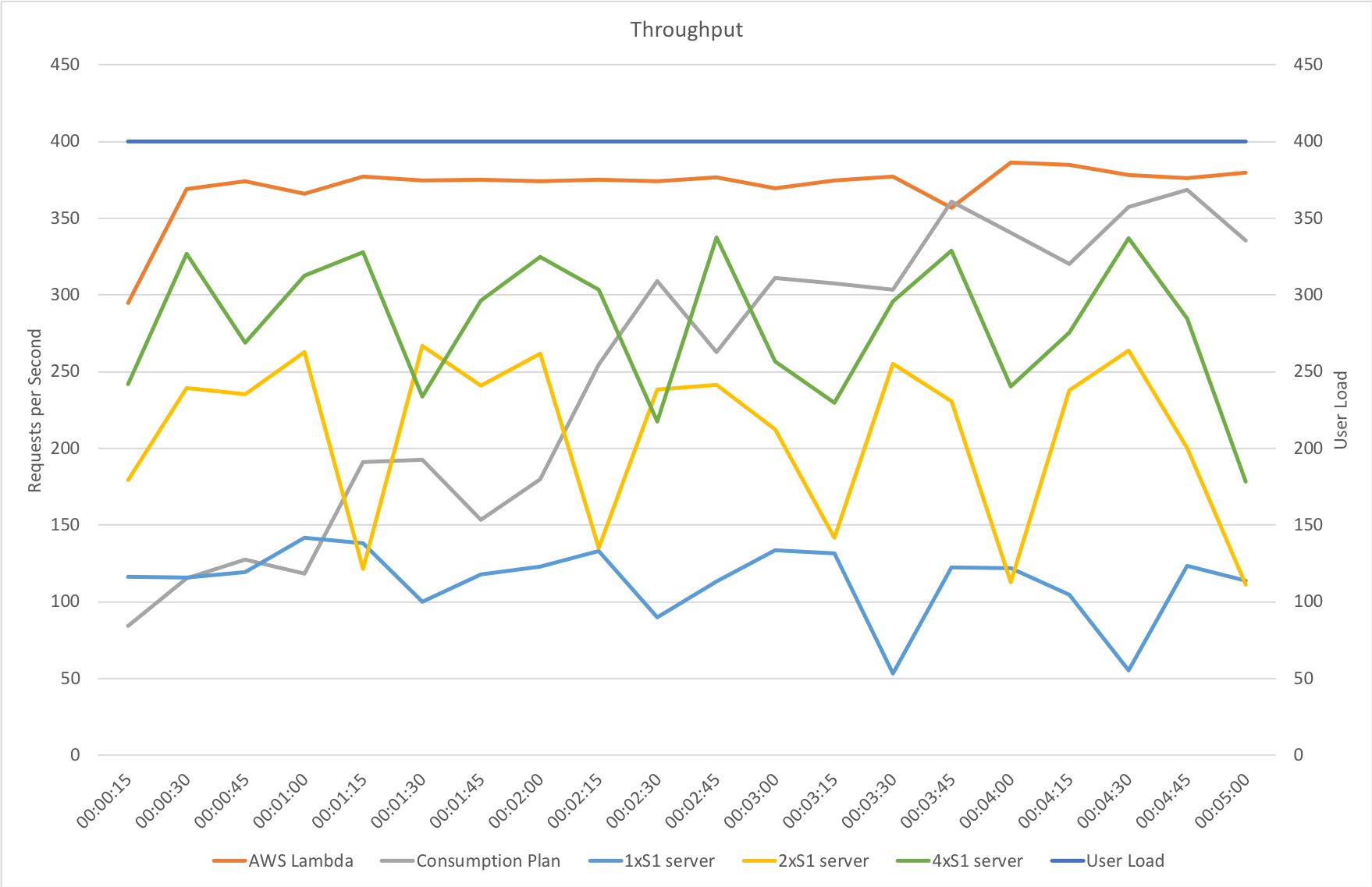
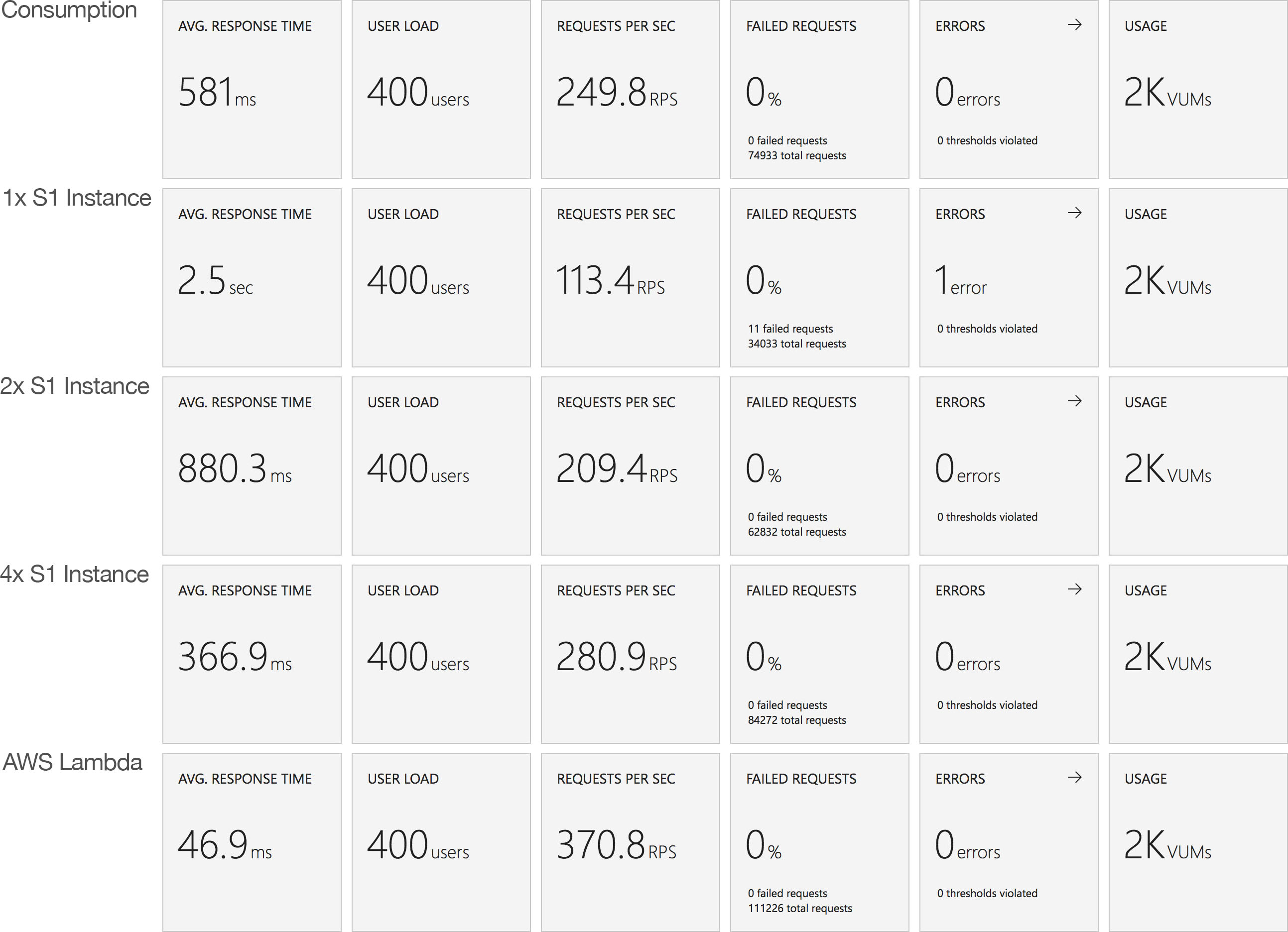
I conducted a single test scenario: an immediate load of 400 concurrent users running for 5 minutes against the “stock” JavaScript function (no external dependencies, just returns a string) on 4 configurations:
Consumption Plan – billed based on usage – approximately $130 per month (based on running constantly at the tested throughput that is around 648 million functions per month)
Dedicated App Service Plan with 1 x S1 server -$73.20 per month
Dedicated App Service Plan with 2 x S1 server – $146.40 per month
Dedicated App Service Plan with 4 x S1 server – $292.80 per month
I also included AWS Lambda as a reference point.
The results were certainly interesting:
With immediately available resource all 3 App Service Plan configurations begin with response times slightly ahead of the Consumption Plan but at around the 1 minute mark the Consumption Plan overtakes our single instance configuration and at 2 minutes creeps ahead of the double instance configuration and, while the advantage is slight, at 3 minutes begins to consistently outperform our 4 instance configuration. However AWS Lambda remains some way out in front.
From a throughput perspective the story is largely the same with the Consumption Plan taking time to scale up and address the demand but ultimately proving more capable than even the 4x S1 instance configuration and knocking on the door of AWS Lambda. What I did find particularly notable is the low impact of moving from 2 to 4 instances on throughput – the improvement in throughput is massively disappointing – for incurring twice the cost we are barely getting 50% more throughput. I have insufficient data to understand why this is happening but do have some tests in mind that, time allowing, I will run and see if I can provide further information.
At this kind of load (650 million requests per month) from a bang per buck point of view Azure Functions on the Consumption Plan come out strongly compared to App Service instances even if we don’t allowing for quiet periods when Functions would incur less cost. If your scale profile falls within the capabilities of the service it’s worth considering though it’s worth remembering their isn’t really an SLA around Functions at the moment when running on the Consumption Plan (and to be fair the same applies to AWS Lambda).
If you don’t want to take advantage of any of the additional features that come with a dedicated App Service plan and although they can be provisioned to avoid the slow ramp up of the Consumption Plan are expensive in comparison.
Contact
If you're looking for help with C#, .NET, Azure, Architecture, or would simply value an independent opinion then please get in touch here or over on Twitter.







Recent Comments