If you're looking for help with C#, .NET, Azure, Architecture, or would simply value an independent opinion then please get in touch here or over on Twitter.
One of the major selling points for Microsoft’s Azure Cosmos DB is that its a multi-model database – you can use it as a:
- Simple key/value pair store through the Table API
- Document database through the SQL API
- Graph database through the Graph (Gremlin) API
- MongoDB database
- Cassandra database
Underneath these APIs Cosmos uses it’s Atom-Record-Sequence (ARS) type system to manage and store the data which has the less well publicized benefit of allowing you to use different APIs to access the same data.
While I’ve not explored all the possibilities I’d like to demonstrate the potential that this approach opens up by running geo-spatial queries (longitude and latitude based) against a Graph database that is primarily used to model social network relationships.
Lets assume you’re building a social network to connect individuals in local communities and you’re using a graph database to connect people together. In this graph you have vertexes of type ‘person’ and edges of type ‘follows’ and when someone new joins your network you want to suggest people to them who live within a certain radius of their location (a longitude and latitude derived from a GPS or geocoded address). In this example we’re going to do this by constructing the graph based around social connections using Gremlin .NET and using the geospatial queries available to the SQL API (we’ll use SP_DISTANCE) to interrogate it based on location.
Given a person ID, longitude and latitude firstly lets look at how we add someone into the graph (this assumes you’ve added the Gremlin .NET package to your solution):
public Task CreateNode(string personId)
{
const string cosmosEndpoint = "yourcosmosdb.gremlin.cosmosdb.azure.com";
string username = $"/dbs/yoursocialnetwork/colls/relationshipcollection"; // the form of /dbs/DATABASE/colls/COLLECTION
const string cosmosAuthKey = "yourauthkey";
GremlinServer gremlinServer = new GremlinServer(cosmosEndpoint, 443, true, username, cosmosAuthKey);
using (GremlinClient client = new GremlinClient(gremlinServer, new GraphSON2Reader(),
new GraphSON2Writer(), GremlinClient.GraphSON2MimeType))
{
Dictionary<string, object> arguments = new Dictionary<string, object>
{
{"personId", personId}
};
await client.SubmitAsync("g.addV('person').property('id', personId)", arguments);
}
}
If you run this code against a Cosmos DB Graph collection it will create a vertex with the label of person and assign it the specified id.
We’ve not yet got any location data attached to this vertex and that’s because Gremlin.NET and Cosmos do not (to the best of my knowledge) allow us to set a property with the specific structure required by the geospatial queries supported by SQL API. That being the case we’re going to use the SQL API to load this vertex as a document and attach a longitude and latitude. The key to this is to use the document endpoint. If you look in the code above you can see we have a Gremlin endpoint of:
yourcosmosdb.gremlin.cosmosdb.azure.com
If you attempt to run SQL API queries against that endpoint you’ll encounter errors, the endpoint we need to use is:
yourcosmosdb.documents.azure.com
To keep things simple we’ll use the LINQ support provided by the DocumentDB client but rather than define a class that represents the document we’ll use a dictionary of strings and objects. In the multi-model world we have to be very careful not to lose properties required by the other model and by taking this approach we don’t need to inspect and carefully account for each property (and ongoing change!). If we don’t do this we are liable to lose data at some point.
All that being the case we can attach our location property using code like the below:
public static async Task AddLocationToDocument(this DocumentClient documentClient, Uri documentCollectionUri, string id, double longitude, double latitude)
{
DocumentClient documentClient = new DocumentClient(new Uri("https://yourcosmosdb.documents.azure.com"));
Uri collectionUri = UriFactory.CreateDocumentCollectionUri("db","coll");
IQueryable<Dictionary<string,object>> documentQuery = documentClient.CreateDocumentQuery<Dictionary<string,object>>(
collectionUri ,
new FeedOptions { MaxItemCount = 1 })
.Where(x => (string)x["id"] == id);
PersonDocument document = documentQuery.ToArray().SingleOrDefault();
document["location"] = new Point(longitude, latitude);
Uri documentUri = UriFactory.CreateDocumentUri(
Constants.Storage.Cosmos.Database,
Constants.Storage.Cosmos.RelationshipsCollection,
id);
await documentClient.ReplaceDocumentAsync(documentUri, document);
}
If you were now to inspect this vertex in the Azure portal you won’t see the Location property in the graph explorer – its property format is not one known to Gremlin:
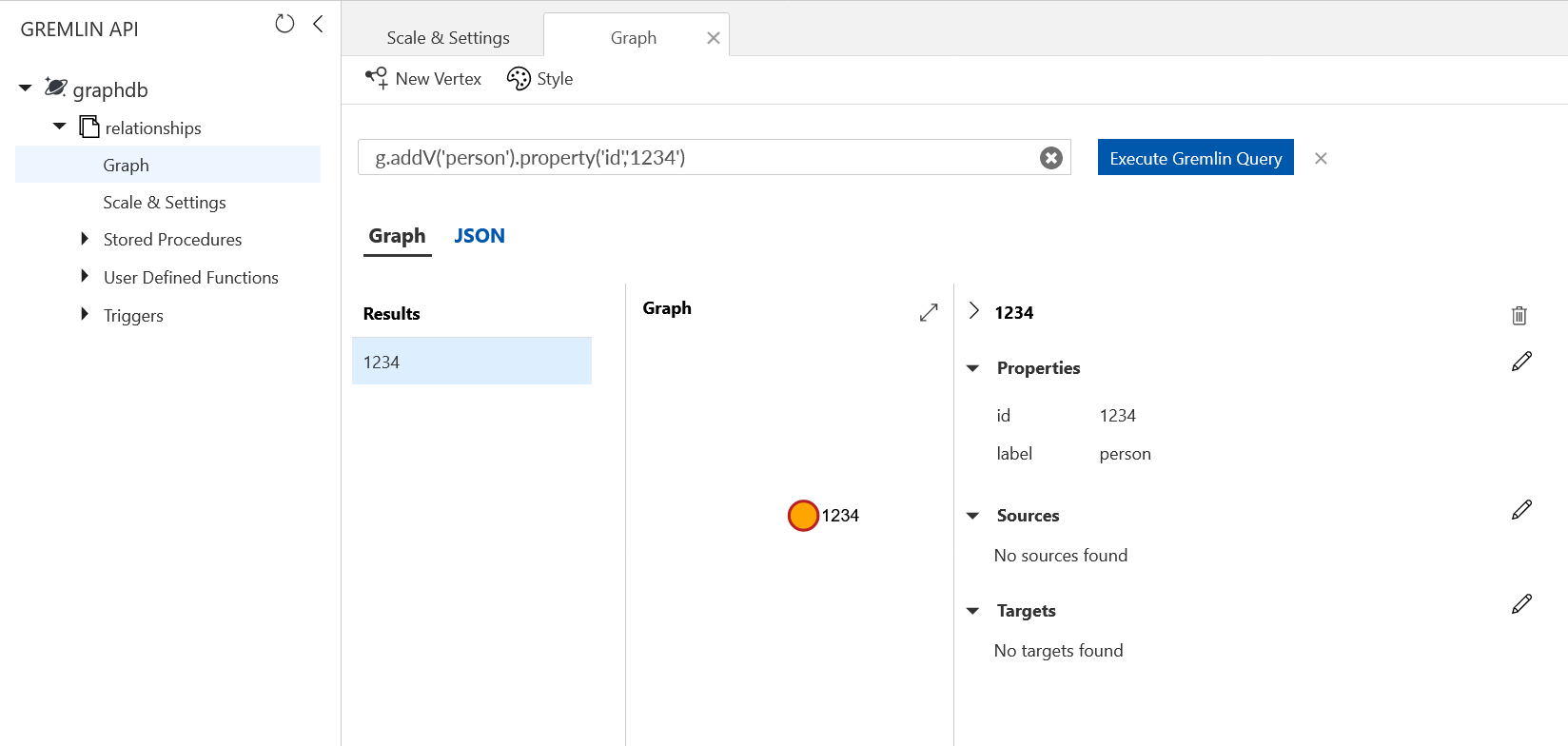
However if you open the collection in Azure Storage Explorer (another example of multi-model usage) you will see the vertexes (and edges) exposed as documents and will see the location attached in the JSON:
{
"location": {
"type": "Point",
"coordinates": [
-6.45436,
49.12892
]
},
"id": "1234",
"label": "person",
"_rid": "...",
"_self": "...",
"_etag": "\"...\"",
"_attachments": "attachments/",
"_ts": ...
}
Ok. So at this point we’ve got a person in our social network graph. Lets imagine we’re about to add another person and we want to search for nearby people. We’ll do this using a SQL API query to find people within 30km of a given location (I’ve stripped out some of the boilerplate from this):
const double rangeInMeters = 30000;
IQueryable<Dictionary<string,object>> query = _documentClient.Value.CreateDocumentQuery<Dictionary<string, object>>(
collectionUri,
new FeedOptions { MaxItemCount = 1000 })
.Where(x => (string)x["label"] == "person" &&
((Point)x["location"]).Distance(new Point(location.Longitude, location.Latitude)) < rangeInMeters);
var inRange = query.ToArray();
From here we can iterate our inRange array and build a Gremlin query to attach our edges roughly of the form:
g.V('1234').addE('follows').to(g.V('5678'))
Closing Thoughts
Being able to use multiple models to query the same data brings a lot of expressive power to Cosmos DB though it’s still important to choose the model that best represents the primary workload for your data and understand how the different queries behave in respect to RUs and data volumes.
It’s also a little clunky working in the two models and its quite easy, particularly if performing updates, to break things. I expect as Cosmos becomes more mature that this is going to be cleaned up and I think Microsoft will talk about these capabilities more.
Finally – its worth opening up a graph database with Azure Storage Explorer and inspecting the documents, you can see how Cosmos manages vertexes and edges and it gives a more informed view as to how graph queries consume RUs.

Recent Comments